22PCOAM16 Unit 3 Session 22 Ensemble Learning .pptx
1.
14/05/2025 1
Department ofComputer Science & Engineering (SB-ET)
III B. Tech -I Semester
MACHINE LEARNING
SUBJECT CODE: 22PCOAM16
AcademicY
ear: 2024-2025
by
Dr. M.Gokilavani
GNITC
Department of CSE (SB-ET)
2.
14/05/2025 Department ofCSE (SB-ET) 2
22PCOAM16 MACHINE LEARNING
UNIT – III
Syllabus
Learning with Trees – Decision Trees – Constructing Decision Trees –
Classification and Regression Trees – Ensemble Learning – Boosting –
Bagging – Different ways to Combine Classifiers – Basic Statistics –
Gaussian Mixture Models – Nearest Neighbor Methods – Unsupervised
Learning – K means Algorithms
3.
14/05/2025 3
TEXTBOOK:
• StephenMarsland, Machine Learning - An Algorithmic Perspective, Second Edition,
Chapman and Hall/CRC.
• Machine Learning and Pattern Recognition Series, 2014.
REFERENCES:
• Tom M Mitchell, Machine Learning, First Edition, McGraw Hill Education, 2013.
• Ethem Alpaydin, Introduction to Machine Learning 3e (Adaptive Computation and
Machine
No of Hours Required: 13
Department of CSE (SB-ET)
UNIT - III LECTURE - 22
4.
14/05/2025 Department ofCSE (SB-ET) 4
Ensemble Learning
• Ensemble learning is a technique in machine learning that
combines the predictions from multiple individual models to
achieve better predictive performance than any single model
alone.
• The fundamental idea is to leverage the strengths and compensate
for the weaknesses of various models by aggregating their
predictions.
UNIT - III LECTURE - 22
5.
14/05/2025 Department ofCSE (SB-ET) 5
Types of Ensemble Learning
There are two main types of ensemble methods:
• Bagging (Bootstrap Aggregating): Models are trained
independently on different subsets of the data, and their results
are averaged or voted on.
• Boosting: Models are trained sequentially, with each one
learning from the mistakes of the previous model.
UNIT - III LECTURE - 22
6.
14/05/2025 Department ofCSE (SB-ET) 6
Bagging Algorithm
• Bootstrap aggregating also known as bagging, is a machine
learning ensemble dataset designed to improve the stability and
accuracy of machine learning algorithms used in statistical
classification and regression.
• It decreases the variance and helps to avoid over fitting.
• It is usually applied to decision tree methods.
• Bagging is a special case of the model averaging approach.
UNIT - III LECTURE - 22
7.
14/05/2025 Department ofCSE (SB-ET) 7
Description of the Technique
• Suppose a set D of d tuples, at each iteration ith, a training set
Di of d tuples is selected via row sampling with a replacement
method (i.e., there can be repetitive elements from different d
tuples) from D (i.e., bootstrap).
• Then a classifier model Mi is learned for each training set D < i.
• Each classifier Mi returns its class prediction.
• The bagged classifier M* counts the votes and assigns the class
with the most votes to X (unknown sample).
UNIT - III LECTURE - 22
8.
14/05/2025 Department ofCSE (SB-ET) 8
Implementation of Bagging
• Step 1: Multiple subsets are created from the original data set with equal
tuples, selecting observations with replacement.
• Step 2: A base model is created on each of these subsets.
• Step 3: Each model is learned in parallel with each training set and
independent of each other.
• Step 4: The final predictions are determined by combining the predictions
from all the models.
UNIT - III LECTURE - 22
14/05/2025 Department ofCSE (SB-ET) 11
Bagging Classifier
• Bagging or Bootstrap aggregating is a type of ensemble learning in which
multiple base models are trained independently and parallel on different
subsets of training data.
• In bagging classifier, the final prediction is made by aggregating the
predictions of all base model using majority voting.
• In the models of regression the final prediction is made by averaging the
predictions of the all base model and that is known as bagging regression.
UNIT - III LECTURE - 22
12.
14/05/2025 Department ofCSE (SB-ET) 12
Bootstrap Method
• Bootstrap Method is a powerful statistical technique widely used in
mathematics for estimating the distribution of a statistic by resampling
with replacement from the original data.
• The bootstrap method is a resampling technique that allows you to
estimate the properties of an estimator (such as its variance or bias) by
repeatedly drawing samples from the original data.
• It was introduced by Bradley Efron in 1979 and has since become a widely
used tool in statistical inference.
