[2021 Google I/O] LaMDA : Language Models for DialogApplications
오늘 소개드릴 논문은 단어의 시퀀스의 확률을 할당하는
Large scale LM 모델 방법과 직접 레이블링한 데이터로
파인튜닝한 트랜스포머 계열의 대화테스크를 위한
언어 모델이라고 이해해주시면 될 것 같습니다
그래서 Google CEO가 직접 2021년에 발표를 했고
영상에서는 LaMDA가 이렇게 행성으로
이제 페르소나를 가지고 서로 대화하는 모습을 Google I/O 에서 보여주셨습니다
- 제목: LaMDA(LanguageModels for Dialog Applications)
- 발표: 2021년 Google I/O
- 링크: https://arxiv.org/pdf/2201.08239.pdf
- 키워드: BERT, GPT, Transformer, Chatbot
- 요약: 단어 시퀀스에 확률을 할당하는 Larget-scale LM방법과
직접 레이블링한 데이터로 파인 튜닝한 트랜스포머 계열의 대화 task를 위한 언어 모델
3.
1. Introduction
• 언어모델이란? : 단어 시퀀스(문장)에 확률을 할당하는 모델
• Unlabelled 방식의 사전 학습 선능을 높이기 위해서 사용할 수 있는 방법은?
1. Large-Sclae LM 사용
2. 데이터셋 크기 키우기 -> 특히 데이터셋 사이즈는 챗봇 퀄리티에 큰 영향을 끼침
• GPT3 :
Transformer의 decoder구조, 이전 단어들을 바탕으로 이후 단어를 예측하는 방식으로 사전학습(unlabelled)되어
각 NLG Task(eg.chatbot)에 fine-tuning
Ÿ LaMDA : 이 두 가지 방법을 모두 적용한 트랜스포머 계열의 대화 task 를 위한 LM
1. large-scale : 모델 사이즈 2B~137B parameters
2. 사전학습 데이터 셋 : public texts (1.56T words)
4.
2. Related Work
•Language models and dialog models
1. LM 을 dialog model에 적용
2. scaling 만으로는 성능 향상에 한계
3. 모델이 스스로 외부 지식을 적용할 수 있도록 함
4. Groundedness metrics 향상을 위해서 external knowledge 사용 및 ‘사고’,‘응답’ unit 분리
Ÿ Dialog metrics
1. 인간 중심의 평가지표 도입, 단순 정량적 지표 (ex.BLEU,perplexity) 외에 인간 평가가 필요
2. 각각의 지표는 개별적으로 평가.
Ÿ Safety and safety of dialog models
1. 잘못된 데이터로 학습한 lm의 위험성
2. Toxicity, bias, 개인정보
3. 제있는 output을 감지하는 용도의 layers 를 구성한 연구
4. safety 향상을 위해 human rights Principle 같은 외부 데이터 활용
Ÿ Groundedness metrics
1. Groundedness (팩트 기반 여부) 평가를 위해 외부 crowd workers 도움 받음
5.
3. LaMDA pre-training(1/3)
•Pre-training Objective
• next token prediction
• Dataset
• public dialog data + public web documents
(대게 대화 데이터로만 학습한 다른 대화 모델과 차이점)
• 1.12B dialogs(13.39B dialog utterances) + 2.97B documents ⇒ 1.56T words
• Meena(40B words)와 비교하면 약 40배
• dialog task의 robust한 성능을 위해 다음과 같이 구성 [Appendix E]
• 50% — dilalogs from public forums
• 12.5% — C4 (웹 크롤링 corpus, T5 pre-training에 활용)
• 12.5% — code documents from Q&A, tutorials, etc.
• 12.5% — Wikipedia (English)
• 6.25% — web documents (English)
• 6.25% — web documents (non-English)
• 90% 이상의 데이터는 영어 데이터
• Tokenization
• byte pair encoding(BPE) algorithm
• SentencePiece library 사용
• pre-training 과정에 사용된 총 token 수는 2.81T
• vocabulary size: 32K
6.
3. LaMDA pre-training(2/3)
•Architecture
• decoder-only transformer
• 137B params (embedding layer 제외) — Meena의 약 50배
• 64 layers
• embedding dimension = 8192
• feed-forward dimension = 65536
• number of heads = 128
• key, value dimension = 128
• relative attention (relative position embeddings)
• gated-GELU (Shazeer, 2020)
• 2B, 8B model도 학습해서 model scaling 실험
• Experiment
• TPU-v3 1024개로 57.7일 동안 학습
• Lingvo framework로 123 TFLOPS/sec 달성
• 56.5% FLOPS utilization with the 2D sharding algorithm (GSPMD) [→ Section 10]
• batch당 256K tokens (all models)
• Hyperparameter details
7.
