Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
JH
Uploaded by
Jin Hirokawa
PPTX, PDF
2,897 views
一年目がWatsonを調べてみた Discovery編
2017/11/16 BMXUGつきじ#2 資料 私が確認した限りのWatson Discoveryの機能です。
Technology
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Downloaded 18 times
1
/ 14
2
/ 14
3
/ 14
4
/ 14
5
/ 14
6
/ 14
7
/ 14
8
/ 14
9
/ 14
10
/ 14
11
/ 14
12
/ 14
13
/ 14
14
/ 14
More Related Content
PDF
45分間で「ユーザー中心のものづくり」ができるまで詰め込む
by
Yoshiki Hayama
PDF
もしプロダクトマネージャー・プロダクトチームにUXリサーチのメンターがついたら <レクイエム>
by
Yoshiki Hayama
PDF
Elasticsearch勉強会#44 20210624
by
Tetsuya Sodo
PDF
バーチャルライブ配信アプリREALITYの3Dアバターシステムの全容について
by
gree_tech
PPTX
クラウド環境でのセキュリティ監査自動化【DeNA TechCon 2020 ライブ配信】
by
DeNA
PDF
pytest × TDD テスト駆動開発のススメ
by
iRidge, Inc.
PPTX
Dangerでpull requestレビューの指摘事項を減らす
by
Shunsuke Maeda
PPT
「KPTの理論と実践」プロジェクトへの「ふりかえりカイゼン」の導入で学んだこと
by
ESM SEC
45分間で「ユーザー中心のものづくり」ができるまで詰め込む
by
Yoshiki Hayama
もしプロダクトマネージャー・プロダクトチームにUXリサーチのメンターがついたら <レクイエム>
by
Yoshiki Hayama
Elasticsearch勉強会#44 20210624
by
Tetsuya Sodo
バーチャルライブ配信アプリREALITYの3Dアバターシステムの全容について
by
gree_tech
クラウド環境でのセキュリティ監査自動化【DeNA TechCon 2020 ライブ配信】
by
DeNA
pytest × TDD テスト駆動開発のススメ
by
iRidge, Inc.
Dangerでpull requestレビューの指摘事項を減らす
by
Shunsuke Maeda
「KPTの理論と実践」プロジェクトへの「ふりかえりカイゼン」の導入で学んだこと
by
ESM SEC
What's hot
PDF
Project Facilitation From Hiranabe
by
Yasui Tsutomu
PDF
第2回 顧客理解のためのUXリサーチ実践講座 〜インタビュー・ネットリサーチから分析手法をワークショップで学ぶ - Web担当者の学校 2024年11月29日
by
Yoshiki Hayama
PDF
Marp Tutorial
by
Rui Watanabe
PDF
OpenCLに触れてみよう
by
You&I
PPTX
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
PDF
Clean Architectureで設計してRxJSを使った話
by
_kondei
PDF
gRPC と nginx による HTTP/2 サービスメッシュ構築
by
Kazuki Ogiwara
PDF
ZabbixのAPIを使って運用を楽しくする話
by
Masahito Zembutsu
PDF
リクルート式 自然言語処理技術の適応事例紹介
by
Recruit Technologies
PDF
ゲームのインフラをAwsで実戦tips全て見せます
by
infinite_loop
PDF
Bert for multimodal
by
Yasuhide Miura
PDF
対話と創発~アジャイルなマーケティングチームの作り方
by
Yukio Okajima
PDF
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
PDF
データ仮想化を活用したデータ分析のフローと分析モデル作成の自動化のご紹介
by
Denodo
PDF
Kubernetesを使う上で抑えておくべきAWSの基礎概念
by
Shinya Mori (@mosuke5)
PPTX
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料)
by
NTT DATA Technology & Innovation
PPTX
マイクロサービスにおける 結果整合性との戦い
by
ota42y
PPTX
Hololens2 MRTK2.7(OpenXR) でのビルド環境構築(環境設定からビルドまで)
by
聡 大久保
PPTX
Mongo dbを知ろう
by
CROOZ, inc.
