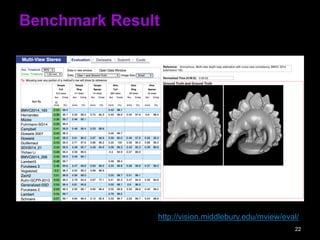
Multi-View Stereo Algorithmサーベイ
• A Comparison and Evaluation of Multi-View
Stereo Reconstruction Algorithm
– CVPR 2006
– Authors :
• Steven M. Seitz
• Brain Curless
• James Diebel
• Daniel Scharstein
• Richard Szeliski
• 各種アルゴリズムの分類
• 復元性能のベンチマーク・ランキング
8
Photo-consistency measure
• Scenespace
– シーン中の点を各カメラに投影しPhoto-
consistencyを計算
– Photo-consistencyはSSDやNCCで計算するこ
とが一般的
15
538 Computer Vision: Algorithms and Applications (Septemb
p
x1
x0
(R,t)
p∞
e1e0c0 c1
epipolar plane
p
(R,t)
c0
epipolar
lines
x
0
e0 e1
l0
16.
Photo-consistency measure
• Imagespace
– カメラ画像をシーンに投影してPhoto-
consistencyを計算
16
11.1 Epipolar geometry 541
Virtual camera
d
x
y
Input image k
u
v
Homography:
u = H x
x
y
k
d
k
(a) (b)
Initialization requirements
• 初期化の要件
– RoughBounding Box or Volume
• Space carving
• Level-set (質の高い初期値が必要)
– Foreground/background segmentation
• silhouette
– Range of disparity or depth values
• Image-space algorithm
20
21.
Benchmark Datasets
21
bird dogs
lti-viewdatasets with laser-scanned 3D models.
317 camera positions and orientations for the temple
gaps are due to shadows. The 47 cameras correspond-
g dataset are shown in blue and red, and the 16 sparse
only in red.
at serves as an initial estimate of scene geom-
31,47,48].
tion of 640 × 480 pixels att
arm. At this resolution, a pix
0.25mm on the surface of th
10cm × 16cm × 8cm, and th
The system was calibrated
tion grid from 68 viewpoints
[61] to compute intrinsic an
these parameters, we compu
and rotational offset relative t
abling us to determine the cam
as a function of any desired a
The target object sits on
center of the gantry sphere an
lights. Because the gantry c
certain viewpoints, we double
two different arm configurat
images. After shadowed im
we obtained roughly 80% cov
resulting images, we created
corresponding to a full hemis
temple temple model
temple
dino
カメラ配置 47視点
カメラ解像度 640x480
Temple
10x16x8 cm
Dino
7x9x7 cm
最先端のMVS研究例
• "Towards Internet-scaleMulti-view Stereo "
– CVPR 2010
– 法線付きの点群として3次元復元
– 大規模MVS
26
cale Multi-view Stereo
Steven M. Seitz1,2
Richard Szeliski3
Washington 3
Microsoft Research
Figure 1. Our dense reconstruction of Piazza San Marco (Venice)
Pizza San Marco
(Venice)
視点数 : 13,703
点群数 : 27,707,825





















![Benchmark Datasets
21
bird dogs
lti-view datasets with laser-scanned 3D models.
317 camera positions and orientations for the temple
gaps are due to shadows. The 47 cameras correspond-
g dataset are shown in blue and red, and the 16 sparse
only in red.
at serves as an initial estimate of scene geom-
31,47,48].
tion of 640 × 480 pixels att
arm. At this resolution, a pix
0.25mm on the surface of th
10cm × 16cm × 8cm, and th
The system was calibrated
tion grid from 68 viewpoints
[61] to compute intrinsic an
these parameters, we compu
and rotational offset relative t
abling us to determine the cam
as a function of any desired a
The target object sits on
center of the gantry sphere an
lights. Because the gantry c
certain viewpoints, we double
two different arm configurat
images. After shadowed im
we obtained roughly 80% cov
resulting images, we created
corresponding to a full hemis
temple temple model
temple
dino
カメラ配置 47視点
カメラ解像度 640x480
Temple
10x16x8 cm
Dino
7x9x7 cm](https://image.slidesharecdn.com/presentation-150327102027-conversion-gate01/85/28th-CV-3-21-320.jpg)

















![SSII2021 [TS1] Visual SLAM ~カメラ幾何の基礎から最近の技術動向まで~](https://cdn.slidesharecdn.com/ss_thumbnails/ts1-01-210607042113-thumbnail.jpg?width=640&height=640&fit=bounds)


![SSII2021 [OS3] 広域環境の3D計測と認識 ~ 人が活動する場のセンシングとモデル化 ~(オーガナイザーによる冒頭の導入)](https://cdn.slidesharecdn.com/ss_thumbnails/os3-01-210605061816-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]VoxelPose: Towards Multi-Camera 3D Human Pose Estimation in Wild Envir...](https://cdn.slidesharecdn.com/ss_thumbnails/20201023voxelposekuboshizuma-201023025841-thumbnail.jpg?width=640&height=640&fit=bounds)




















![SSII2020 [O3-01] Extreme 3D センシング](https://cdn.slidesharecdn.com/ss_thumbnails/200612-ssii-extreme3dsensing-print3-200608114658-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Stereo Magnification: Learning view synthesis using multiplane images, +α](https://cdn.slidesharecdn.com/ss_thumbnails/stereomagnification-201002033144-thumbnail.jpg?width=640&height=640&fit=bounds)