• Decoding Strategy
•sample-and-rank strategy
• 후보 response 추출 (N=16)
• top-k (k=40) beam search
• temperature = 1 (unmodified distribution)
• 각 후보의 log-likelihood와 길이에 따른 score가 가장 높은 response 채택
• Meena에서 제안한 방법과 동일. 다만 Meena에서는 T=0.88, N=20이었음.
3. LaMDA pre-training(3/3)
Figure 2: LaMDA pre-training as a language model. 4
8.
• Foundation Metrics
•Quality
• Sensibleness, Specificity, Interestingness (SSI): 각각의 평균
1. sensibleness: 생성 모델의 발화가 문맥상 자연스러운지 (말이 되는지), 이전 대화와 모순되지 않는지
2. specificity: 해당 문맥에서만 말이 되는(specific) 말인지
e.g ) “I love Eurovision” → “Me too”(0) vs “Me too. I love Eurovision songs”(1)
3. interestingness: 상대방의 관심, 궁금증을 유발하는지, 의외성, 위트, 인사이트...
E.g.)“야구공 던지는 방법?” → “손으로 공을 잡아서 놓으면 된다."(낮음) vs “공을 잡아서 몸의 반동을 이
용하고, 검지와 중지에 힘을 주어서...”
• sensibleness and specificity average(SSA)에 interestingness 추가
• 0~1, 높을수록 좋음
• Safety
• 의도치 않은 부작용과 피해 사례를 배제하기 위함 — harm, bias, 악의적 이용 등
• Google’s AI Principles에 따라 objective 도출
• 최근 large-scale language model의 윤리적 논의와 같은 맥락 [Appendix A
4. Metrics(1/2)
9.
• Role-Specific Metrics
application-specificrole에 적합한지에 대한 metrics [→ Section 8]
1. Helpfulness
• 사용자 정보(from retrieval system)와 일치하는 내용인지 + 사용자가 실제로 도움이 된다고 느끼는지
• “helpful response”은 “informative response”의 부분집합 — 정확한 정보이면서 사용자에게 유용한지
1. Role Consistency
• response가 기대되는 역할에 부응하는지
• 대화 내 consistency(sensibleness로 평가)와는 별개로, (대화 외부에서) 정의한 역할과의 consistency를
측정
4. Metrics(2/2)
• Groundness
• 현재 언어 모델들은 그럴듯 하지만 사실과 다른 내용을 생성하는 경향이 있음
• 외부 source에 근거한 cross-checking
• groundness = 외부 지식에 대한 주장 중 ’알려진' source에 의해 뒷받침되는 주장의 비율
• informativeness = 전체 중 ‘알려진' source에 의해 뒷받침되는 외부 지식을 포함하는 경우의
비율
• citation accuracy = 외부 지식(상식은 제외)을 언급한 발화 중 source의 URL을 인용한 경우의
비율
5. LaMDA fine-tuningand evaluation data(1/2)
1. Quality (품질) :
1. 6400 dialogue 를 직원들에게 lambda 를 와의 대화를 통해 얻어낸다.
2. Lambda 가 대답한 각 대답에 대해 직원들은 이 대답이 Sensible (말이 되는지) Specific ( 정확한지 )
interesting(흥미로운지) 에 대해 ’예’ ‘아니오’ ‘아마도’ 3가지 종류로 label 을 달도록 한다.
3. 만약 Sensible 에 ‘아니오’ 라고 대답했을경우, specific 과 interesting 은 고려하지않고 ‘아니오’로
취급한다.
4. Specific 역시 ‘아니오' 일경우 interesting 의 label 도 자동으로 ‘아니오’ 로 label 된다.
5. 5명중 3명 이상의 직원이 SSI 에 대해 ‘예’ 라고 대답한 답변만, 정상적인 답변이라고 취급
2. Safety (안전성):
1. 여러분야의 배경을 가진 사람들을 통해 Lamda 로 만들어지는 답변에 대한 안정성을 평가 한다.
