The document presents Shohei Higashiyama's doctoral defense on word segmentation and lexical normalization for unsegmented languages, specifically focusing on Japanese and Chinese. It summarizes various studies addressing segmentation accuracy in different domain types, the challenges of low-resource situations, and the need for effective models to handle user-generated text. Contributions include innovative approaches to improve segmentation accuracy, the construction of annotated corpora, and the evaluation of these methods against existing models.

![This slide is a slightly modified version of that used for the author’s
doctoral defense at NAIST on December 16, 2021.
The major contents of this slide were taken from the following papers.
• [Study 1] Higashiyama et al., “Incorporating Word Attention into Character-Based Word
Segmentation”, NAACL-HLT, 2019
https://www.aclweb.org/anthology/N19-1276
• [Study 1] Higashiyama et al., “Character-to-Word Attention for Word Segmentation”,
Journal of Natural Language Processing, 2020 (Paper Award)
https://www.jstage.jst.go.jp/article/jnlp/27/3/27_499/_article/-char/en
• [Study 2] Higashiyama et al., “Auxiliary Lexicon Word Prediction for Cross-Domain Word
Segmentation”, Journal of Natural Language Processing, 2020
https://www.jstage.jst.go.jp/article/jnlp/27/3/27_573/_article/-char/en
• [Study 3] Higashiyama et al., “User-Generated Text Corpus for Evaluating Japanese
Morphological Analysis and Lexical Normalization”, NAACL-HLT, 2021
https://www.aclweb.org/anthology/2021.naacl-main.438/
• [Study 4] Higashiyama et al., “A Text Editing Approach to Joint Japanese Word
Segmentation, POS Tagging, and Lexical Normalization”, W-NUT, 2021 (Best Paper Award)
https://aclanthology.org/2021.wnut-1.9/
2](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-2-2048.jpg)
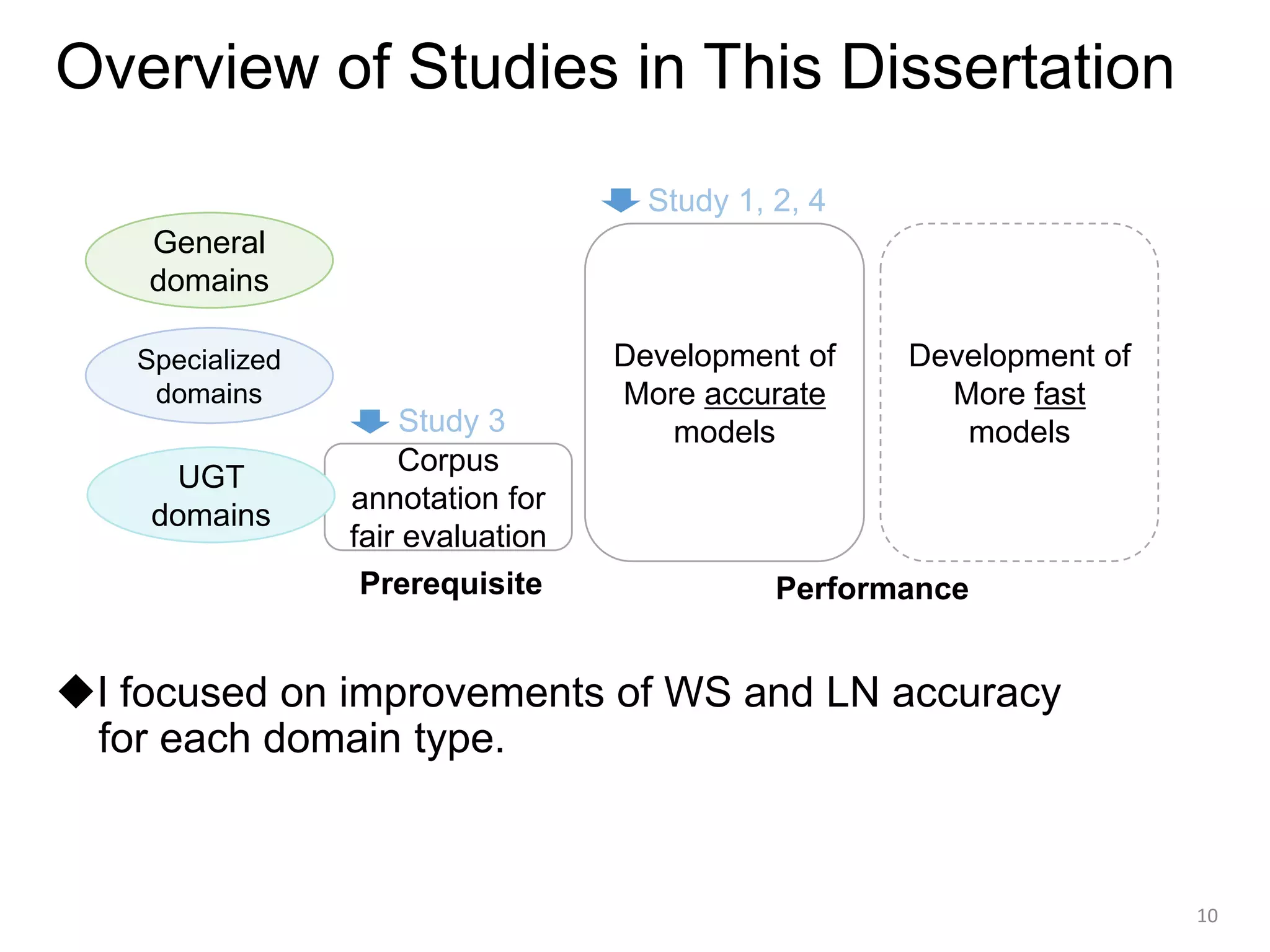
![Overview
◆Research theme
- Word Segmentation (WS) and
Lexical Normalization (LN) for Unsegmented Languages
