Human Interface Laboratory
‘나만의’코퍼스는 없다? 자연어처리 연구 데이터의
구축, 검증 및 정제에 관하여
2019. 10. 20 @TF-KR 3rd Offline Meeting
Won Ik Cho (Warnik Chow)
2.
Contents
• 연사 및내용 소개
• 무엇을 위하여 데이터를 만드나
• 데이터 만들기 – You are not alone!
• Case study 1: Wakeup-word-free personal agent
Corpus annotation scheme
• Case study 2: Keyphrase extraction for questions/commands
Corpus generation scheme
• 수집, 정제 및 활용
• Summary
1
3.
연사 소개
• 조원익
B.S. in EE/Mathematics (SNU, ’10~’14)
Ph.D. student in ECE (SNU INMC, ‘14~)
• Academic background
Interested in mathematics? then EE!
• Double major?
– ...
Early years in Speech processing lab
• Source separation
• Voice activity & endpoint detection
• Automatic music composition
Currently studying on computational linguistics
• Corpus annotation/generation, SLU system modeling ...
2
내용 소개
• 이talk에서 다루는 것 (= 태스크에 관계없이 일반적인 것)
코퍼스를 만드는 이유와 의미
코퍼스의 주석 혹은 생성 과정에서 고려할 것
• 이 talk에서 깊게 다루지 않는 것 (= 태스크마다 다를 수 있는 것)
구체적인 크롤링 기법
한국어 데이터 정제에 대한 세부 사항
4
6.
무엇을 위하여 데이터를만드나
• WHY?
이미 세상에 있는 데이터로는 하기 힘든 어떤 일을 하기 위하여
• 이미 있더라도 공개가 안됨
그 중에서도 자연어 데이터(코퍼스)는
• 사전적으로는 음성과 텍스트를 포함
• 음성 신호는 (quantization을 거치긴 하지만) ‘연속’적
• 텍스트 언어는 이산적, 분절적, 추상적
• 언어화된 데이터는 다른 데이터의 semantic한 측면과 연관될 수 있음
• 언어별 특성을 무시할 수 없음
– 음성 감정 인식 (speech emotion recognition) 데이터셋
» IEMOCAP (Busso et al., 2008), RAVDESS (Livingstone & Russo, 2018) 등이 공개
» 하지만 한국어 음성 감정 인식 데이터셋은?
– 대화 화행 파악 (dialog act) 데이터셋
» Annotation on SWBD (Stolcke et al., 2000) 등이 공개
» 한국어 대화 화행 파악 공개 데이터 및 사이즈는? 다른 low-resource 언어는?
5
7.
무엇을 위하여 데이터를만드나
• WHY?
즉, 자연어 코퍼스는
• 존재하던 태스크에 해당 언어의 코퍼스가 없거나
• 기존에 없던 태스크를 개별언어/일반언어학 관점에서 만들거나
• 개별 언어에 적합한 태스크를 정의하고자 할 때 만듦!
만드는 방식
• Collection (crawling from an open data, buying a license, by platform ...)
• Annotation
– Single sentence/document classification
– Multi-sentence natural language inference
– Role labeling on sentence tokens (POS tagging, SRL, NER etc.)
• Generation
– Some QA datasets
– Summarization / Paraphrasing
– Sentence style transfer
6
8.
무엇을 위하여 데이터를만드나
• 코퍼스의 종류
주석 없는 코퍼스 (말뭉치)
• Written language (text)
• Spoken language (usually speech + text)
• Speech-only! (out of the scope of this talk...but important)
• 구어체/문어체 여부는 written/spoken 여부와 관련은 있지만 일치하지는 않음
주석이 있는 (annotated) 코퍼스
• Single/multi-sentence or dialog labeled
• Sentence token-level annotation
병렬 (parallel) 코퍼스
• Sentence/paragraph/document – to – something matched
– 여기서 token/sentence/paragraph/document란?
– Parallel corpus와 annotated corpus의 차이는?
» Gold data를 만든다는 점에서는 같지만...
7
9.
무엇을 위하여 데이터를만드나
• 어노테이션의 종류
통사(syntax)에서 의미(semantics)를 넘어 화용(pragmatics)까지
• Classical NLP pipeline (Tenney et al., 2019)?