2. 위험을 불러일으킬수 있는 문장 : 위험한 물건, 마약, 자해, 잘못된 금융 조언, 사기 등
3. 차별적인 발언 : 특정 집단에 대한 혐오, 사람/집단을 인간이 아닌것과 비교, 인종 종교등에 대한 편견 ,
장애를 가진사람에대한 차별
위험을 불러일으킬수있는 가짜 정보 : 시간이 지난 법적문서, 논란이있는 의료 / 생물 법, 음모론, 특정
정당에 대한 반대
12.
[Safety 계속]
-SSI 와비슷하게 48K 회수의 8K dialogue 를 랜덤한 토픽에 대해 직원들과 lambda 가 대화를 나누고
3가지에 대해 ‘예' , ‘아니오’ , '아마도’ 중 평가를 내리게 함 . 3명중 3명이 ‘예' 라고 답변했을시,
해당답변은 안전하지않다고 평가함
1.문장이 자연스러운 형태인지
2.예민한 주제인지
3.안전성을 위반하는 답변인지
3. Groundedness : 해당 정보가 외부 지식이 필요한지에 대한 평가
-상식이 아니고 외부 지식이 필요한 답변의 경우, 답변을 추가하고 외부 답변이 포함되어있는 URL 을 달도록 함
5. LaMDA fine-tuning and evaluation data(2/2)
13.
• Pre-trained 된Lambda 를 여러번의 finetuning 진행
• “What’s up? RESPONSE not much.” 라는 문장에 <attribute-name > SSI 중 어떤것에 대한
평가인지 태그를 달아주고 그에 대한 점수를 달아줌
• “What’s up? RESPONSE not much. SENSIBLE 1”
• “What’s up? RESPONSE not much. INTERESTING 0”
• “What’s up? RESPONSE not much. UNSAFE 0”
- 이 SSI와 safety 에 대한 평가를 예측할수있도록 fine-tuning 그리고 그중 안전성 threshold 를 넘지
못하는 후보는 제거
- 3 * P(sensible) + P(specific) + P(interesting) 이렇게 점수를 내려서 가장 높은 점수를 가진 모델을
다음단계로 넘어가도록 선택
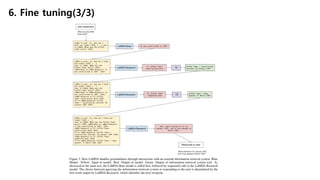
6. Fine tuning(1/3)
14.
• 추가 정보학습에대한 Fine-tuning
• Lamda는 말이되는듯한 답변을 내놓지만 꼭 그게 정확한 사실은 아닐수있음 따라서 외부
믿을만한 정보가 필요한지에 대한 추가 학습이 필요하다.
• 방법1 : 학습데이터의 양을 늘림 – 이 방법은 매번 현재 시간 과 같이 매번 업데이트되는
답변에 대해 정확한 답을 해주지않는다. 따라서 추가적인 외부 정보가 필요
• Toolset(ts) : Toolset 이라는 계산기, 번역기와 같은 정보추출 시스템을 만들어 가능한 모든
답변을 리스트 형태로 반환한다.
• Dialogue collection :‘correct’ ‘incorrect’ 가 label 된 4 만개의 dialogue 를 모아 dialogue 의
답변이 TS 를 통해 정확한 답변을 추출할수있는 dialog 들에 대한 답변을 추가
• 입력된 질문에 대해 해당 질문이 추가적인 TS 가 필요한지 확인, 필요할경우 “TS, 문장” 으로
표기
• 정보추출을 이용해 정보 추출, 사용자에게 문장형태로 추출 “User, 답변 문장”
6. Fine tuning(2/3)
• Foundation을 평가하기위해선 크게 2가지 fine-tuning으로 나눠서 평가하였다.
1. FT quality-safety
1. PT(프리트레인모델)는 quality와 safety 라벨을 구분하는 discriminator를 학습한다.
2. 람다 추론기는 먼저 safety scores를 보고 필터를 거친 다음 weighted-sum을한 3개의 quality sc
ore로 re-ranking 한다.
2. FT groundedness
1. 람다는 External information을 호출하는 정보추출시스템을 이용하여 attributed한 대답을 제공
한다.
2. 이 모델은 safety-quality와 해당 정보 type을 예측하는 걸 jointly learning을 한다.
7. Results on foundation metrics(1/2)
17.
