22PCOAM21 Data Quality Session 3 Data Quality.pptx
1.
07/26/2025 1
Department ofComputer Science & Engineering (SB-ET)
III B. Tech -II Semester
DATAANALYTICS
SUBJECT CODE: 22PCOAM21
AcademicYear : 2024-2025
By
Dr.M.Gokilavani
GNITC
Department of CSE (SB-ET)
2.
07/26/2025 Department ofCSE (SB-ET) 2
22PCOAM21 DATAANALYTICS
UNIT – I
Syllabus
Data Management: Design Data Architecture and manage the data for
analysis, understand various sources of Data like Sensors/Signals/GPS etc.
Data Management, Data Quality (noise, outliers, missing values, duplicate
data) and Data Preprocessing &Processing.
Course Prerequisites
1. Database Management Systems.
2. Knowledge of probability and statistics.
3.
07/26/2025 3
TEXTBOOK:
• Student’sHandbook for Associate Analytics - II, III.
• Data Mining Concepts and Techniques, Han, Kamber, 3rd Edition, Morgan Kaufmann
Publishers.
REFERENCES:
• Introduction to Data Mining, Tan, Steinbach and Kumar, Addision Wisley, 2006.
• Data Mining Analysis and Concepts, M. Zaki and W. Meira
• Mining of Massive Datasets, Jure Leskovec Stanford Univ. Anand Rajaraman Milliway Labs,
Jeffrey D Ullman Stanford Univ.
No of Hours Required: 13
Department of CSE (SB-ET)
UNIT - I LECTURE - 03
4.
07/26/2025 Department ofCSE (SB-ET) 4
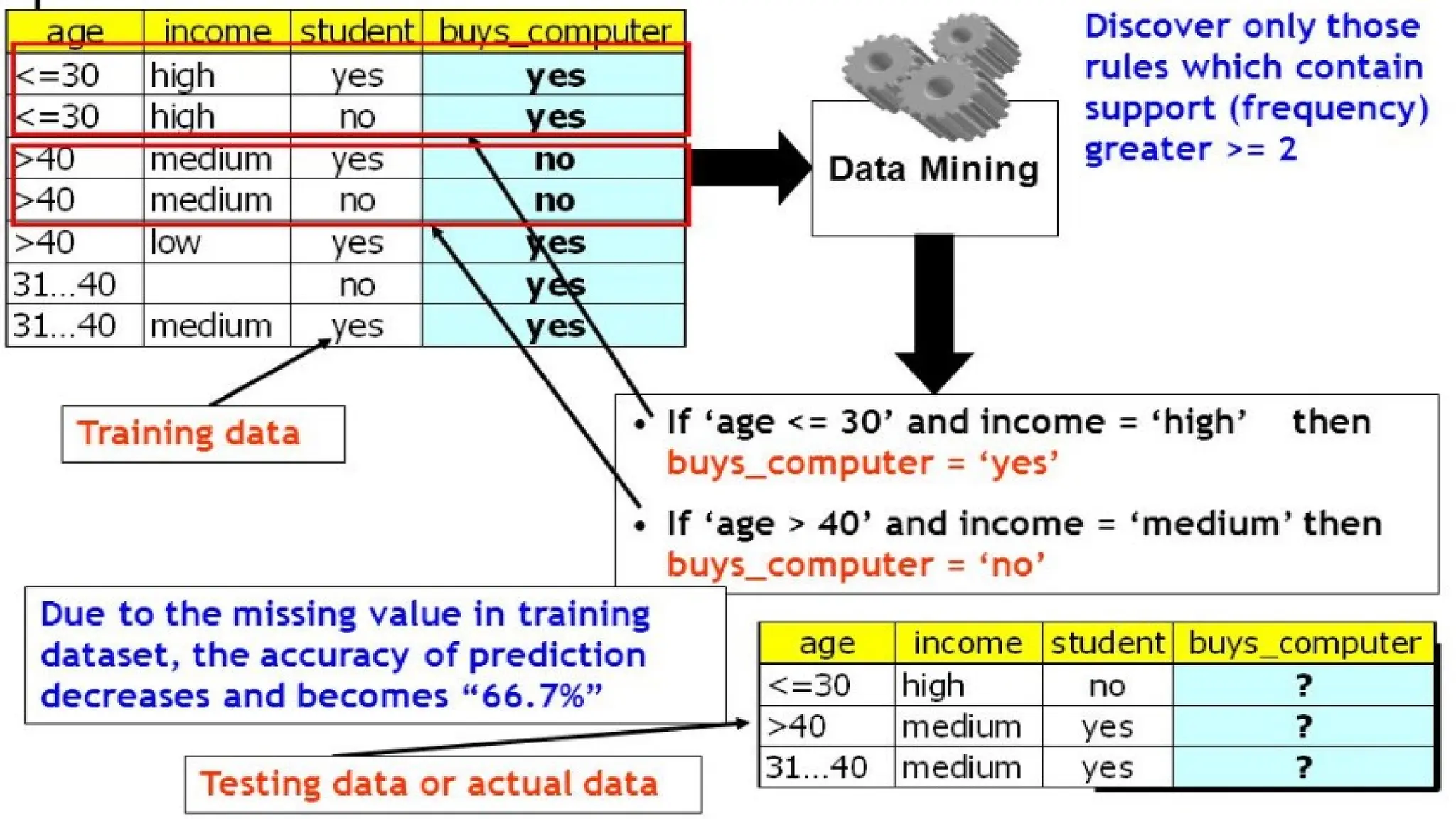
Data Quality
• Missing values imputation using Mean, Median and k-Nearest Neighbor
approach in Distance Measure.
