2016 bigdata - projects list
•Download as DOCX, PDF•
0 likes•70 views

IEEE PROJECTS, M.TECH PROJECTS,
Recommended

Recommended
More Related Content
What's hot
What's hot (20)
Similar to 2016 bigdata - projects list
Similar to 2016 bigdata - projects list (20)
More from MSR PROJECTS
More from MSR PROJECTS (20)
Recently uploaded
Recently uploaded (20)
2016 bigdata - projects list
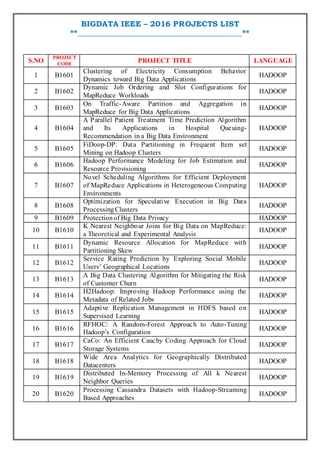
- 1. BIGDATA IEEE – 2016 PROJECTS LIST **_________________________________________** S.NO PROJECT CODE PROJECT TITLE LANGUAGE 1 B1601 Clustering of Electricity Consumption Behavior Dynamics toward Big Data Applications HADOOP 2 B1602 Dynamic Job Ordering and Slot Configurations for MapReduce Workloads HADOOP 3 B1603 On Traffic-Aware Partition and Aggregation in MapReduce for Big Data Applications HADOOP 4 B1604 A Parallel Patient Treatment Time Prediction Algorithm and Its Applications in Hospital Queuing- Recommendation in a Big Data Environment HADOOP 5 B1605 FiDoop-DP: Data Partitioning in Frequent Item set Mining on Hadoop Clusters HADOOP 6 B1606 Hadoop Performance Modeling for Job Estimation and Resource Provisioning HADOOP 7 B1607 Novel Scheduling Algorithms for Efficient Deployment of MapReduce Applications in Heterogeneous Computing Environments HADOOP 8 B1608 Optimization for Speculative Execution in Big Data ProcessingClusters HADOOP 9 B1609 Protectionof Big Data Privacy HADOOP 10 B1610 K Nearest Neighbour Joins for Big Data on MapReduce: a Theoretical and Experimental Analysis HADOOP 11 B1611 Dynamic Resource Allocation for MapReduce with Partitioning Skew HADOOP 12 B1612 Service Rating Prediction by Exploring Social Mobile Users’ Geographical Locations HADOOP 13 B1613 A Big Data Clustering Algorithm for Mitigating the Risk of Customer Churn HADOOP 14 B1614 H2Hadoop: Improving Hadoop Performance using the Metadata of Related Jobs HADOOP 15 B1615 Adaptive Replication Management in HDFS based on Supervised Learning HADOOP 16 B1616 RFHOC: A Random-Forest Approach to Auto-Tuning Hadoop’s Configuration HADOOP 17 B1617 CaCo: An Efficient Cauchy Coding Approach for Cloud Storage Systems HADOOP 18 B1618 Wide Area Analytics for Geographically Distributed Datacenters HADOOP 19 B1619 Distributed In-Memory Processing of All k Nearest Neighbor Queries HADOOP 20 B1620 Processing Cassandra Datasets with Hadoop-Streaming Based Approaches HADOOP