– Syntactic tasks, in general, require deeper linguistic knowledge
– Although truly low level
concerns intonation... (Jun, 2000)
8
10.
무엇을 위하여 데이터를만드나
• 어노테이션의 종류
통사(syntax)에서 의미(semantics)를 넘어 화용(pragmatics)까지
• Speech act/dialog act, emotion, natural language inference (NLI; entailment,
contradiction etc.) and figurative languages (irony, sarcasm, pun etc.)
9
(Table from Stolckes, 2000)
11.
무엇을 위하여 데이터를만드나
• 어노테이션의 종류
... 사실 영역은 종종 그 경계가 흐려진다
• 기존의 분류 및 주석 체계를 참고
하되, 목적과 부합하는 방향으로
발전시키면 됨
• 학술 기고가 목적일 경우
– ‘왜’ 새로운 방법론을?
– 방법론은 정당한가?
– Replicable한가?
• 하지만, corpus를 만드는
(annotate하는) 데에 있어
일반적인 process, 혹은
rule of thumb가 있다면?
10
(Figure from a linguistics meme page... where? Maybe Grice’s Maxmemes https://www.facebook.com/linguisticsmemes/)
12.
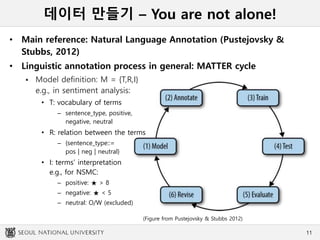
데이터 만들기 –You are not alone!
• Main reference: Natural Language Annotation (Pustejovsky &
Stubbs, 2012)
• Linguistic annotation process in general: MATTER cycle
Model definition: M = {T,R,I}
e.g., in sentiment analysis:
• T: vocabulary of terms
– sentence_type, positive,
negative, neutral
• R: relation between the terms
– {sentence_type::=
pos | neg | neutral}
• I: terms’ interpretation
e.g., for NSMC:
– positive: ★ > 8
– negative: ★ < 5
– neutral: O/W (excluded)
11
(Figure from Pustejovsky & Stubbs 2012)
13.
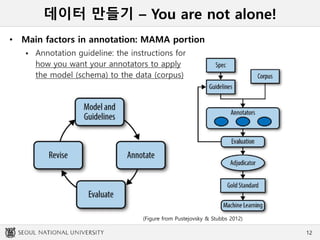
데이터 만들기 –You are not alone!
• Main factors in annotation: MAMA portion
Annotation guideline: the instructions for
how you want your annotators to apply
the model (schema) to the data (corpus)
12
(Figure from Pustejovsky & Stubbs 2012)
14.
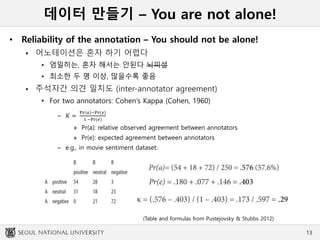
데이터 만들기 –You are not alone!
• Reliability of the annotation – You should not be alone!
어노테이션은 혼자 하기 어렵다
• 엄밀히는, 혼자 해서는 안된다 뇌피셜
• 최소한 두 명 이상, 많을수록 좋음
주석자간 의견 일치도 (inter-annotator agreement)
• For two annotators: Cohen’s Kappa (Cohen, 1960)
– 𝐾 =
Pr 𝑎 −Pr(𝑒)
1 −Pr(𝑒)
» Pr(a): relative observed agreement between annotators
» Pr(e): expected agreement between annotators
– e.g., in movie sentiment dataset:
13
(Table and formulas from Pustejovsky & Stubbs 2012)
15.
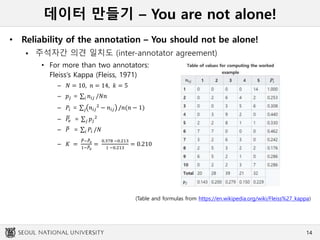
데이터 만들기 –You are not alone!
• Reliability of the annotation – You should not be alone!