• Data quality issues like
i.Noise
ii.Outliers
iii.Missing values
iv.Duplicate data
can significantly impact data analysis and machine learning models.
• These issues can lead to inaccurate results and flawed insights if not addressed
properly.
UNIT - I LECTURE - 03
5.
07/26/2025 Department ofCSE (SB-ET) 5
Data Quality
• Data cleaning or Preprocessing , a crucial preprocessing step, involves
identifying and correcting these issues to improve data quality.
• Its importance, and the essential procedures for making sure the data we use is
correct, reliable, and appropriate for the reason for which data was collected.
• Data quality is a major concern in Learning tasks model.
• Why: At most all Learning algorithms induce knowledge strictly from data.
• The quality of knowledge extracted highly depends on the quality of data.
• There are two main problems in data quality:-
• Missing data: The data not present.
• Noisy data: The data present but not correct.
UNIT - I LECTURE - 03
7.
07/26/2025 Department ofCSE (SB-ET) 7
Noise
UNIT - I LECTURE - 03
• It refers to irrelevant or incorrect data that is difficult for machines to
interpret, often caused by errors in data collection or entry.
• It can be handled in several ways:
i. Binning Method: The data is sorted into equal segments, and each
segment is smoothed by replacing values with the
mean or boundary values.
ii. Regression: Data can be smoothed by fitting it to a regression
function, either linear or multiple, to predict values.
iii. Clustering: This method groups similar data points together, with
outliers either being undetected or falling outside the
clusters. These techniques help remove noise and
improve data quality.
07/26/2025 Department ofCSE (SB-ET) 9
Outliers
UNIT - I LECTURE - 03
• Outlier is a data point that stands out a lot from the other data points
in a set.
• An outlier is a data point that significantly deviates from the rest of the
data.
• It can be either much higher or much lower than the other data points,
and its presence can have a significant impact on the results of
machine learning algorithms.
• They can be caused by measurement or execution errors.
• The analysis of outlier data is referred to as outlier analysis.
10.
07/26/2025 Department ofCSE (SB-ET) 10
Types of Outliers
There are two main types of outliers:
i. Global outliers:
• Global outliers are isolated data points that are far away from the main body
of the data.
• They are often easy to identify and remove.
ii. Contextual outliers:
• Contextual outliers are data points that are unusual in a specific context but
may not be outliers in a different context.
• They are often more difficult to identify and may require additional
information or domain knowledge to determine their significance.
UNIT - I LECTURE - 03
11.
