Download to read offline



![HRI - Hybrid Chat and Task Dialogue
MDP policy:
• States = [Distance, TaskCompleted, UserEngaged ...]
• Actions = [PerformTask, Greet, Goodbye, Chat,
GiveDirections, Wait, RequestTask, RequestShop]
• Reward function is optimising for successful task
completion and higher engagement
4](https://image.slidesharecdn.com/0otfknntmi8yqcyynuug-signature-ac73736b926bcc64fefb8eaa7cb026d6d141dc7cd33efeefd149aaca2976f02a-poli-181211023542/85/Natural-Language-Processing-From-Human-Robot-Interaction-to-Alzheimer-s-Detection-4-320.jpg)






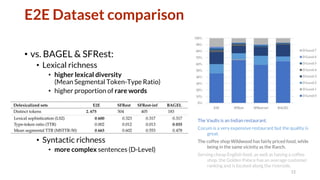
![E2E NLG Challenge - Dataset Collection
• Well-known restaurant domain
• Bigger than previous sets
• 50k unaligned, longer MR+ref pairs
11
Loch Fyne is a kid-friendly restaurant serving
cheap Japanese food.
Instance
s
MRs Refs/MR Slots/MR W/Ref Sent/Ref
E2E 51,426 6,039 8.21 5.73 20.34 1.56
SF Restaurants 5,192 1,914 1.91 2.63 8.51 1.05
Bagel 404 202 2.00 5.48 11.55 1.03
name [Loch Fyne],
eatType[restaurant],
food[Japanese],
price[cheap],
kid-friendly[yes]
Serving low cost Japanese style cuisine, Loch
Fyne caters for everyone, including families
with
small children.
*J.Novikova, O.Lemon, V.Rieser. Crowd-Sourcing NLG Data: Pictures Elicit Better Data, In Proceedings of INLG 2016
• More diverse & natural
• partially collected using pictorial MRs
• higher MSTTR, more rare words, more complex syntax
• noisier, but compensated by more refs per MR](https://image.slidesharecdn.com/0otfknntmi8yqcyynuug-signature-ac73736b926bcc64fefb8eaa7cb026d6d141dc7cd33efeefd149aaca2976f02a-poli-181211023542/85/Natural-Language-Processing-From-Human-Robot-Interaction-to-Alzheimer-s-Detection-11-320.jpg)


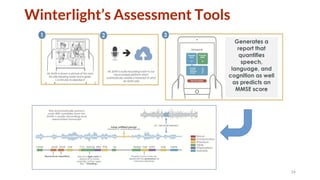



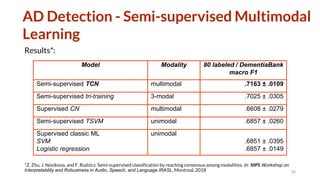

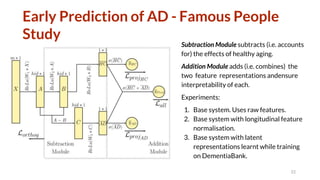
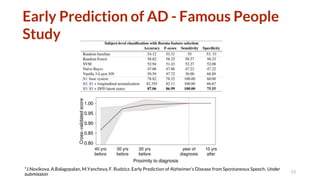


The document discusses several topics related to natural language processing: 1. Spoken human-robot interaction, including hybrid chat-task dialogue and multimodal dialogue evaluation. Reinforcement learning was used to optimize task completion and engagement. 2. Evaluation of natural language systems, including problems with existing automatic metrics and improving human evaluation methods. Referenceless quality estimation was also discussed. 3. Alzheimer's detection from language, including the effect of heterogeneous data, semi-supervised multimodal learning, and early prediction of Alzheimer's using analysis of spontaneous speech from famous people.






















