주석자간 의견 일치도 (inter-annotator agreement)
• For more than two annotators:
Fleiss’s Kappa (Fleiss, 1971)
– 𝑁 = 10, 𝑛 = 14, 𝑘 = 5
– 𝑝𝑗 = 𝑖 𝑛𝑖𝑗 /𝑁𝑛
– 𝑃𝑖 = 𝑗 𝑛𝑖𝑗
2
− 𝑛𝑖𝑗 /𝑛(𝑛 − 1)
– 𝑃𝑒 = 𝑗 𝑝𝑗
2
– 𝑃 = 𝑖 𝑃𝑖 /𝑁
– 𝐾 =
𝑃− 𝑃𝑒
1− 𝑃𝑒
=
0.378 −0.213
1 −0.213
= 0.210
14
(Table and formulas from https://en.wikipedia.org/wiki/Fleiss%27_kappa)
16.
데이터 만들기 –You are not alone!
• Reliability of the annotation – You should not be alone!
주석자들의 언어학 지식 - 태스크에 따라 다름
• 주석자의 언어학적인 훈련이 너무 많이 되어 있는 경우는 실제 언어 사용의 경향
성을 보장하지 못할 수도 있으나 (이것도 되지 않아?), 정도만 다를 뿐 언어 직관이
사람마다 다르고 주석에 영향을 미치는 것은 불가피함 & 자연스러움
주석자들의 언어 배경
• 최소 L2 정도의 언어 능력을 가진 사람이 주석을 달 필요가 있음
– 모어(L1)와 다른 언어를 사용하는 환경에서 그 언어를 습득한 경우?
– dialect가 포함된 경우는, 실질적으로 다른 언어로 보는 것이 타당 (lexicon, prosody, 종
종 syntax까지도 영향받을 수 있음)
– 웬만하면 한국인들끼리는 한국어 코퍼스 구축합시다!
크라우드소싱? (refer to Geva et al., 2019)
주석자들에게 준 금액
주석자들의 작업 환경
주석자들의 지식 배경
15
17.
Case study 1:Wakeup-word-free personal agent
• Goal of the project
호출어 (오케이 구글, 시리야 등) 없이도 알아서 반응하는 음성 대화 서비스
• What should be done (in whole)?
근거리/원거리 음성인식 (close/far-talk ASR)
화자 인식 (speaker recognition)
Noisy하고 비정형인 입력 문장 응대 여부 (whether to respond to noisy and
non-canonical input utterances) >> Work of NLP/CL!
16
오늘 또
떨어졌네
이게 대체
며칠째
파란불이냐
지금 손실이
얼마지
18.
Case study 1:Wakeup-word-free personal agent
• What should be done within NLP?
기계가 (혹은 사람이) 어떤 문장에 반응해야 하는가?
• 대화에서 문장의 경계(boundary)는 어떻게 결정되어야 하는가?
– ‘문장’들에 대해, 응대해야 할 경우를 어떻게 특정지을 것인가?
» 구두점이 주어지지 않는 경우들(ASR result)은 어떻게 처리할 것인가?
17
Relevant한 topic으로 연결되었다면,
sentence segment들의 연결도 하나의 utterance로 보는 게 맞을 것
평서문 / 의문문 / 명령문 (syntax-semantic level의 성질)
!= 서술 / 질문 / 요구
우리에게 필요한 것은? speech act
(즉, 어떤 발화가 청자에게 answer / action의 obligation을 주는지?)
(rhetorical하지는 않은지?)
한국어에는 audio가 주어져야 그 의미를 파악할 수 있는 text가 많음 (Yun, 2019)
(e.g., 어디 놀러가고 싶어) 이러한 문장들을 특별히 분류해 처리한다면?
19.
Case study 1:Wakeup-word-free personal agent
• Annotation guideline의 작성
해당 task는 depunctuated text data의 single sentence classification 태스크!
18
단일 문장인가?
Intonation 정보로
결정 가능한가?
Question set이 있고
청자의 답을 필요로 하는가?
Effective한 To-do list가
청자에게 부여되는가?
No
Yes
No
Yes
요구 (Commands)
수사명령문 (RC)
Full clause를
포함하는가?
