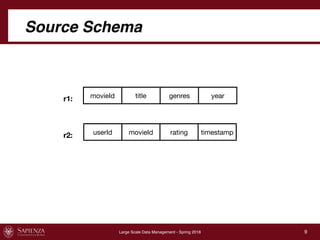
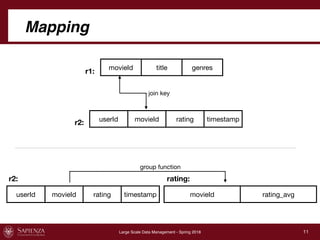
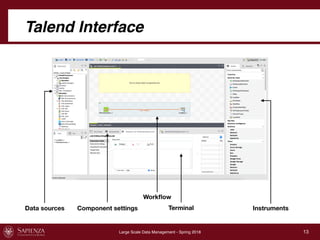
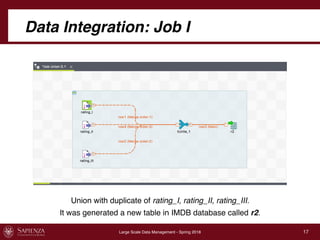
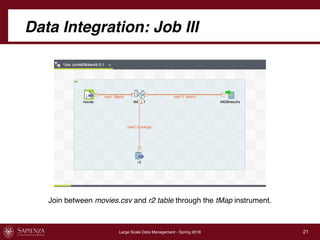
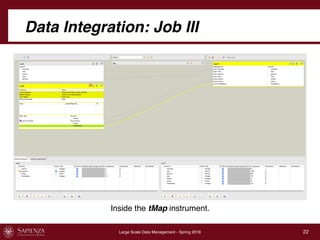
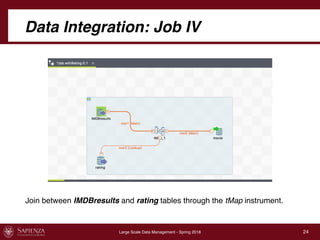
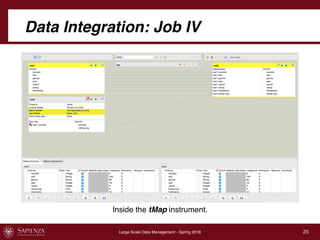
This document describes a data integration project involving data from IMDb. It involved extracting data from four CSV files into a global schema. Talend was used to perform the ETL process, which had to be divided into multiple jobs due to memory limitations. The final integrated data was stored in two tables in a MySQL database.