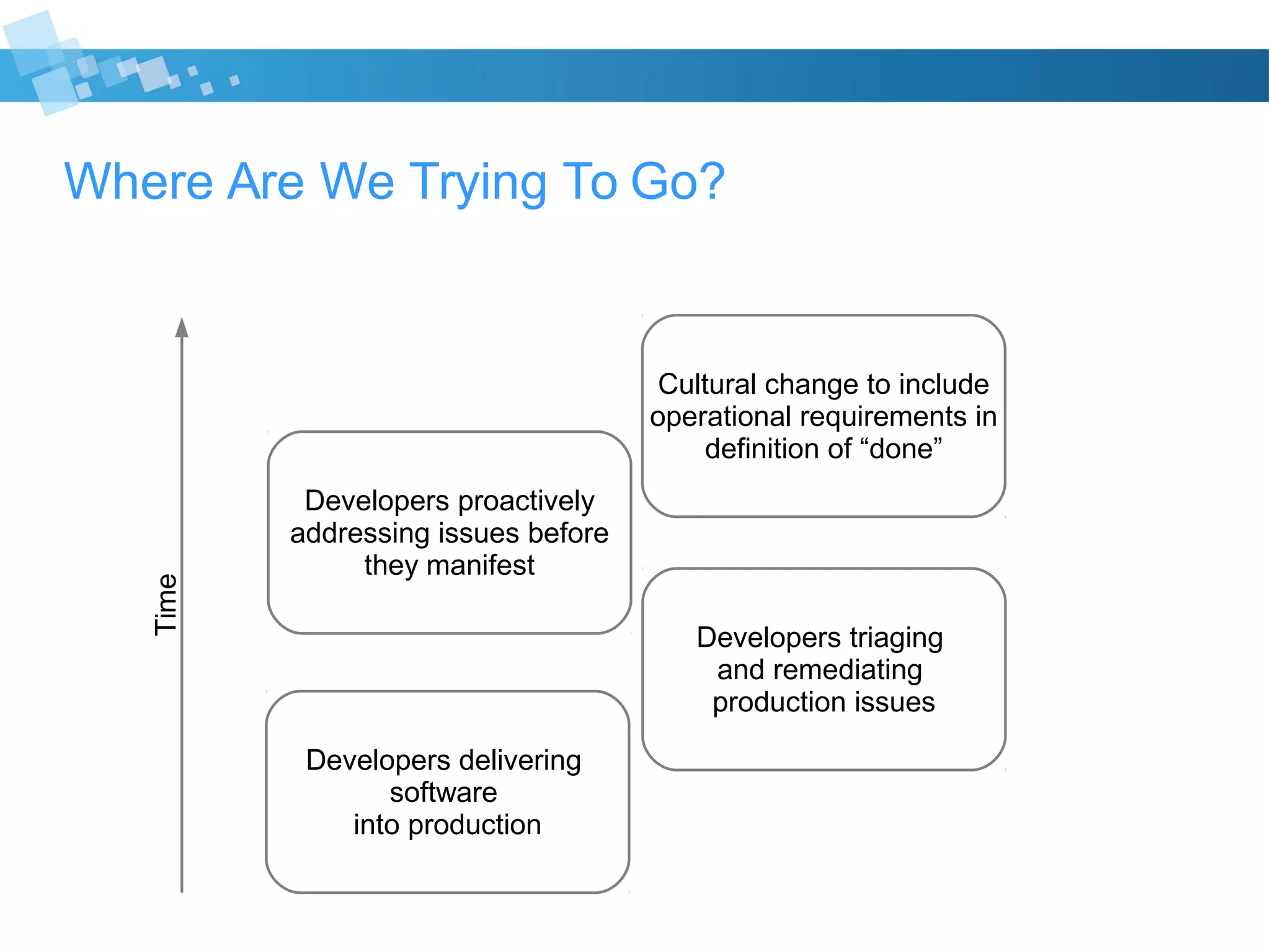
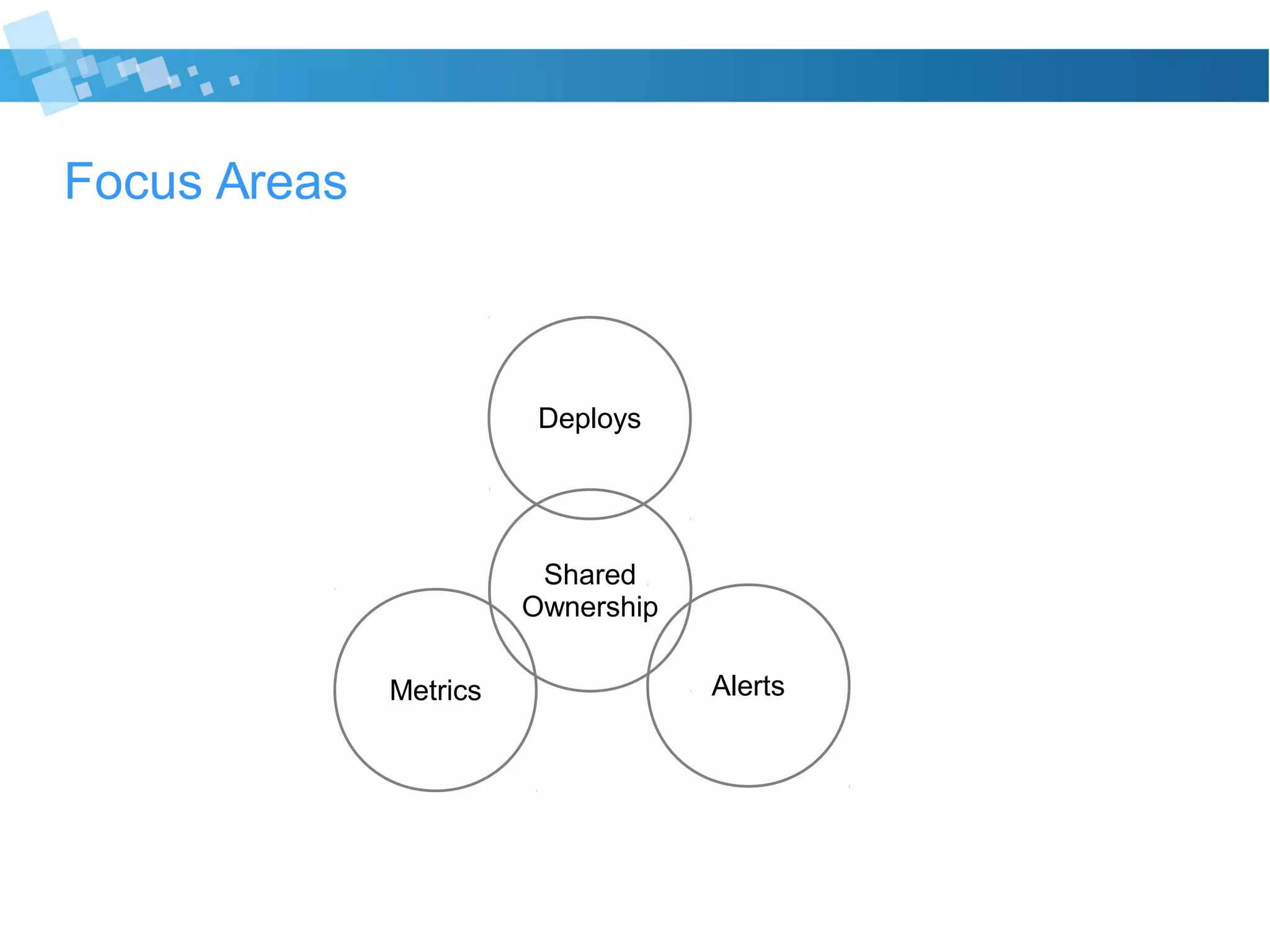
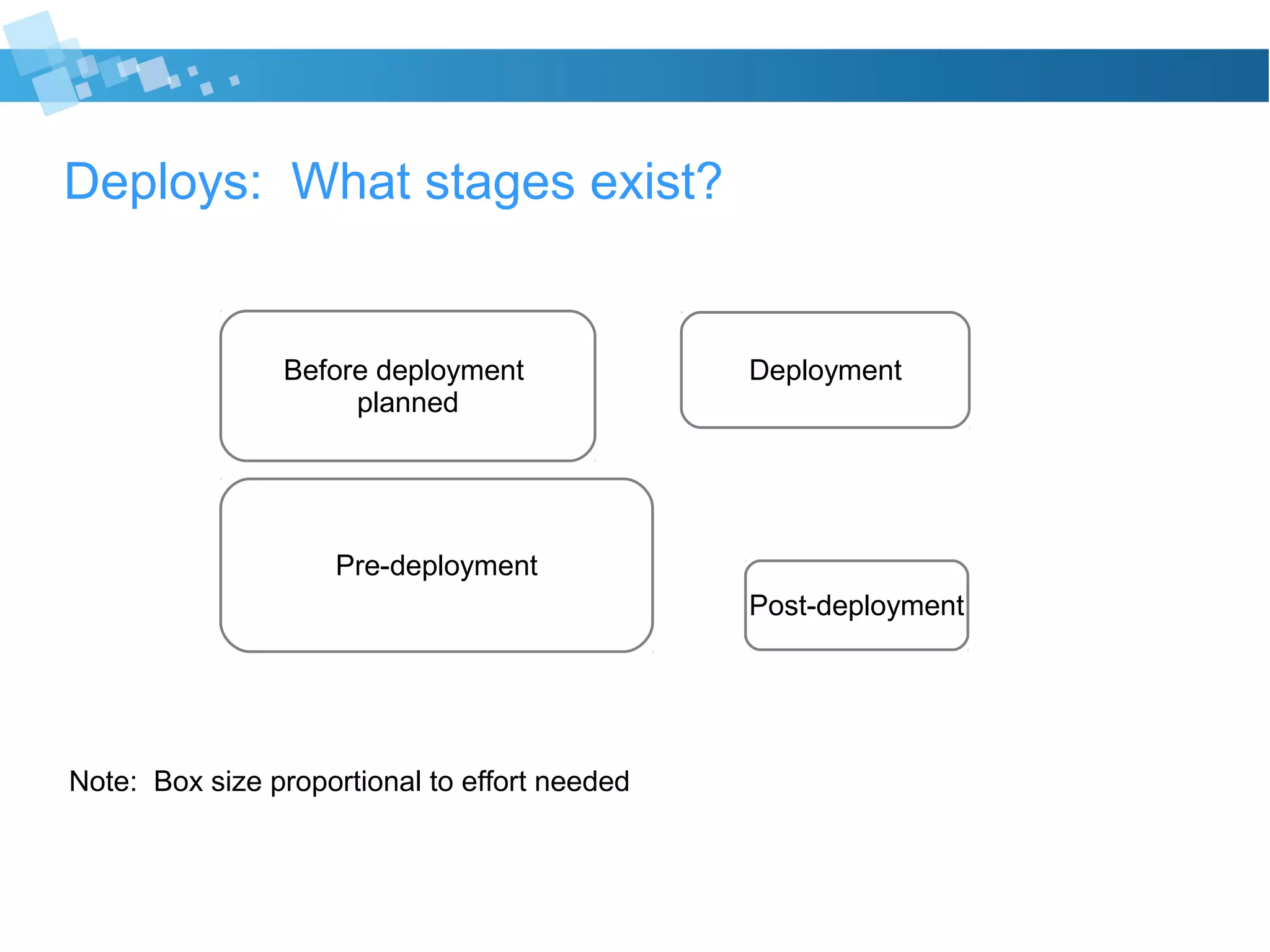
The document discusses best practices for developers transitioning to production ownership, emphasizing the importance of operational metrics, alerts, and deployment processes. It highlights the need for visibility into system performance, proactive issue resolution, and effective communication with non-technical stakeholders. Key focus areas include understanding system resource usage, managing alerts responsibly, and ensuring thorough pre-deployment planning to minimize risks.