◆Studies in this dissertation
[Study 1] Japanese/Chinese WS for general domains
[Study 2] Japanese/Chinese WS for specialized domains
[Study 3] Construction of Japanese user-generated text (UGT)
corpus for WS and LN
[Study 4] Japanese WS and LN for UGT domains
◆Structure of this presentation
- Background → Detail on each study → Conclusion
3](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-3-2048.jpg)


![Background (3/4)
◆Effective WS approaches for different domain types
- [Study 1] General domains:
Use of labeled data (and other resources)
- [Study 2] Specialized domains:
Use of general domain labeled data and target domain resources
- [Study 3&4] User-generated text (UGT):
Handling nonstandard words → Lexical normalization
6
Domain Type Example
Labeled
data
Unlabeled
data
Lexicon
Other
characteristics
General dom. News ✓ ✓ ✓
Specialized dom.
Scientific
documents
✕ ✓ △
UGT dom. Social media ✕ ✓ △
Nonstandard
words
✓: available
△: sometimes available
×: almost unavailable](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-6-2048.jpg)

![Contributions of This Dissertation (1/2)
1. How to achieve accurate WS in various text domains
- We proposed effective approach for each of three domain types.
➢Our methods can be effective options to achieve
accurate WS and downstream tasks in these domains.
8
General
domains
Specialized
domains
UGT
domains
[Study 1] Neural model combining
character and word features
[Study 2] Auxiliary prediction task based on
unlabeled data and lexicon
[Study 4] Joint prediction of WS and LN](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-8-2048.jpg)
![Contributions of This Dissertation (1/2)
2. How to train/evaluate WS and LN models for Ja UGT
- We constructed manually/automatically-annotated corpora.
➢Our evaluation corpus can be a useful benchmark to compare
and analyze existing and future systems.
➢Our LN method can be a good baseline to develop more
practical Japanese LN methods in future.
