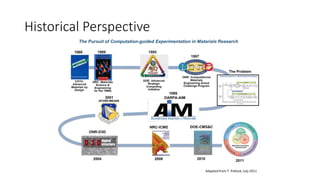
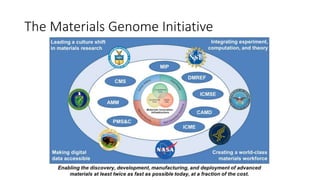
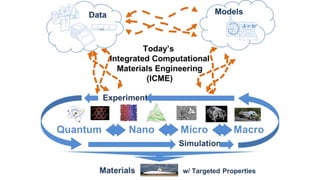
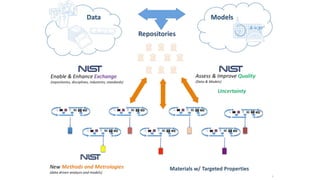
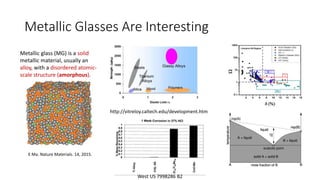
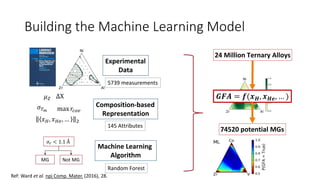
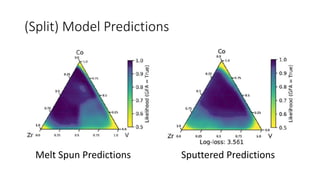
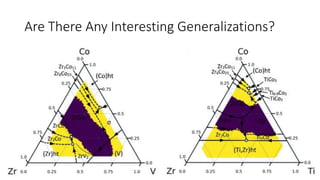
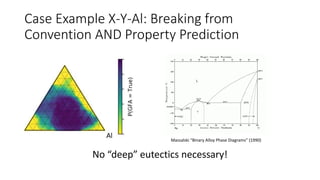
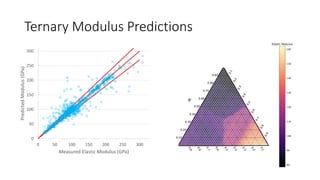
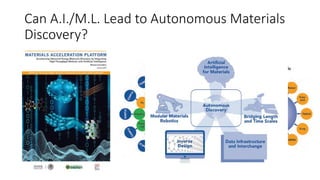
The document discusses the Materials Genome Initiative (MGI) and the High-Throughput Experimental Materials Collaboratory (HTE-MC). It describes NIST's role in supporting MGI through developing a materials innovation infrastructure. It outlines the vision for HTE-MC, which would integrate high-throughput synthesis and characterization tools across multiple institutions through a shared network and data management platform. This would provide broader access to experimental facilities and materials data to support accelerated materials discovery. A workshop was held in 2018 to discuss establishing the HTE-MC concept and defining its technical, operational and business models.