PPTX
さくっと理解するSpring bootの仕組み
by
Takeshi Ogawa
Project Facilitation From Hiranabe
by
Yasui Tsutomu
第2回 顧客理解のためのUXリサーチ実践講座 〜インタビュー・ネットリサーチから分析手法をワークショップで学ぶ - Web担当者の学校 2024年11月29日
by
Yoshiki Hayama
Marp Tutorial
by
Rui Watanabe
OpenCLに触れてみよう
by
You&I
世界一わかりやすいClean Architecture
by
Atsushi Nakamura
Clean Architectureで設計してRxJSを使った話
by
_kondei
gRPC と nginx による HTTP/2 サービスメッシュ構築
by
Kazuki Ogiwara
ZabbixのAPIを使って運用を楽しくする話
by
Masahito Zembutsu
リクルート式 自然言語処理技術の適応事例紹介
by
Recruit Technologies
ゲームのインフラをAwsで実戦tips全て見せます
by
infinite_loop
Bert for multimodal
by
Yasuhide Miura
対話と創発~アジャイルなマーケティングチームの作り方
by
Yukio Okajima
Amazon Redshift パフォーマンスチューニングテクニックと最新アップデート
by
Amazon Web Services Japan
データ仮想化を活用したデータ分析のフローと分析モデル作成の自動化のご紹介
by
Denodo
Kubernetesを使う上で抑えておくべきAWSの基礎概念
by
Shinya Mori (@mosuke5)
kubernetes初心者がKnative Lambda Runtime触ってみた(Kubernetes Novice Tokyo #13 発表資料)
by
NTT DATA Technology & Innovation
マイクロサービスにおける 結果整合性との戦い
by
ota42y
Hololens2 MRTK2.7(OpenXR) でのビルド環境構築(環境設定からビルドまで)
by
聡 大久保
Mongo dbを知ろう
by
CROOZ, inc.
さくっと理解するSpring bootの仕組み
by
Takeshi Ogawa
Viewers also liked
PPTX
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
PPTX
Microsoft 365 で両立するセキュリティと働き方改革
by
Hiroyuki Komachi
PPTX
GitLabを16万8千光年ワープさせた話(改)
by
Wataru NOGUCHI
PDF
GitLab Prometheus
by
Shingo Kitayama
PDF
NPO に Office365 Nonprofit 版導入してみました。
by
Takanori Tsuruta
PPTX
IBM Connections Engagement Center
by
TIMETOACT GROUP
PDF
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
PDF
Watson Build Challengeに参加してみた
by
Wataru Koyama
PDF
QGIS応用操作.
by
Yoichi Kayama
PDF
カンバン駆動開発 - Trello, Slackで始めるKDD
by
Kazuya Takahashi
PDF
Watsonに、俺の推しアイドルがかわいいと、わかってほしかった:2017年12月3日 IBM Cloud (Bluemix) 冬の大勉強会
by
Yoshiki Hayama
PPTX
Slack Appsでやれる事を確認した。年内日本語化されるんで、急ぎで!
by
Yasuyuki Ogawa
PDF
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
PDF
Watson × IBM Bluemix で簡単アプリ開発
by
softlayerjp
PPTX
地震対策ハッカソン キズナコントラクト
by
彩友美 小岩
PPTX
スタートアップこそOffice365で業務効率化
by
Yasutaka Hamada
PPTX
Twilio bluemix hands-on 資料
by
Masaya Fujita
PDF
“利用者”として使ってみた!Office 365で実現する”自己満足”システム
by
Takeru Imaizumi
PDF
AWSマイスターシリーズReloaded -Amazon Glacier-
by
Amazon Web Services Japan
PDF
Kubernets on Bluemix + DevOpsでコンテナCIやってみた
by
Shoichiro Sakaigawa
AI and Machine Learning Demystified by Carol Smith at Midwest UX 2017
by
Carol Smith
Microsoft 365 で両立するセキュリティと働き方改革
by
Hiroyuki Komachi
GitLabを16万8千光年ワープさせた話(改)
by
Wataru NOGUCHI
GitLab Prometheus
by
Shingo Kitayama
NPO に Office365 Nonprofit 版導入してみました。
by
Takanori Tsuruta
IBM Connections Engagement Center
by
TIMETOACT GROUP
Waston が拓く UX の新しい地平 〜 UX デザイナーが IBM Waston を使ってみた 〜:2017年4月22日 AI eats UX me...
by
Yoshiki Hayama
Watson Build Challengeに参加してみた
by
Wataru Koyama
QGIS応用操作.
by
Yoichi Kayama
カンバン駆動開発 - Trello, Slackで始めるKDD
by
Kazuya Takahashi
Watsonに、俺の推しアイドルがかわいいと、わかってほしかった:2017年12月3日 IBM Cloud (Bluemix) 冬の大勉強会
by
Yoshiki Hayama
Slack Appsでやれる事を確認した。年内日本語化されるんで、急ぎで!
by
Yasuyuki Ogawa
SoftLayer Bluemix Summit 2015: BluemixでWatsonをつかいたおせ!