9
UGT
domains
[Study 3] Evaluation corpus annotation
[Study 4] Pseudo-training data generation](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-9-2048.jpg)


![[Study 1] Proposed Model Architecture
◆Char-based model with char-to-word attention
to learn the importance of candidate words
13
本
日本
本人
S S B E S
BiLSTM
Char
context
vector hi Word
embedding
ew
j
Word
summary
vector ai
Attend
Aggregate
Word vocab
Char embedding
Lookup
日本 ‘Japan’
本 ‘book’
本人 ‘the person’
?
Input sentence
BiLSTM
CRF
彼 は 日 本 人](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-13-2048.jpg)
![[Study 1] Character-to-Word Attention
14
本
日本
本人
は日本
日本人
本人だ
…
Word
embedding
ew
j
Word vocab
彼 は 日 本 人 だ 。
Char context
vector hi
αij ew
j
exp(hi
T Wew
j)
∑k exp(hi
T Wew
k)
αij =
Input sentence
Lookup
Attend
Max word length = 4
WAVG
(weighted
average)
WCON
(weighted
concat)
OR
Aggregate
…
Word summary vector ai](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-14-2048.jpg)
![15
Word vocab
BiLSTM-CRF
(baseline)
Training
set Unlabeled
text
Segmented
text
Train
Decode
…
…
…
Word
embeddings
Word2Vec
Pre-train Min word freq = 5
- Word vocabulary comprises training words and
words automatically segmented by the baseline.
[Study 1] Construction of Word Vocabulary](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-15-2048.jpg)
![[Study 1] Experimental Datasets
◆Training/Test data
- Chinese: 2 source domains
- Japanese: 4 source domains and 7 target domains
◆Unlabeled text for pre-training word embeddings
- Chinese: 48M sentences in Chinese Gigaword 5
- Japanese: 5.9M sentences in BCCWJ non-core data
16](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-16-2048.jpg)
![[Study 1] Experimental Settings
◆Hyperparameters
- num_BiLSTM_layers=2 or 3, num_BiLSTM_units=600,
char/word_emb_dim=300, min_word_freq=5, max_word_length=4, etc.
◆Evaluation
1. Comparison of baseline and proposed model variants
(and analysis on model size)
2. Comparison with existing methods on in-domain
and cross-domain datasets
3. Effect of semi-supervised learning
4. Effect of word frequency and length
5. Effect of attention for segmentation performance
6. Effect of additional word embeddings from target domains
7. Analysis of segmentation examples
17](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-17-2048.jpg)
![[Study 1] Exp 1. Comparison of Model Variants
◆F1 on development sets (mean of three runs)
- Word-integrated models outperformed BASE by up to 1.0
(significant in 20 of 24 cases).
- Attention-based models outperformed non-attention
counterparts in 10 of 12 cases (significant in 4 cases).
- WCON achieved the best performance,
which may be because of word length and char position info.
18
† significant at the 0.01 level over the baseline
‡ significant at the 0.01 level over the variant w/o attention
BiLSTM-CRF
Attention-
based](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-18-2048.jpg)
![[Study 1] Exp 2. Comparison with Existing Methods
◆F1 on test sets (mean of three runs)
- WCON achieved better/competitive performance than
existing methods.
(More recent work achieved further improvements on Chinese datasets.)
19](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-19-2048.jpg)
![20
[Study 1] Exp 5. Effect of Attention for Segmentation
本
本 日本
本人
本
本 日本
本人
0.1
0.1
0.8 0.1
0.1
0.8
if p≧pt if p<pt
p~Uniform(0,1)
◆Character-level accuracy on BCCWJ-dev
(Most frequent cases where both correct and incorrect candidate words
exist for a character)
- Segmentation label accuracy: 99.54%
- Attention accuracy for proper words: 93.25%
◆Segmentation accuracy of the trained model increased
for larger “correct attention probability” pt](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-20-2048.jpg)
![[Study 1] Conclusion
- We proposed a neural word segmenter with attention,
which incorporates word information into
a character-level sequence labeling framework.
- Our experiments showed that
• the proposed method, WCON, achieved performance better than or
competitive to existing methods, and
• learning appropriate attention weights contributed to accurate
segmentation.
