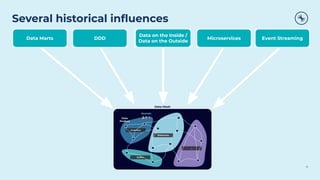
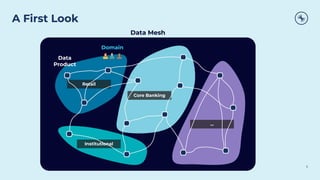
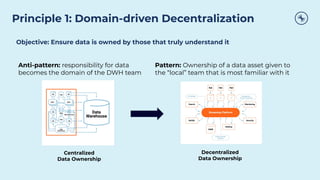
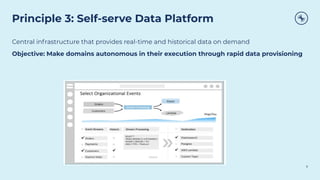
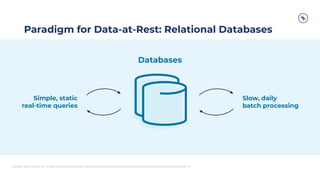
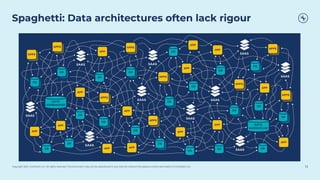
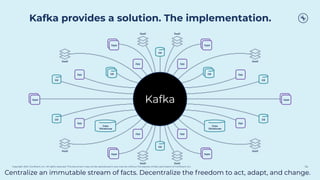
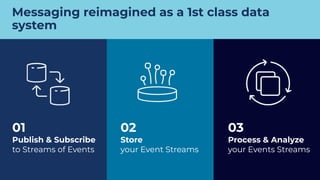
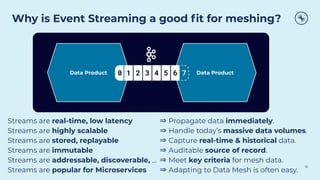
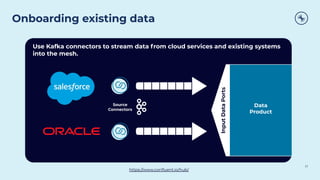
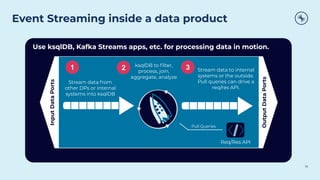
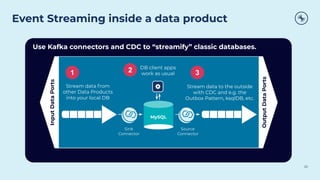
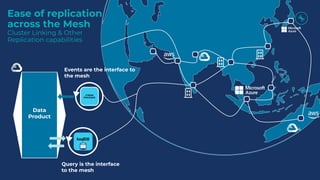
This document discusses how Apache Kafka and event streaming fit within a data mesh architecture. It provides an overview of the key principles of a data mesh, including domain-driven decentralization, treating data as a first-class product, a self-serve data platform, and federated governance. It then explains how Kafka's publish-subscribe event streaming model aligns well with these principles by allowing different domains to independently publish and consume streams of data. The document also describes how Kafka can be used to ingest existing data sources, process data in real-time, and replicate data across the mesh in a scalable and interoperable way.

































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