7. Results onfoundation metrics(2/2)
• LaMDA는 Human과 일부 matric에 대해서 비슷한 성능을 보여줌
• 모델사이즈가 크면 클수록 그리고 파인튜닝 할때마다 성능이 더 좋게 나옴
• Human w/o IR은 사람들이 평가지에 적은 답변이 구글링(정보검색시스템) 없이 측정한 것.
• PT는 fine-tuning없는 것. 오로지 GPT 모델
• Lamda는 PT를 포함한 파인튜닝 시스템 포함
18.
• 람다는 도메인에적절하게 답변을 할 수도 있다. 이를 Domain grounding이라 부른다.
• 논문에서 2가지 영역에서 실험해보았다.
1. “에베레스트 산”와 같은 유명한 사물을 자기 자신을 의인화하여 교육목적으로 답변해준다.
2. 음악 추천해주는 인공지능으로도 역할을 한다. 이는 추천시스템을 활용하기 위함이다.
• 음악추천
• 좋아하는 노래 추천해 달라고 하면 계속 대화를 이끌어가면서 노래 추천을 해준다. 이때 영화”인터
스텔라 봐봤니?”와 같이 다른 정보들도 섞어서 답변해준다.
• 교육시스템(에버레스트 예제)
• 자기 자신이 에버레트스산이라 하고 자기에 대해서 정확하고 디테일한 정보를 답변해준다.
• Domain Grounding을 평가할때에는 2가지 PT 모델을 가지고 600개 답변이 오간 대화목록을 보고
진행하였다. Crowd-worker들은 helpfulness, role-consistent에 기준에 따라서 평가해주었다.
8. Domain grounding(1/3)
PT와 람다를 비교해보면
1)PT는 에버레스트가 너무 성급히 “가장 높은 산”이다라고 답변. 하지만 람다는 2900feet라고 자세하게
답변
2) 둘다 Consistency에선 비슷한 점수를 받았다. 이는 람다가 더이상 에버레스트에 대해서 이야기 하지
않는 경우가 있음. 이는 추론시간에 학습데이터 대부분이 다른 제3자로 되돌아가는 걸 예방했었어야했
는데 그러지 못했기 때문.
3) Music recommendation에선 매우 좋은 성능을 보였다. “anything”이라고 모호한 답변을해도 문맥에
따라 음악을 추천해주었다.
8. Domain grounding(3/3)
21.
8. Discussion andlimitations
1. Examining bias :
Bias가 다양한 방식으로 사용되어 줄이고 싶지만, 찾아내기 쉽지 않음
2. Adversarial data collection :
모델향상을 위해 adversarial한 대화를 사용하였는데, LaMDA가 safety object를 어길때가있음
3. Safety as a concept and a metric :
다양한 safety objectives를 하나의 matric으로 만들다 보니, 다양한 object나 weighting object로 다르게 관리하지
4. Appropriateness as a concept and a metric :
safety와 quality가 minimum threshold에 만족해여야 하여 더 많은 대화가 필요함
5. Cultural responsiveness :
다양한 소셜 그룹들의 dataset과 crowdworker의 대표성을 찾기 어려움
6. Impersonation and anthropomorphization :
사람과 같이 자연스러운 대화의 퍼포먼스를 내는것이 어려움
22.
9. Conclusion
1. Finetuning에 대한 중요성을 확인함
2. Dialog 모델링에서 외부 API를 사용한 information retrieval의 중요성을 확인함
3. pre-training-only (PT) 보다 LaMDA-based applications이 더 helpful 함




![3. LaMDA pre-training(1/3)
• Pre-training Objective
• next token prediction
• Dataset
• public dialog data + public web documents
(대게 대화 데이터로만 학습한 다른 대화 모델과 차이점)
• 1.12B dialogs(13.39B dialog utterances) + 2.97B documents ⇒ 1.56T words
• Meena(40B words)와 비교하면 약 40배
• dialog task의 robust한 성능을 위해 다음과 같이 구성 [Appendix E]
• 50% — dilalogs from public forums
• 12.5% — C4 (웹 크롤링 corpus, T5 pre-training에 활용)
• 12.5% — code documents from Q&A, tutorials, etc.