21](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-21-2048.jpg)


![[Study 2] Cross-Domain WS with Linguistic Resources
◆Methods for Cross-Domain WS
◆Our Model
- To overcome the limitation of lexicon features,
we mode lexical information via auxiliary task for neural models.
➢Assumption:
24
(Liu+ 2019), (Gan+ 2019), Ours
Neural representation learning
Lexicon feature
Modeling Lexical Information
Modeling Statistical Information
Generating pseudo-labeled data
(Neubig+ 2011), (Zhang+ 2018)
Domain Labeled data Unlabeled data Lexicon
Source ✓ ✓ ✓
Target ✕ ✓ ✓](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-24-2048.jpg)
![[Study 2] Lexicon Feature
- Models cannot learn relationship b/w feature values and
segmentation labels in a target domain w/o labeled data.
25
週末の外出自粛要請
BESBEBEBE
Gold label
(self-restraint request in the weekend)
100111010
000000000
010011101
111111111
Sentence
Lexicon
features
Lexicon
[B]
[I]
[E]
[S]
長短期記憶ネットワーク
(Long short-term memory)
{週,末,の,外,出,自,粛,要,請,
週末,外出,出自,自粛,要請, …}
{長,短,期,記,憶,長短,短期,記憶,
ネット,ワーク,ネットワーク, …}
11010100100
00000011110
01101001001
11111000000
source sentence target sentence
Generate
?
Predict/Learn](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-25-2048.jpg)
![[Study 2] Our Lexicon Word Prediction
- We introduce auxiliary tasks to predict whether each character
corresponds to specific positions in lexical words.
- The model learns parameters also from target unlabeled sentences.
26
Seg label
Sentence
Auxiliary
labels
Lexicon
[B]
[I]
[E]
[S]
長短期記憶ネットワーク
{長,短,期,記,憶,長短,短期,記憶,
ネット,ワーク,ネットワーク, …}
11010100100
00000011110
01101001001
11111000000
Generate
Predict/Learn
Predict/
Learn
source sentence target sentence
Predict/Learn
週末の外出自粛要請
BESBEBEBE
(self-restraint request in the weekend)
{週,末,の,外,出,自,粛,要,請,
週末,外出,出自,自粛,要請, …}
(Long short-term memory)
100111010
000000000
010011101
111111111](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-26-2048.jpg)
![[Study 2] Methods and Experimental Data
◆Linguistic resources for training
- Source domain labeled data
- General and domain-specific unlabeled data
- Lexicon: UniDic (JA) or Jieba (ZH) and
semi-automatically constructed domain-specific lexicons
(390K-570K source words & 0-134K target words)
◆Methods
- Baselines: BiLSTM (BASE), BASE + self-training (ST), and
BASE + lexicon feature (LF)
- Proposed: BASE + MLPs for Segmentation and auxiliary LWP tasks
27
JNL: CS Journal; JPT, CPT: Patent; RCP: Recipe; C-ZX, P-ZX, FR, DL: Novel; DM: Medical](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-27-2048.jpg)
![[Study 2] Experimental Settings
◆Hyperparameter
- num_BiLSTM_layers=2, num_BiLSTM_units=600, char_emb_dim=300,
num_MLP_units=300, min_word_len=1, max_word_len=4, etc.
◆Evaluation
1. In-domain results
2. Cross-domain results
3. Comparison with SOTA methods
4. Influence of weight for auxiliary loss
5. Results for non-adapted domains
6. Performance of unknown words
28](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-28-2048.jpg)
![[Study 2] Exp 2. Cross-Domain Results
◆F1 on test sets (mean of three runs)
- LWP-S (source) outperformed BASE and ST.
- LWP-T (target) significantly outperformed the three baselines.
(+3.2 over BASE, +3.0 over ST, +1.2 over LF on average)
- Results of LWP-O (oracle) using gold test words
indicates more improvements by higher-coverage lexicons.