No
No
Compound sentence: 힘이 강한 화행에 중점
(서로 다른 문장도 같은 토픽일 때 한 문장으로 간주)
Fragments (FR)
질문 (Questions)
No
Context-dependent (CD)
Yes
Yes
Yes
Intonation 정보가
필요한가?
Yes
Intonation-dependent (ID)
No Questions /
Embedded form
Requirements /
Prohibitions
수사의문문 (RQ)
Otherwise
서술 (Statements)
{sentence_type::= FR | CD | ID | Q | C | RQ | RC | S}
20.
Case study 1:Wakeup-word-free personal agent
• Annotation guideline의 작성
쉽게 볼 수 있는 도식 + 자세한 예문을 포함한 가이드라인
• 이상적인 annotation: 높은 IAA로 데이터 구축
현실
• 1. 가이드라인 초안 작성
• 2. 작성자 및 주석자가 일부 annotation
• 3. 주석자와 회의를 거쳐 다수의 수정 사항 발견
• 4. 가이드라인의 수정
• 5. 다시 일부 annotation
• ...
• n-2. 가이드라인_v7_final_진짜최종 작성
• n-1. 최종 어노테이션
• n. IAA 측정 및 ML/DL 이용한 분류 정량측정
19
21.
Case study 1:Wakeup-word-free personal agent
• 실제 annotation: 시간과 금액의 줄타기
Funding이 있으면 가장 좋다!
Funding이 없다면...?
• 열정, 향학열, 졸업에의 열망 etc. (thanks to 박하은, 국대호)
• Inter-annotator agreement의 측정
3인의 Seoul Korean native; 최종적으로 0.85 (Fleiss’s Kappa) 확보
• semantic보다는 syntax-semantic task였기에..?
• Conflict에 대한 회의 및 해소
Agreement가 특히 낮은 class에 집중
• 해당 발화들의 처리에 대한 회의 및 주석 수정
• ML/DL을 이용한 정량 측정
Character-level BiLSTM 을 이용하여 0.88 정도의 accuracy 확보 (Cho et al.,
2018a)
20
22.
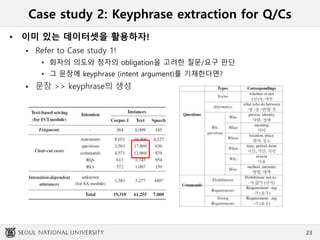
Case study 2:Keyphrase extraction for Q/Cs
• Goal of the project
음성인식 결과 질문/요구로 판단되어도, human conversation에서는 종종 기
계가 인식하기 어려운 sentence style로 표현되어 분석이 어려울 수 있음
• Semantic web search나 device control에 용이하게 활용하면서도, 자연스러운 답
변 생성에 활용할 수 있는 양식으로 정보를 추출할 수 있을까?
21
방카슈랑스가 대체 뭐냐
Intention
identification
Question?
방카슈랑스의 의미
Keyphrase extraction
23.
Case study 2:Keyphrase extraction for Q/Cs
• What should be done within NLP?
정형 혹은 비정형의 질문/요구 문장(지시 발화)으로부터 질문/요구사항을 ‘자
연어의 형식으로’ 추출해 보자! (Cho et al., 2018b)
• e.g., “얼마나 걸리더라 그 동서울에서 유성 가는 데에”
– 자연어가 아닌 형식: semantic parsing
» {시점: 동서울, 종점: 유성, 논항: 버스 소요시간}
– 자연어가 아닌 형식: slot filling
» {도메인: 교통, 논항: 버스 소요시간, 아이템: 동서울발 유성행}
– 자연어의 형식?
» 동서울발 유성행 버스 소요시간
22
24.
Case study 2:Keyphrase extraction for Q/Cs
• 이미 있는 데이터셋을 활용하자!
Refer to Case study 1!
• 화자의 의도와 청자의 obligation을 고려한 질문/요구 판단
• 그 문장에 keyphrase (intent argument)를 기재한다면?
문장 >> keyphrase의 생성
23
25.
Case study 2:Keyphrase extraction for Q/Cs
• 새로운 데이터를 생성하여 class imbalance를 해결하자!
keyphrase >> 문장의 생성
24
26.
