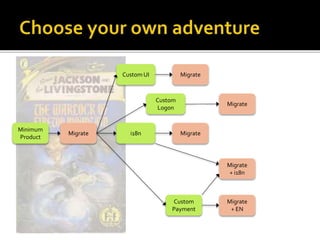
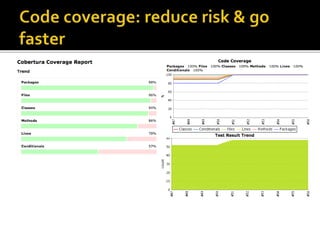
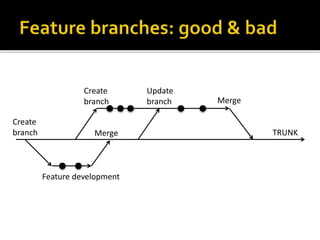
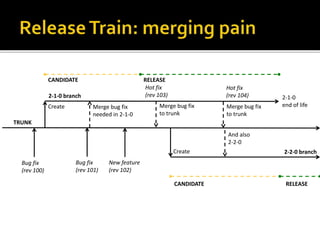
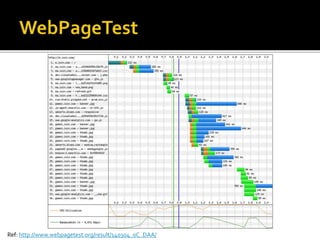
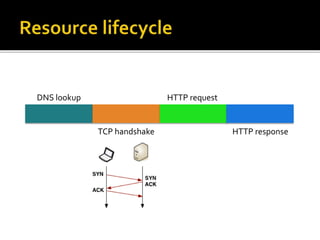
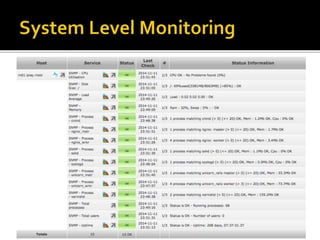
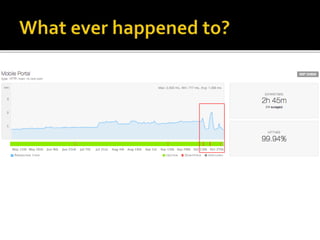
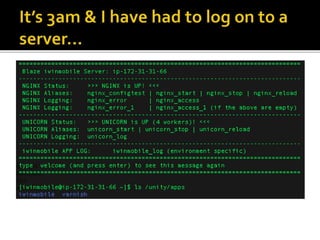
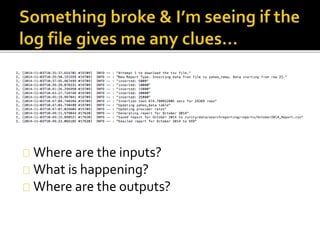
The document details the processes and considerations involved in shipping software products and managing software releases. It emphasizes the importance of effective communication, performance monitoring, and maintaining a streamlined development workflow with version control, testing, and deployment strategies. Additionally, it provides insights into addressing challenges such as data migration, customer support, and release management to enhance team efficiency and product delivery.