29
Japanese Chinese
★ significant at the 0.001 level over BASE
† significant at the 0.001 level over ST
‡ significant at the 0.001 level over LF](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-29-2048.jpg)
![[Study 2] Exp 3. Comparison with SOTA Methods
◆F1 on test sets
- Our method achieved better or competitive performance on
Japanese and Chinese datasets, compared to SOTA methods,
including Higashiyama+’19 (our method in the first study).
30
Japanese Chinese](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-30-2048.jpg)
![[Study 2] Exp 6. Performance for Unknown Words
◆Recall of top 10 frequent OOTV words
- For out-of-training-vocabulary (OOTV) words in test sets,
our method achieved better recall for words in lexicon,
but worse recall for words not in the lexicon (Ls∪Lt).
JPT (Patent) FR (Novel)
31
JA ZH](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-31-2048.jpg)
![[Study 2] Conclusion
- We proposed a cross-domain WS method to incorporate lexical
knowledge via an auxiliary prediction task.
- Our method achieved better performance for various target
domains than the lexicon feature baseline and existing methods
(while preventing performance degradation for source domains).
32](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-32-2048.jpg)


![[Study 3] Corpus Construction Policies
1. Available and restorable
- Use blog and Chiebukuro (Yahoo! Answers) sentences in
the BCCWJ non-core data and publish annotation information
2. Compatible with existing segmentation standard