Case study 2:Keyphrase extraction for Q/Cs
• Generated corpus의 검증 방법?
이미 존재하는 코퍼스에서, 한 문장 당 한 개의 phrase를 생성한 경우
• 다양한 문장 양식에 대해 다양한 phrase를 얻을 수 있음
• 원칙이 일관성 있게 적용되었는지 판단하기 쉽지 않음
• 문장마다 phrase가 잘 매칭되는지 판단해야 하는 비용이 듦
특정 기준으로 만든 phrase들에서, phrase 하나당 여러 문장을 생성한 경우
• phrase의 종류는 제한되지만, 일관성 있게 원칙이 적용되는지 쉽게 판단 가능
– 즉, phrase 하나를 염두에 두고, 생성된 여러 개의 문장이 적합한지 판별하면 됨
• 특정 기준에 따라 쉽게 문장들을 분류할 수 있음
• 기존의 태깅 방식에 비해 sentence to phrase의 표현 양상이 제한될 수 있음
두 방식 모두, 최소 3인의 원어민 화자가 확인함으로써 검증
25
27.
Case study 2:Keyphrase extraction for Q/Cs
• Generated corpus의 검증 방법?
생각해볼 점
• Sentence generation이나 paraphrasing은 annotation이 아니다
– 즉, 앞서 논의했던 방식으로 참가자들 간의 agreement를 판단하기 어려움
– 참가자들 간의 felicity에 대한 consensus를 담보해야 하는 이유
26
28.
Case study 2:Keyphrase extraction for Q/Cs
• Generated corpus의 검증 방법?
생각해볼 점
• Translation이 그렇듯, abstractive summarization이나 paraphrasing,
sentence rewriting 등에 정답은 없음
– Translation:
» 어느 정도 의미적으로 허용 가능한 범위 존재
– Abstractive summarization
» 그 범위가 translation보다 넓음. 역시 original sentence에 종속
– Paraphrase 혹은 sentence rewriting:
» 그 범위가 매우 넓음
» 사실상 core content를 유지할 수 있다면 같은 의미로 볼 수 있음
– 각 양식에 대해 consensus의 정도가 서로 달라야 하지 않을까?
27
29.
수집, 정제, 레이블링및 활용
• 데이터 수집
어떤 데이터를 모아야 하는가?
• 구어체 텍스트 코퍼스
– 영화 리뷰, 쇼핑몰 리뷰, 채팅 로그, 트윗
• 문어체 텍스트 코퍼스
– 위키피디아, 신문기사, 소설
• 음성 스크립트
– 드라마 대본, 영화 대본, 뉴스 대본, 자막이 있는 1인 크리에이터 방송(?)
• 음성 전사 데이터
– 전화통화 전사, 회의 전사, 상담/진료 전사
• 음성 코퍼스
– 전화통화 데이터, 감정 음성 코퍼스, 음성 의도 코퍼스
영리/학술목적 데이터 취급(수집/배포)에 저작권 문제 항상 확인하세요!
• e.g., 라이선스 확인, 소유기관 문의, robot.txt 등
28
30.
수집, 정제, 레이블링및 활용
• 데이터 정제
Raw 데이터에 정제가 필요한가?
• 할 경우: 정확한 slot filling 을 위해 정제된 텍스트가 필요한 경우 등등
• 아닌 경우: 구어 인식 시스템을 만들 경우, 정제가 의미나 본질을 왜곡할 수 있는
경우 등등
필요하다면, 어떻게?
• Notepad++를 이용한 수작업, 혹은 RegEx
– https://pytorch.org/tutorials/beginner/chatbot_tutorial.html
• 기계학습 오류교정 알고리즘들 (한국어 기반: HCLT 학회를 참고하세요!)
– 맞춤법 검사 API https://github.com/spellcheck-ko/hunspell-dict-ko
– 띄어쓰기 API https://github.com/pingpong-ai/chatspace
29
31.
수집, 정제, 레이블링및 활용
• 데이터 레이블링
Human labeling: 앞서 말한 annotation process
• 높은 신뢰도의 코퍼스를 만들 수 있다
• Annotate-Evaluate-Revise의 과정을 반복해야 함 (돈 + 시간!)