07/26/2025 Department ofCSE (SB-ET) 11
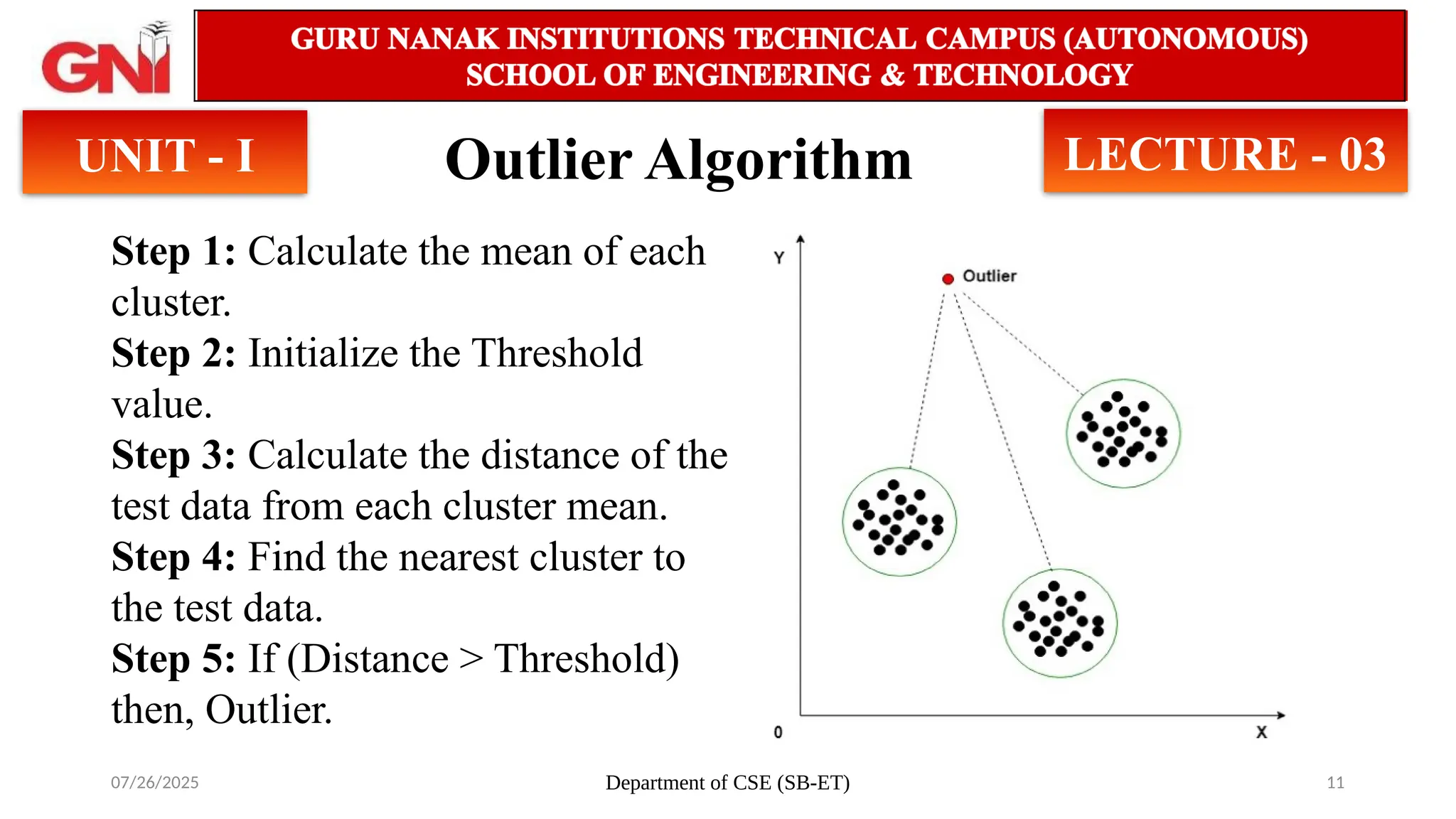
Outlier Algorithm
UNIT - I LECTURE - 03
Step 1: Calculate the mean of each
cluster.
Step 2: Initialize the Threshold
value.
Step 3: Calculate the distance of the
test data from each cluster mean.
Step 4: Find the nearest cluster to
the test data.
Step 5: If (Distance > Threshold)
then, Outlier.
12.
07/26/2025 Department ofCSE (SB-ET) 12
Outlier Detection Methods
• Outlier detection plays a crucial role in ensuring the quality and accuracy of machine learning models.
• By identifying and removing or handling outliers effectively, we can prevent them from biasing the
model, reducing its performance, and hindering its interpretability.
• Here's an overview of various outlier detection methods:
• Statistical Methods
• Z-Score
• Interquartile Range (IQR)
• Distance-Based Methods
• K-Nearest Neighbors (KNN)
• Local Outlier Factor (LOF)
• Clustering-Based Methods
• Density-Based Spatial Clustering of Applications with Noise (DBSCAN)
• Hierarchical clustering
• Other Methods
• Isolation Forest
• One-class Support Vector Machines (OCSVM)
UNIT - I LECTURE - 03
13.