- Follow the NINJAL’s SUW (short unit word, 短単位) and
extend the specification regarding non-standard words
3. Enabling a detailed evaluation on UGT-specific
phenomena
- Organize linguistic phenomena frequently observed
into several categories and
annotate every token with a category
35](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-35-2048.jpg)
![[Study 3] Example Sentence in Our Corpus
36
イイ歌ですねェ
Raw sentence
イイ 歌 です ねェ
形容詞 名詞 助動詞 助詞
良い,よい,いい - - ね
Char type - - Sound change
variant variant
ii uta desu nee ‘It’s a good song, isn’t it?’
Word boundary
Standard forms
desu
(copula)
nee
(emphasis marker)
Part-of-speech
Categories
ii
‘good’
uta
‘song’](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-36-2048.jpg)
![[Study 3] Corpus Details
◆Word categories
- 11 categories were defined for non-general or nonstandard words that
may often cause segmentation errors.
◆Corpus statistics
37
新語/スラング
固有名
オノマトペ
感動詞
方言
外国語
顔文字/AA
異文字種
代用表記
音変化
誤表記
Our most categories overlap with (Kaji+ 2015)’s classification](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-37-2048.jpg)
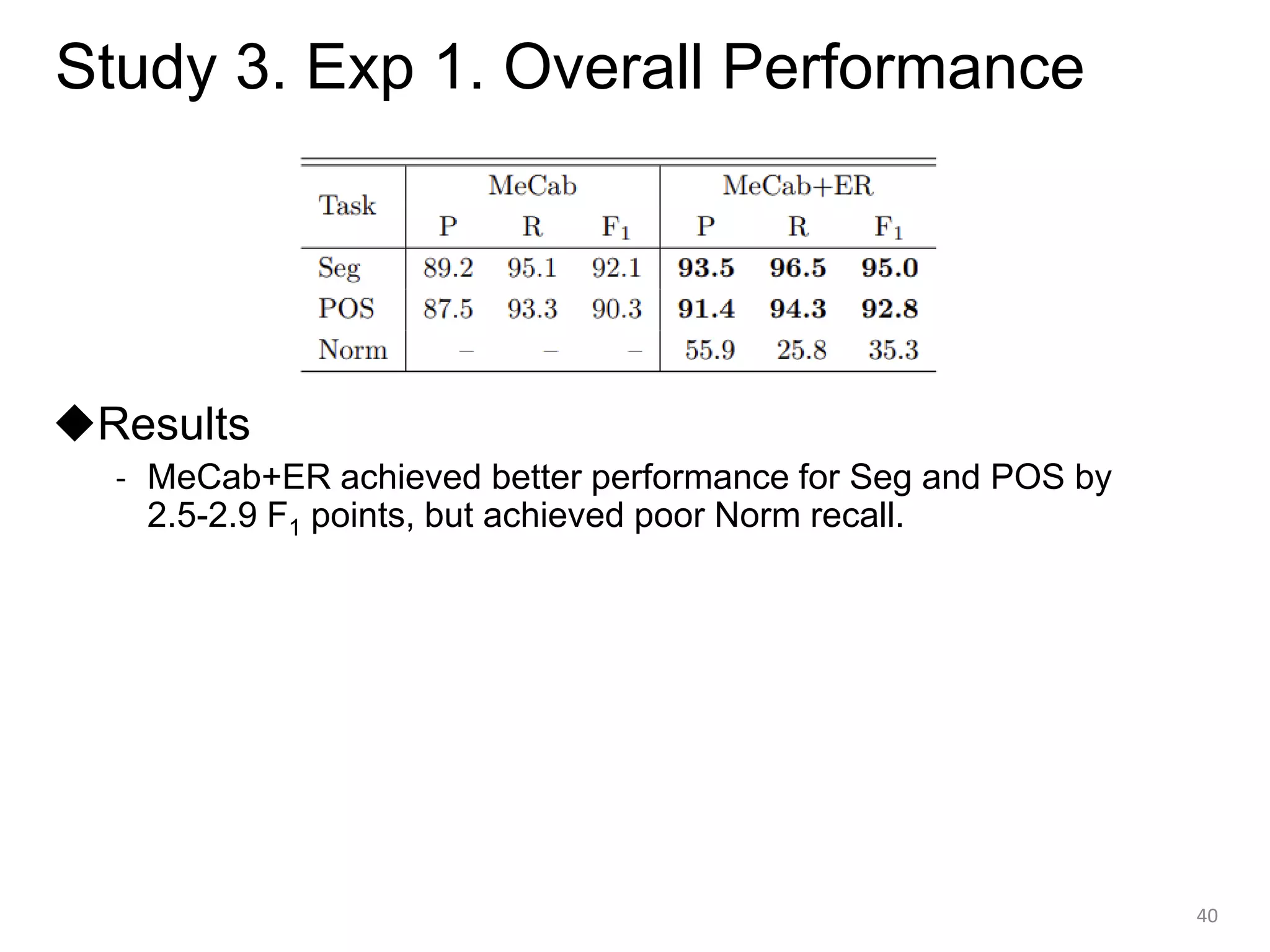
![[Study 3] Experiments
Using our corpus, we evaluated two existing systems
trained only with annotated corpus for WS and POS tagging.
• MeCab (Kudo+ 2004) with UniDic v2.3.0
- A popular Japanese morphological analyzer based on CRFs
• MeCab+ER (Expansion Rules)
- Our MeCab-based implementation of (Sasano+ 2013)’s
rule-based lattice expansion method
38
Cited from (Sasano+ 2014)
‘It was delicious.’
