Download as PDF, PPTX



![Tip #0
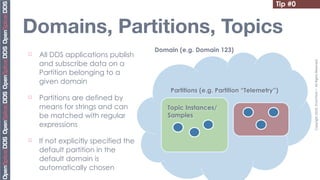
Partitions Matching
"building-1.floor-3.room-51"
Copyright
2010,
PrismTech
–
All
Rights
Reserved.
"building-1.floor-1.room-*"
... building-1.floor-3.room-5 ...
¨ Partitions are
defined by means building-1.floor-1.room-111 building-1.floor15-.room-51
for strings and can
be matched with building-1.floor-3.room-11
regular building-1.floor-1.room-1 building-1.floor-10.room-100
expressions] ...
"building-1.floor-*.room-11?" Domain](https://image.slidesharecdn.com/20tips-110728073104-phpapp01/85/20-Tips-for-OpenSplice-Newbies-4-320.jpg)







![Tip #3
Windows
The default maximum size for Shared Memory
Copyright
2010,
PrismTech
–
All
Rights
Reserved.
¨
segments on Windows is 2GB
¨ To exend it, say to 3GB, add the /3GB the boot.ini
as shown below:
[boot loader]
timeout=30
default=multi(0)disk(0)rdisk(0)partition(1)WINDOWS
[operating systems]
multi(0)disk(0)rdisk(0)partition
(1)WINDOWS="Windows NT
Workstation Version 4.00"
/3GB](https://image.slidesharecdn.com/20tips-110728073104-phpapp01/85/20-Tips-for-OpenSplice-Newbies-12-320.jpg)







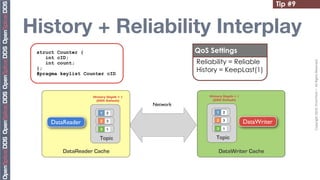


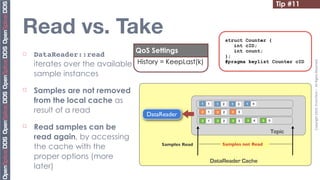
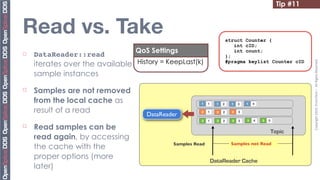
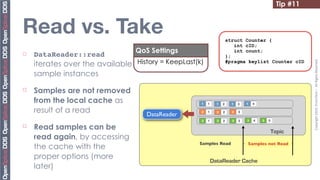
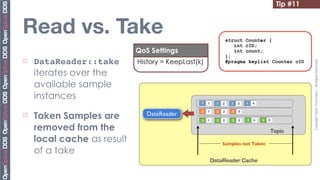
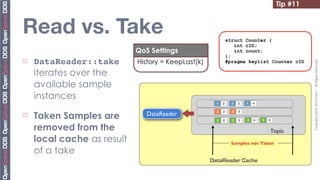
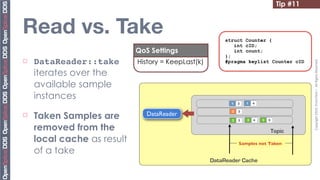










![Tip #19
Beware of Strings Ownership
¨ The DDS C++ API takes ownership of the string you pass
Copyright
2010,
PrismTech
–
All
Rights
Reserved.
¨ As a result, you need to understand when it is necessary
to “duplicate” a string
¨ To this end, DDS provides the DDS:string_dup call to
facilitate this task
subQos.partition.name.length (1);
subQos.partition.name[0] = DDS::string_dup (read_partition);](https://image.slidesharecdn.com/20tips-110728073104-phpapp01/85/20-Tips-for-OpenSplice-Newbies-50-320.jpg)



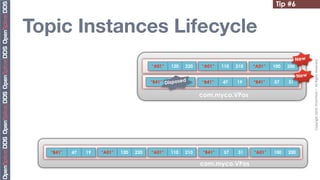
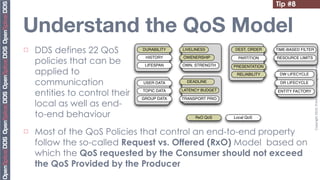
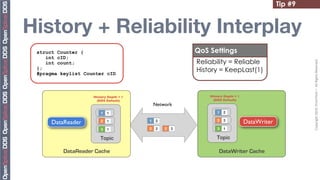
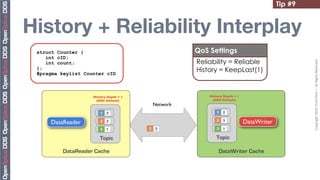
The document provides 20 tips for beginners using OpenSplice, focusing on the fundamentals of domains, partitions, and topics in DDS applications. Key insights include how to choose a domain, configure shared memory, and manage Quality of Service (QoS) settings effectively. Additionally, it emphasizes the importance of understanding lifecycle management and data access methods to enhance application performance.



































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)