• The bootstrap method is useful in situations where the theoretical sampling
distribution of a statistic is unknown or difficult to derive analytically.
UNIT - III LECTURE - 22
13.
14/05/2025 Department ofCSE (SB-ET) 13
Bootstrap Method
• Bootstrapping is a statistical procedure that resample's a single data set to
create many simulated samples.
• Bootstrap Method or Bootstrapping is a statistical procedure that
resample's a single data set to create many simulated samples.
• This process allows for the, "calculation of standard errors, confidence
intervals, and hypothesis testing” according to a post on bootstrapping
statistics from statistician Jim Frost.
• It can be used to estimate summary statistics such as the mean and standard
deviation.
UNIT - III LECTURE - 22
14.
14/05/2025 Department ofCSE (SB-ET) 14
Bootstrap Method
• Bootstrap Method or Bootstrapping is a statistical technique for estimating an entire
population quantity by averaging estimates from multiple smaller data samples.
UNIT - III LECTURE - 22
15.
14/05/2025 Department ofCSE (SB-ET) 15
Implementation of Bootstrap
The procedure can be summarized as follows:
Step 1: Choose the number of bootstrap samples to take.
Step 2: Choose your sample size For each bootstrap sample, draw a
replacement sample of the size you selected.
Step 3: Calculate the statistics for the samples Calculate the average of the
computed sample statistics.
UNIT - III LECTURE - 22
16.
14/05/2025 Department ofCSE (SB-ET) 16
Example
• The Random Forest model uses Bagging, where decision tree models with
higher variance are present.
• It makes random feature selection to grow trees.
• Several random trees make a Random Forest.
UNIT - III LECTURE - 22
17.
14/05/2025 Department ofCSE (SB-ET) 17
Boosting Algorithm
• Boosting is an ensemble modeling technique designed to create a strong
classifier by combining multiple weak classifiers.
• The process involves building models sequentially, where each new model
aims to correct the errors made by the previous ones.
• AdaBoost was the first really successful boosting algorithm developed for
the purpose of binary classification.
• AdaBoost is short for Adaptive Boosting and is a very popular boosting
technique that combines multiple “weak classifiers” into a single “strong
classifier”.
UNIT - III LECTURE - 22
14/05/2025 Department ofCSE (SB-ET) 19
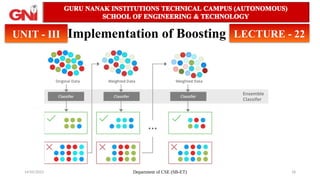
Implementation of Boosting
• Initially, a model is built using the training data.
• Subsequent models are then trained to address the mistakes of their
predecessors.
• boosting assigns weights to the data points in the original dataset.
• Higher weights: Instances that were misclassified by the previous model
receive higher weights.
• Lower weights: Instances that were correctly classified receive lower
weights.
UNIT - III LECTURE - 22
20.
14/05/2025 Department ofCSE (SB-ET) 20
Implementation of Boosting
• Training on weighted data: The subsequent model learns from the
weighted dataset, focusing its attention on harder-to-learn examples (those
with higher weights).
• This iterative process continues until:
• The entire training dataset is accurately predicted, or
• A predefined maximum number of models is reached.
UNIT - III LECTURE - 22
21.
14/05/2025 Department ofCSE (SB-ET) 21
Boosting Algorithm
• Step 1: Initialize the dataset and assign equal weight to each of the data point.
• Step 2: Provide this as input to the model and identify the wrongly classified
data points.
• Step 3: Increase the weight of the wrongly classified data points and decrease
the weights of correctly classified data points. And then normalize the weights of
all data points.
• Step 4: if (got required results)
Goto step 5
else
Goto step 2
• Step 5: End
UNIT - III LECTURE - 22
22.
14/05/2025 Department ofCSE (SB-ET) 22
Advantages of Boosting
• Improved Accuracy: By combining multiple weak learners it enhances
predictive accuracy for both classification and regression tasks.
• Robustness to Over fitting: Unlike traditional models it dynamically
adjusts weights to prevent over fitting.
• Handles Imbalanced Data Well: It prioritizes misclassified points making
it effective for imbalanced datasets.
• Better Interpretability: The sequential nature of helps break down
decision-making making the model more interpretable.
UNIT - III LECTURE - 22
23.
14/05/2025 Department ofCSE (SB-ET) 23
Topics to be covered in next session 23
• Different ways to Combine Classifiers
Thank you!!!
UNIT - III LECTURE - 22