• Annotation bias가 산입될 수 있음
(Semi-)Automatic: 일부 데이터의 human labeling을 통해 트레이닝한 모델로
unlabeled data를 예측하여 나온 결과를 검토 후 다시 트레이닝... (반복)
• 시간의 효율적 활용 가능
• 검증이 비교적 쉬워짐
Automatic: 코퍼스 자체의 성질을 이용
• ex1) IMDB (Maas et al., 2011) 나 NSMC에서 그러하듯, 리뷰 점수를 참고하여 일
정 점수 이하 negative, 일정 이상 positive, 그렇지 않은 경우 neutral
• ex2) Twitter 등에서 ‘냉소’, ‘농담’ 등을 찾을 때, 해당 단어로 #hashtag 걸린 트윗들
을 위주로 살펴보는 것
30
32.
수집, 정제, 레이블링및 활용
• 데이터 활용
분야에 따른 한국어 자연어처리 데이터?
• Phonetics/prosody(-semantics)
– 억양 분석, 음성 감정 인식, 음성 의도 파악
• Morphology-syntax-semantics
– 형태소 분석, 품사 태깅, 복합명사 분해
• Syntax-semantics
– 의존구문 분석, 개체명 인식, 의미역 결정
• Semantics
– 의도 파악과 슬롯필링, 감성 분석, 자연어 추론, 메타언어
• Document-level
– 문서요약, 질의응답, 문장/스토리 생성
• Multilingual
– 기계번역, speech-to-text (speech) 번역, 동시번역
범용 한국어 리소스 모음
• Sejong Corpus (말뭉치, 구어/문어 넘나들며 광범위! 그러나 HWP 복잡한 사용...)
– https://github.com/coolengineer/sejong-corpus will help!
• AI HUB (QA dialog, Speech recognition, Multi-modal, KR-EN parallel)
• Naver NLP Challenges 등 각종 경진대회 자료, KorQuAD 등 리더보드
31
33.
Summary
• ‘무엇을 하고싶은지?’를 가장 먼저 생각
• 데이터를 만들기 전에 ‘이미 있는지 보자!’
• Annotation 전에 ‘다른 언어로 선행연구가 있는지 보자!’
• Annotator나 participant를 모집함에 있어
참여자들로 인한 bias도 무시할 수 없으며
교차 검증을 통해 일반성을 높여야 한다
• Annotation과 generation 이후에
가이드라인의 검증과 수정을 반복하는 것은 전혀 이상하지 않다
주석/생성 등의 방식에 따라 검증 방식도 다르다
• 결론: ‘나만의’ 데이터는 없다! - ‘우리의’ 데이터인 것...
32
34.
Reference (order ofappearance)
• Busso, Carlos, et al. "IEMOCAP: Interactive emotional dyadic motion capture database." Language resources and
evaluation 42.4 (2008): 335.
• Livingstone, Steven R., and Frank A. Russo. "The Ryerson Audio-Visual Database of Emotional Speech and Song
(RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English." PloS one 13.5 (2018):
e0196391.
• Stolcke, Andreas, et al. "Dialogue act modeling for automatic tagging and recognition of conversational speech."
Computational linguistics 26.3 (2000): 339-373.
• Tenney, Ian, Dipanjan Das, and Ellie Pavlick. "Bert rediscovers the classical nlp pipeline." arXiv preprint arXiv:1905.05950
(2019).
• Jun, Sun-Ah. "K-tobi (korean tobi) labelling conventions." ms, Version 3 (2000).
• Pustejovsky, James, and Amber Stubbs. Natural Language Annotation for Machine Learning: A guide to corpus-building
for applications. " O'Reilly Media, Inc.", 2012.
• Cohen, Jacob. "A coefficient of agreement for nominal scales." Educational and psychological measurement 20.1 (1960):
37-46.
• Fleiss, Joseph L. "Measuring nominal scale agreement among many raters." Psychological bulletin 76.5 (1971): 378.
• Geva, Mor, Yoav Goldberg, and Jonathan Berant. "Are we modeling the task or the annotator? an investigation of
annotator bias in natural language understanding datasets." arXiv preprint arXiv:1908.07898 (2019).
