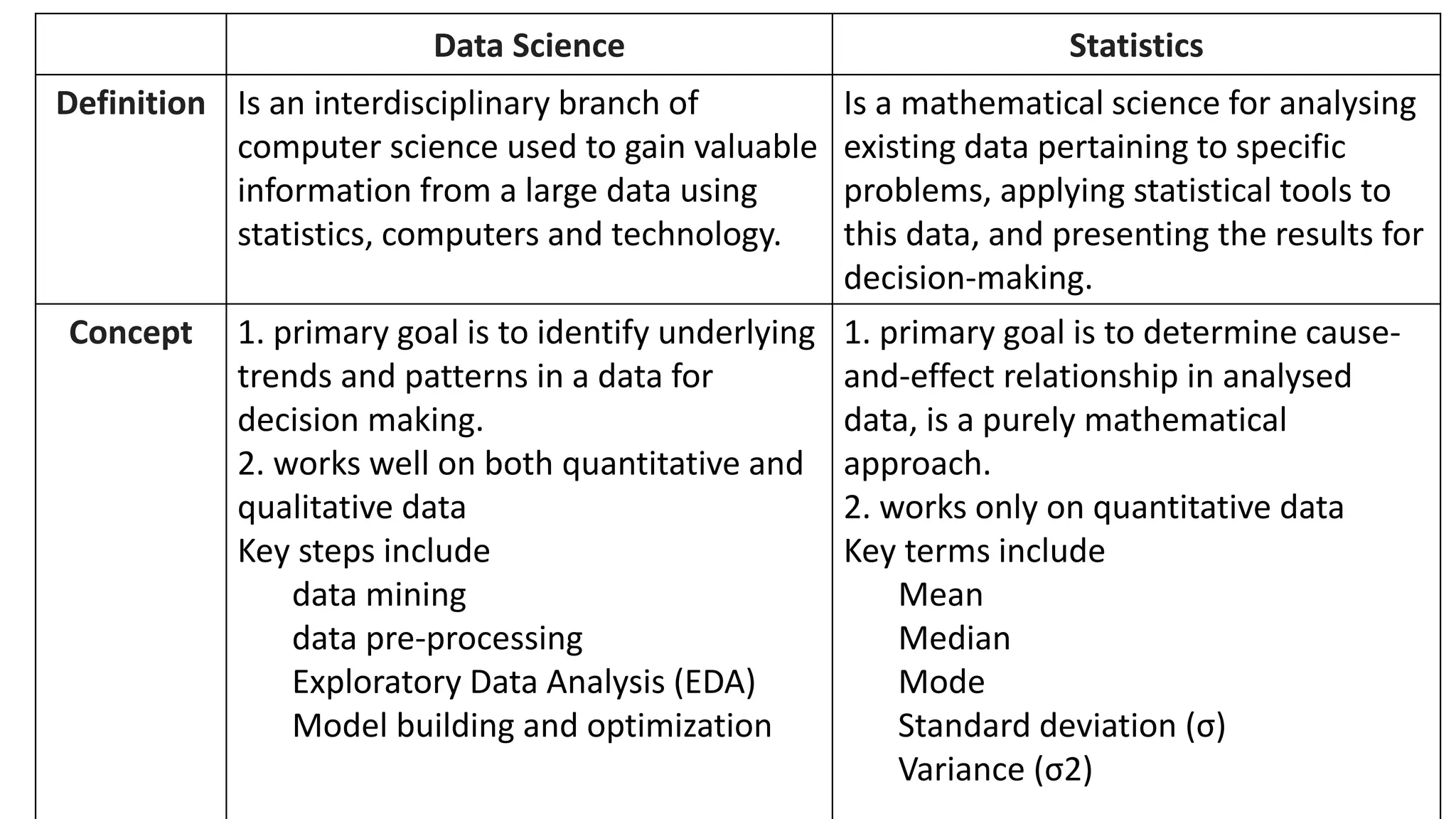
This document discusses various concepts related to data processing and statistics including data collection, cleaning, visualization, and analysis. It covers basic statistical measures like mean, median, mode, variance and standard deviation. It also discusses outlier detection methods using z-scores and interquartile range. Missing data handling techniques include dropping rows, imputing continuous variables with mean/median/mode and categorical variables with most frequent value.











![Replacing with an arbitrary value
If you can make an educated guess about the missing value, then you can
replace it with some arbitrary value using the following code. E.g., in the
following code, we are replacing the missing values of the ‘Dependents’
column with ‘0’.
IN:
#Replace the missing value with '0' using 'fiilna' method
train_df['Dependents'] = train_df['Dependents'].fillna(0)
train_df[‘Dependents'].isnull().sum()
OUT:](https://image.slidesharecdn.com/unit1-240314094133-fd74a320/75/Exploratory-Data-Analysis-Unit-1-ppt-presentation-pptx-13-2048.jpg)







![Identifying Outliers using IQR (Interquartile Range): The IQR is the range between
the first quartile (Q1) and the third quartile (Q3) of the data.
Outliers are often identified as values outside the range [Q1 - 1.5 * IQR, Q3 + 1.5 *
IQR]](https://image.slidesharecdn.com/unit1-240314094133-fd74a320/75/Exploratory-Data-Analysis-Unit-1-ppt-presentation-pptx-21-2048.jpg)















