07/26/2025 Department ofCSE (SB-ET) 13
Statistical & Distance based Methods
UNIT - I LECTURE - 03
•Z-Score: This method calculates the standard deviation of the data points and identifies
outliers as those with Z-scores exceeding a certain threshold (typically 3 or -3).
•Interquartile Range (IQR): IQR identifies outliers as data points falling outside the range
defined by
• Q1-k*(Q3-Q1) and Q3+k*(Q3-Q1),
• where Q1 and Q3 are the first and third quartiles, and k is a factor (typically
1.5).
Distance-Based Methods
• K-Nearest Neighbors (KNN): KNN identifies outliers as data points whose K nearest
neighbors are far away from them.
• Local Outlier Factor (LOF): This method calculates the local density of data points and
identifies outliers as those with significantly lower density compared to their neighbors.
14.
07/26/2025 Department ofCSE (SB-ET) 14
Clustering-Based Methods
UNIT - I LECTURE - 03
• Density-Based Spatial Clustering of Applications with Noise
(DBSCAN): In DBSCAN, clusters data points based on their density and identifies
outliers as points not belonging to any cluster.
• Hierarchical clustering: Hierarchical clustering involves building a hierarchy of
clusters by iteratively merging or splitting clusters based on their similarity. Outliers
can be identified as clusters containing only a single data point or clusters significantly
smaller than others.
Other Methods:
•Isolation Forest: Isolation forest randomly isolates data points by splitting
features and identifies outliers as those isolated quickly and easily.
•One-class Support Vector Machines (OCSVM): One-Class SVM learns a
boundary around the normal data and identifies outliers as points falling outside
the boundary.
15.
07/26/2025 Department ofCSE (SB-ET) 15
Techniques for Handling Outliers
1. Removal:
• This involves identifying and removing outliers from the dataset before training
the model. Common methods include:
• Thresholding: Outliers are identified as data points exceeding a certain
threshold (e.g., Z-score > 3).
• Distance-based methods: Outliers are identified based on their
distance from their nearest neighbors.
• Clustering: Outliers are identified as points not belonging to any
cluster or belonging to very small clusters.
UNIT - I LECTURE - 03
16.
07/26/2025 Department ofCSE (SB-ET) 16
Techniques for Handling Outliers
2. Transformation:
• This involves transforming the data to reduce the influence of
outliers. Common methods include:
• Scaling: Standardizing or normalizing the data to have a mean of zero
and a standard deviation of one.
• Winsorization: Replacing outlier values with the nearest non-outlier
value.
• Log transformation: Applying a logarithmic transformation to
compress the data and reduce the impact of extreme values.
UNIT - I LECTURE - 03
17.
07/26/2025 Department ofCSE (SB-ET) 17
Techniques for Handling Outliers
3. Robust Estimation:
• This involves using algorithms that are less sensitive to outliers. Some examples
include:
• Robust regression: Algorithms like L1-regularized regression or Huber
regression are less influenced by outliers than least squares regression.
• M-estimators: These algorithms estimate the model parameters based on a
robust objective function that down weights the influence of outliers.
• Outlier-insensitive clustering algorithms: Algorithms like DBSCAN are
less susceptible to the presence of outliers than K-means clustering.
UNIT - I LECTURE - 03
18.
07/26/2025 Department ofCSE (SB-ET) 18
Techniques for Handling Outliers
4. Modeling Outliers:
• This involves explicitly modeling the outliers as a separate group. This can be done
by:
• Adding a separate feature: Create a new feature indicating whether a data
point is an outlier or not.
• Using a mixture model: Train a model that assumes the data comes from a
mixture of multiple distributions, where one distribution represents the
outliers.
UNIT - I LECTURE - 03
19.
07/26/2025 Department ofCSE (SB-ET) 19
Importance of outlier detection
• Biased models
• Reduced accuracy
• Increased variance
• Reduced interpretability
UNIT - I LECTURE - 03
20.
07/26/2025 Department ofCSE (SB-ET) 20
Imputations of Missing Values
• Imputation is a term that denotes a procedure that replaces the missing values in
a dataset by some plausible values.
• i.e. by considering relationship among correlated values among the
attributes of the dataset.
UNIT - I LECTURE - 03
21.
07/26/2025 Department ofCSE (SB-ET) 21
Topics to be covered in next session 4
• DataManagement
Thank you!!!
UNIT - I LECTURE - 03