Dynamically add nodes
by human-crafted rules](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-38-2048.jpg)
![[Study 3] Experiments
◆Evaluation
1. Overall results
2. Results for each category
3. Analysis of segmentation results
4. Analysis of normalization results
39](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-39-2048.jpg)
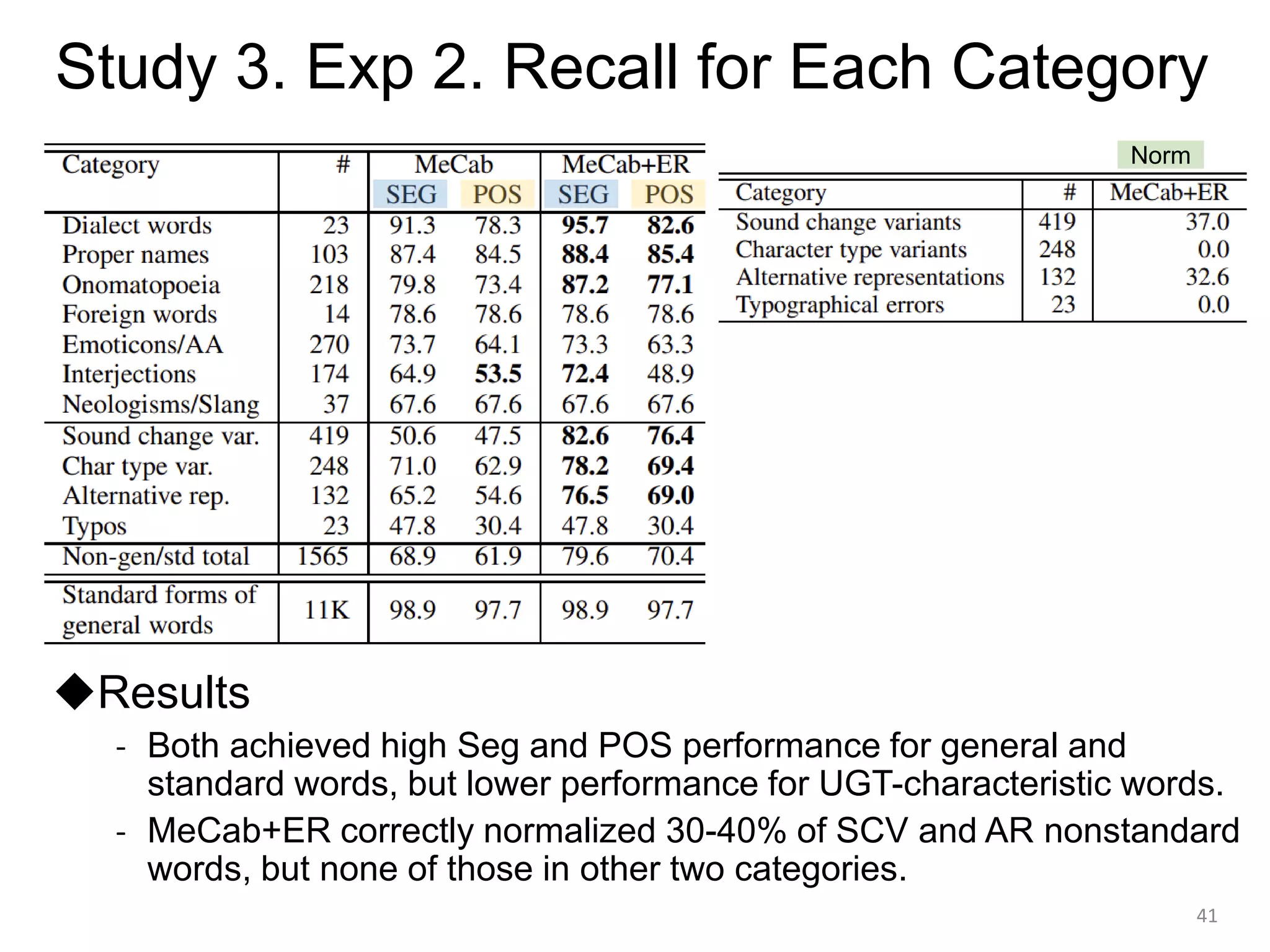
![[Study 3] Conclusion
- We constructed a public Japanese UGT corpus
annotated with morphological and normalization information.
(https://github.com/shigashiyama/jlexnorm)
- Experiments on the corpus demonstrated the limited performance
of the existing systems for non-general and non-standard words.