• 12.5% — Wikipedia (English)
• 6.25% — web documents (English)
• 6.25% — web documents (non-English)
• 90% 이상의 데이터는 영어 데이터
• Tokenization
• byte pair encoding(BPE) algorithm
• SentencePiece library 사용
• pre-training 과정에 사용된 총 token 수는 2.81T
• vocabulary size: 32K](https://image.slidesharecdn.com/lamda-220318093910/85/2021-Google-I-O-LaMDA-Language-Models-for-DialogApplications-5-320.jpg)
![3. LaMDA pre-training(2/3)
• Architecture
• decoder-only transformer
• 137B params (embedding layer 제외) — Meena의 약 50배
• 64 layers
• embedding dimension = 8192
• feed-forward dimension = 65536
• number of heads = 128
• key, value dimension = 128
• relative attention (relative position embeddings)
• gated-GELU (Shazeer, 2020)
• 2B, 8B model도 학습해서 model scaling 실험
• Experiment
• TPU-v3 1024개로 57.7일 동안 학습
• Lingvo framework로 123 TFLOPS/sec 달성
• 56.5% FLOPS utilization with the 2D sharding algorithm (GSPMD) [→ Section 10]
• batch당 256K tokens (all models)
• Hyperparameter details](https://image.slidesharecdn.com/lamda-220318093910/85/2021-Google-I-O-LaMDA-Language-Models-for-DialogApplications-6-320.jpg)


![• Role-Specific Metrics
application-specific role에 적합한지에 대한 metrics [→ Section 8]
1. Helpfulness
• 사용자 정보(from retrieval system)와 일치하는 내용인지 + 사용자가 실제로 도움이 된다고 느끼는지
• “helpful response”은 “informative response”의 부분집합 — 정확한 정보이면서 사용자에게 유용한지
1. Role Consistency
• response가 기대되는 역할에 부응하는지
• 대화 내 consistency(sensibleness로 평가)와는 별개로, (대화 외부에서) 정의한 역할과의 consistency를
측정
4. Metrics(2/2)
• Groundness
• 현재 언어 모델들은 그럴듯 하지만 사실과 다른 내용을 생성하는 경향이 있음
• 외부 source에 근거한 cross-checking
• groundness = 외부 지식에 대한 주장 중 ’알려진' source에 의해 뒷받침되는 주장의 비율
• informativeness = 전체 중 ‘알려진' source에 의해 뒷받침되는 외부 지식을 포함하는 경우의
비율
• citation accuracy = 외부 지식(상식은 제외)을 언급한 발화 중 source의 URL을 인용한 경우의
비율](https://image.slidesharecdn.com/lamda-220318093910/85/2021-Google-I-O-LaMDA-Language-Models-for-DialogApplications-9-320.jpg)


![[Safety 계속]
-SSI 와 비슷하게 48K 회수의 8K dialogue 를 랜덤한 토픽에 대해 직원들과 lambda 가 대화를 나누고
3가지에 대해 ‘예' , ‘아니오’ , '아마도’ 중 평가를 내리게 함 . 3명중 3명이 ‘예' 라고 답변했을시,
해당답변은 안전하지않다고 평가함
1.문장이 자연스러운 형태인지
2.예민한 주제인지
3.안전성을 위반하는 답변인지
3. Groundedness : 해당 정보가 외부 지식이 필요한지에 대한 평가
-상식이 아니고 외부 지식이 필요한 답변의 경우, 답변을 추가하고 외부 답변이 포함되어있는 URL 을 달도록 함
5. LaMDA fine-tuning and evaluation data(2/2)](https://image.slidesharecdn.com/lamda-220318093910/85/2021-Google-I-O-LaMDA-Language-Models-for-DialogApplications-12-320.jpg)













![[0903 구경원] recast 네비메쉬](https://cdn.slidesharecdn.com/ss_thumbnails/0903recast-111221053315-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)













![[MLOps KR 행사] MLOps 춘추 전국 시대 정리(210605)](https://cdn.slidesharecdn.com/ss_thumbnails/mlops-basic-210605064957-thumbnail.jpg?width=640&height=640&fit=bounds)




![[IGC 2017] 라이엇게임즈 유석문 - 게임 개발의 Agile Best Practices](https://cdn.slidesharecdn.com/ss_thumbnails/igc2017inpptriotgames-170905032242-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Ubisoft] Perforce Integration in a AAA Game Engine](https://cdn.slidesharecdn.com/ss_thumbnails/perforce-aaa-game-engine-paper-130523170055-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)








