by
Miki Yutani
Watson × IBM Bluemix で簡単アプリ開発
by
softlayerjp
地震対策ハッカソン キズナコントラクト
by
彩友美 小岩
スタートアップこそOffice365で業務効率化
by
Yasutaka Hamada
Twilio bluemix hands-on 資料
by
Masaya Fujita
“利用者”として使ってみた!Office 365で実現する”自己満足”システム
by
Takeru Imaizumi
AWSマイスターシリーズReloaded -Amazon Glacier-
by
Amazon Web Services Japan
Kubernets on Bluemix + DevOpsでコンテナCIやってみた
by
Shoichiro Sakaigawa
一年目がWatsonを調べてみた Discovery編
1.
1 日本情報通信株式会社 廣川 陣 1年目がWatsonを調べてみた! ~Discovery編~ 1
2.
Speaker 2 日本情報通信株式会社 ソリューションビジネス本部 ソフトウェアテクニカルセールス部 先進テクノロジーグループ 廣川 陣(Jin
Hirokawa) 入社1年目 チームの戦力になるために日々奮闘中 出身地:大田区
3.
Discoveryの概要 3 大量のデータを検索するとともに、データからパターン や傾向を読み取り、適切な意思決定を支援します。 いろいろな形式の文書を解釈して良い感じに情報を付加 してくれるから、検索精度を上げてくれるし洞察も与え てくれる素敵な検索エンジン
4.
Discoveryの主機能 4 • 文書取込機能:HTML/PDF/WORD/JSONに対応 • エンリッチ機能:取り込んだ文書に対してタグ付けを行う •
ストレージ機能:データをクラウド上に保存する • 検索機能:タグ付けした情報を含め、類似度スコア付きのデータ検索が可能
5.
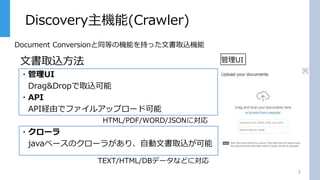
Discovery主機能(Crawler) 5 文書取込方法 ・管理UI Drag&Dropで取込可能 ・API API経由でファイルアップロード可能 ・クローラ javaベースのクローラがあり、自動文書取込が可能 Document Conversionと同等の機能を持った文書取込機能 管理UI HTML/PDF/WORD/JSONに対応 TEXT/HTML/DBデータなどに対応
6.
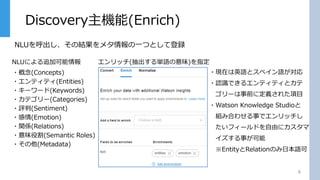
Discovery主機能(Enrich) 6 ・概念(Concepts) ・エンティティ(Entities) ・キーワード(Keywords) ・カテゴリー(Categories) ・評判(Sentiment) ・感情(Emotion) ・関係(Relations) ・意味役割(Semantic Roles) ・その他(Metadata) NLUを呼出し、その結果をメタ情報の一つとして登録 エンリッチ(抽出する単語の意味)を指定 ・現在は英語とスペイン語が対応 ・認識できるエンティティとカテ ゴリーは事前に定義された項目 ・Watson Knowledge
Studioと 組み合わせる事でエンリッチし たいフィールドを自由にカスタマ イズする事が可能 ※EntityとRelationのみ日本語可 NLUによる追加可能情報
7.
Discovery主機能(Query) 7 • Discovery Query
Language エンリッチされたカラムに対して検索可能 • 自然文検索 (Natural Language Query) 従来のキーワードによる検索及び自然文での検索が可能 • 関連性学習 (Relevancy Training) 質問と回答候補の関連性を学習させることにより、最適なランキングモ デルに育てる事が可能(自然文検索のみ) エンリッチ機能で付加された情報を含めてデータ検索が可能
8.
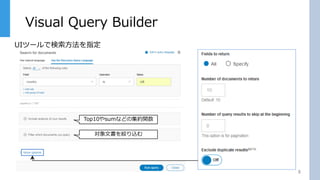
Top10やsumなどの集約関数 対象文書を絞り込む Visual Query Builder 8 UIツールで検索方法を指定
9.
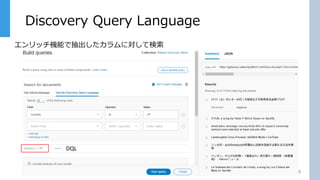
Discovery Query Language 9 エンリッチ機能で抽出したカラムに対して検索 DQL
10.
