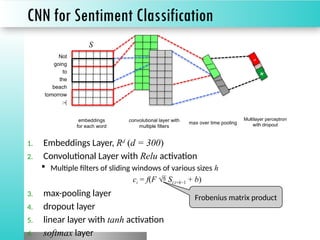
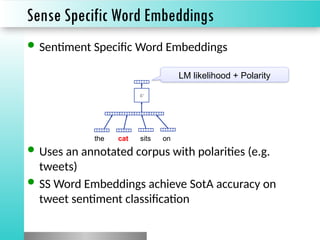
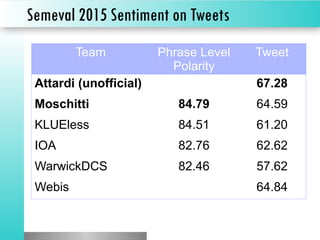
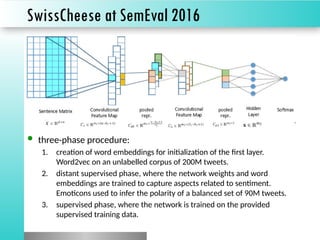
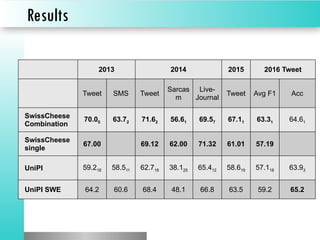
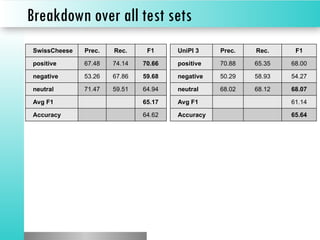
The document discusses sentiment classification, focusing on both supervised and unsupervised methods, with an emphasis on tools like VADER and machine learning techniques including convolutional neural networks (CNNs) and word embeddings. It outlines the classification pipeline and various techniques for improving sentiment analysis, such as deep learning models and ensemble methods. Additionally, it mentions the effectiveness of a character-level LSTM trained on Amazon reviews for predicting sentiment.