Download to read offline







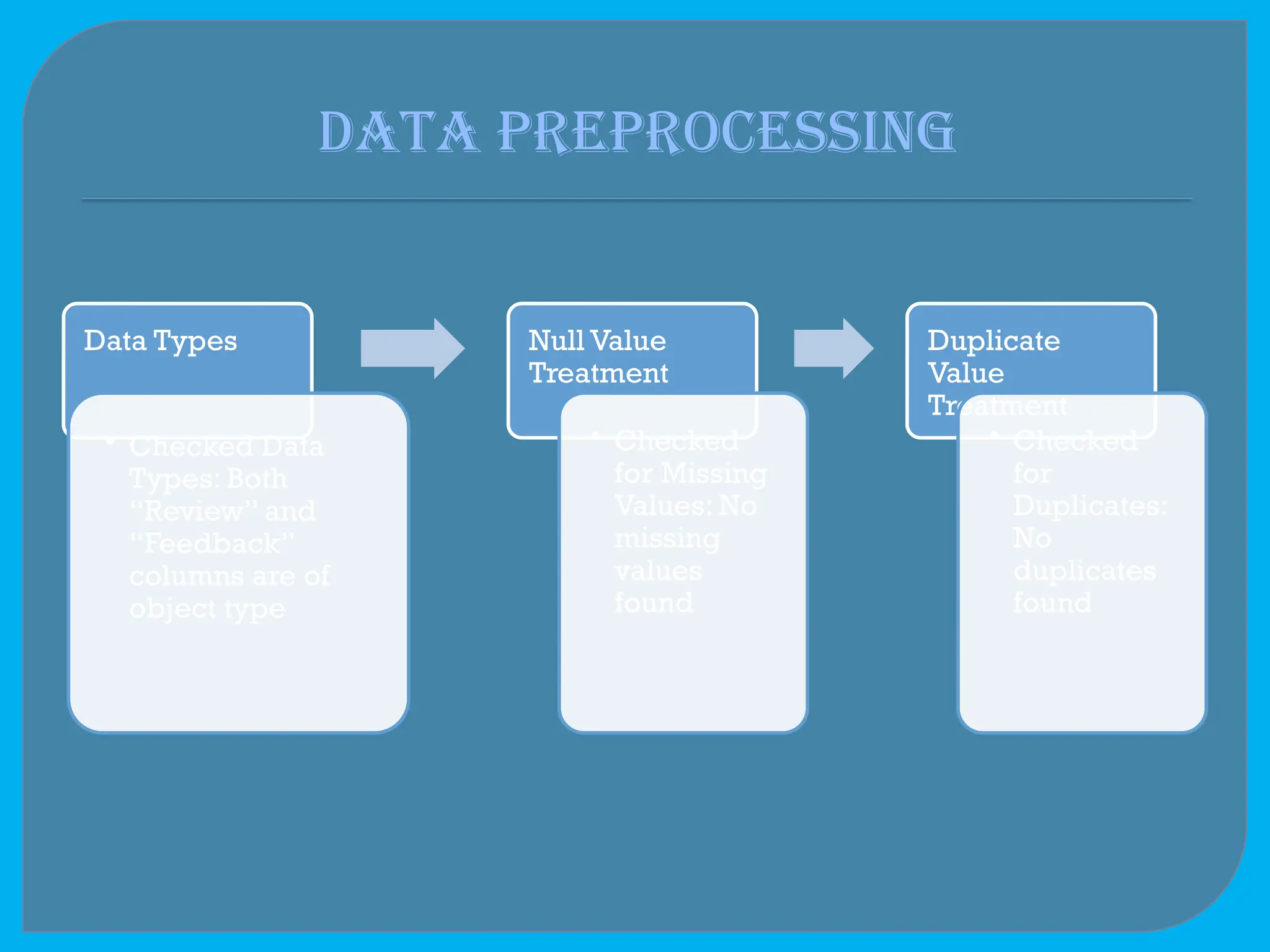

















The document outlines a project involving the analysis of hotel reviews using natural language processing (NLP) and machine learning. It details the problem statement, objectives, dataset specifics, data preprocessing steps, and model selection, focusing on logistic regression for sentiment analysis. Additionally, it discusses challenges faced during the project, including data quality issues and deployment considerations.






































![ict_presentation_final_final_final[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ictpresentationfinalfinalfinal1-251230145259-2b4839bd-thumbnail.jpg?width=640&height=640&fit=bounds)