• Yun, Jiwon. "Meaning and Prosody of Wh-Indeterminates in Korean." Linguistic Inquiry 50.3 (2019): 630-647.
• Cho, Won Ik, et al. "Speech Intention Understanding in a Head-final Language: A Disambiguation Utilizing Intonation-
dependency." arXiv preprint arXiv:1811.04231 (2018a).
• Cho, Won Ik, et al. "Extracting Arguments from Korean Question and Command: An Annotated Corpus for Structured
Paraphrasing." arXiv preprint arXiv:1810.04631 (2018b).
• Maas, Andrew L., et al. "Learning word vectors for sentiment analysis." Proceedings of the 49th annual meeting of the
association for computational linguistics: Human language technologies-volume 1. Association for Computational
Linguistics, 2011.
33
#3 overview:
gender bias in NLP – various problems
translation: real-world problem - example e.g. Turkish, Korean..?
How is it treated in previous works?
Why should it be guaranteed?
problem statement: with KR-EN example
why not investigated in previous works?
why appropriate for investigating gender bias?
what examples are observed?
construction:
what are to be considered?
formality (걔 vs 그 사람)
politeness (-어 vs –어요)
lexicon sentiment polarity (positive & negative & occupation)
+ things to be considered in... (not to threaten the fairness)
- Measure?
how the measure is defined, and proved to be bounded (and have optimum when the condition fits with the ideal case)
concept of Vbias and Sbias – how they are aggregated into the measure << disadvantage?
how the usage is justified despite disadvantages
the strong points?
- Experiment?
how the EEC is used in evaluation, and how the arithmetic averaging is justified
the result: GT > NP > KT?
- Analysis?
quantitative analysis – Vbias and Sbias, significant with style-related features
qualitative analysis – observed with the case of occupation words
Done: tgbi for KR-EN, with an EEC
Afterward: how Sbias can be considered more explicitly? what if among context? how about with other target/source language?



































![[Langcon2020]롯데의 딥러닝 모델은 어떻게 자기소개서를 읽고 있을까?](https://cdn.slidesharecdn.com/ss_thumbnails/f9hnsy5tssozj2qrhkvv-signature-dd45fc34d8f62546c0d2058bfb8f93528e6a60dccd5f8a015e70eac2a2418a21-poli-200131124302-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2021 Google I/O] LaMDA : Language Models for DialogApplications](https://cdn.slidesharecdn.com/ss_thumbnails/lamda-220318093910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[싸이그램즈 2018] 텍스트 데이터 전처리로 시작하는 NLP](https://cdn.slidesharecdn.com/ss_thumbnails/psygramsnlp101-180704045500-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2D2]다국어음성합성시스템(NVOICE)개발](https://cdn.slidesharecdn.com/ss_thumbnails/2d2nvoice-140929192429-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[AWS Innovate 온라인 컨퍼런스] 한국어를 위한 AWS 인공지능(AI) 서비스 소개 및 활용 방법 - 강정희, AWS 솔루션즈 아키텍트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session3jungheekang-200319071626-thumbnail.jpg?width=640&height=640&fit=bounds)



![[study] Building Universal Dependency Treebanks in Korean](https://cdn.slidesharecdn.com/ss_thumbnails/180928universaldependencykorean-190321061459-thumbnail.jpg?width=640&height=640&fit=bounds)


![[study] character aware neural language models](https://cdn.slidesharecdn.com/ss_thumbnails/181114characterawareneurallanguagemodels-190321063423-thumbnail.jpg?width=640&height=640&fit=bounds)









![2108 [LangCon2021] kosp2e](https://cdn.slidesharecdn.com/ss_thumbnails/2108langcon2021kosp2e-210902190354-thumbnail.jpg?width=640&height=640&fit=bounds)










![2008 [lang con2020] act!](https://cdn.slidesharecdn.com/ss_thumbnails/2008langcon2020act-200829231450-thumbnail.jpg?width=640&height=640&fit=bounds)