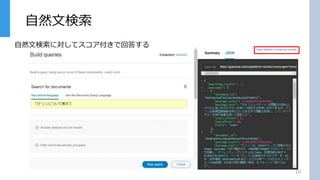
自然文検索 10 自然文検索に対してスコア付きで回答する
11.
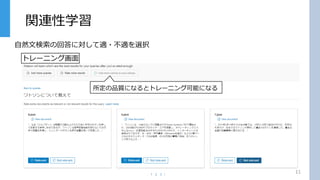
関連性学習 11 トレーニング画面 自然文検索の回答に対して適・不適を選択 所定の品質になるとトレーニング可能になる
12.
Discovery News 12 • データの登録が必要なく、すぐに活用可能 •
10万のニュースソースから毎日約 30万件の記事とブロ グを追加して常に更新され、過去60日間の履歴を保持 • NLUによるエンリッチ済のデータセットが用意されてい る
13.
Retrieve and Rankとの違い 13 •
NLU、WKSの機能が利用可能なので、抽出したカラムに対して検索す る事ができる • 文書の形式変更や初期設定が不要 • UI画面がついた • API経由で検索をかける際にPOSTではなくGETを使うため文字制限があ る※ • 辞書登録ができないため、専門的な用語がとれない※ • 全文検索のためシステムによって付与される情報も検索対象となる※ ※私が確認した限りでは
14.
まとめ 14 • 1年目のWatson初心者でも簡単に使えるUI • Retrieve
and Rankの機能を持ち合わせてい るが制約がある。 • エンリッチされた情報を使えるので、通常の検索エンジ ンと⽐較して⾼度な検索が可能
Editor's Notes
#3
Bluemix築地のコンセプトである初心者でも発表できる場というところで私にはうってつけ 至らない点も多々あると思いますが、ここ違うよっていうものがあればもし後ほど教えていただければと思います。 それでは
#4
解釈 Discoveryはシンプルな構成で、より多くの機能を実現
#5
ストレージ・サイズの上限は1TB位
#7
エンリッチ機能は文書を取り込む エンリッチされたメタ情報を検索条件として使えるので、通常の検索エンジンと⽐較してはるかに⾼度な検索が可能 概念 Concepts ⼊⼒テキストが関連付けられている概念を、そのテキストに存在する他の概念とエンティティに基づいて識別します。 エンティティ Entities ⽂中に記載されている⼈物、場所、イベント、その他のエンティティを検索します。 キーワード Keywords ⽂中に繰り返し出てくる重要なキーワードを抽出します。 カテゴリー Categories 対象⽂書を最⼤5レベルの分類基準に従って分類します。カテゴリーの⼀覧は下記リンクにあります。 評判 Sentiment ⽂章全体及び特定のフレーズに対して、その評判をpositive, negative, nutral の3値で分析します。 感情 Emotion ⽂章全体及び特定のフレーズに対して、その感情をjoy, anger, disgust, sadness, fearの5つの観点で分析します。 関係 Relations 2つのエンティティ間の関係を⾒つけ、その関係性を判別します。 意味役割 Semantic Roles 構⽂解析により⼊⼒⽂を「主語(Subject)」「動詞(Action)」「⽬的語(Object)」に分解します。 その他 Metadata HTMLファイルまたはURLを⼊⼒とし、そのHTMLの著者、タイトル、発⾏⽇を分析します。
#8
検索結果のフィルターや集計を行うことが可能 こちらにもUIがあります それが
#9
VQBという検索UIツールでここで様々なオプションを付けて検索を行う事ができます Search for document で自然文を使うかDQLを使うかの指定を行います。 集約関数やフィルタの設定もここでできます。 2つの検索方法のうちのまずDQLから Discovery query language
#10
DQLでは検索対象をカラムで絞り込んで検索を行います。 UIを使うと自動でDQLを生成してくれるのでそれを使って検索する事ができる 右がsummaryで表示した結果です
#11
こちらは自然文検索の結果をJSONで出力したもので、スコア付きで回答されている事がわかります。 文面だけでなく「意味」を判断するため、人間が話し言葉で打った質問に回答を返してくれます。 どのような条件で検索するとどういう結果がかえってくるかが確認 次にその回答をより適切なものにするための関連性学習について
#12
質問文をいれるとその回答がでるので回答毎にその回答が正解か正解じゃないかを選択して 所定の品質 最低でも49個の質問について選択しなければならない
#13
Discoveryのインスタンスを作るとデフォルトで表示されています データの保存先
#14
テキストデータではなくファイル名でHITしてしまう場合がある 2000文字程度
#15
まだ未熟ですがこれから成長していきたいと思います。
Download