42](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-42-2048.jpg)


![[Study 4] Background and Motivation
◆Frameworks for text generation
◆Our approach
- Generate pseudo-labeled data for LN using lexical knowledge
- Use a text editing-based model to learn efficiently from
small amount of (high-quality) training data
45
⚫ Text editing method
for English lexical normalization
(Chrupała 2014)
⚫ Encoder-Decoder model
for Japanese sentence
normalization (Ikeda+ 2016)](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-45-2048.jpg)
![[Study 4] Task Formulation
◆Formulation as multiple sequence labeling tasks
◆Normalization tags for Japanese char sets
- String edit operation (SEdit):
{KEEP, DEL, INS_L(c), INS_R(c), REP(c)} (c: hiragana or katakana)
- Character type conversion (CConv): {KEEP, HIRA, KATA, KANJI}
◆Kana-kanji conversion
46
日 本 語 ま ぢ ム ズ カ シ ー
B E S B E B I I I E
Noun Noun Noun Adv Adv Adj Adj Adj Adj Adj
KEEP KEEP KEEP KEEP REP(じ) KEEP KEEP KEEP KEEP REP(い)
KEEP KEEP KEEP KEEP KEEP HIRA HIRA HIRA HIRA KEEP
x =
ys =
yp =
ye =
yc =
⇒ まじ ⇒ むずかしい
Seg
POS
Norm
Sentence
も う あ き だ
KANJI
Kana-kanji
converter
(n-gram LM)
あき
秋 ‘autumn’
空き ‘vacancy’
飽き ‘bored’
…
KANJI
’It’s already
autumn.’
KEEP
KEEP
KEEP
CConv tags](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-46-2048.jpg)
![[Study 4] Variant Pair Acquisition
◆Standard and nonstandard word variant pairs for
pseudo-labeled data generation
A) Dictionary-based:
Extract variant pairs from
UniDic with hierarchical
lemma definition
B) Rule-based:
Apply hand-crafted rules to transform standard forms into
nonstandard forms
47
…
⇒ 404K pairs
⇒ 47K pairs
6 out of 10 rules are similar to those in (Sasano+ 2013) and (Ikeda+ 2016).](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-47-2048.jpg)
![[Study 4] Pseudo-labeled Data Generation
◆Input
- (Auto-) segmented sentence x and
- Pair v of source (nonstandard) and target (standard) word variants
48
x = スゴく|気|に|なる
ye = K K K K K K K
yc = H H K K K K K
“(I’m) very curious.”
v = (スゴく, すごく)
ス ゴ く 気 に な る
K=KEEP,H=HIRA,
D=DEL, IR=INS_R
x = ほんとう|に|心配
ye = K K D K K K
yc = K K K K K K K
v = (ほんっと, ほんとう)
ほ ん っ と に 心 配
IR(う)
“(I’m) really worried.”
⇒ すごく 気になる
⇒ ほんとう に心配
⚫ Target-side distant supervision (DStgt)
⚫ Source-side distant supervision (DSsrc)
src tgt
src tgt
Synthetic target sentence
Synthetic source sentence
Pro: Actual sentences can be used
Pro: Any number of synthetic sentences can be generated](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-48-2048.jpg)
![[Study 4] Experimental Data
◆Pseudo labeled data for training (and development)
- Dict/Rule-derived variant pairs: Vd and Vr
- BCCWJ: a mixed domain corpus of news, blog, Q&A forum, etc.
◆Test data: BQNC
- Manually-annotated 929 sentences constructed in our third study
49
Du
Dt
Vd
Vd
At
Ad
DStgt
Vr Ar
57K sent.
173K syn. sent.
170K syn. sent.
57K sent.
Top np=20K
freq pairs At most ns=10 sent. were
extracted for each pair
DSsrc
core data Dt
with manual Seg&POS tags
non-core data Du
with auto Seg&POS tags
3.5M sent.](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-49-2048.jpg)
![[Study 4] Experimental Settings
◆Our model
- BiLSTM + task-specific softmax layers
- Character embedding, pronunciation embedding, and
nonstandard word lexicon binary features
- Hyperparameter
• num_BiLSTM_layers=2, num_BiLSTM_units=1,000, char_emb_d=200, pron_emb_d=30, etc.
◆Baseline methods
- MeCab and MeCab+ER (Sasano+ 2013)
◆Evaluation
1. Main results
2. Effect of dataset size
3. Detailed results of normalization
4. Performance for known and unknown normalization instances
5. Error analysis
50](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-50-2048.jpg)
![[Study 4] Exp 1. Main Results
◆Results
- Our method achieved better Norm performance
when trained on more types of pseudo-labeled data
- MeCab+ER achieved the best performance on Seg and POS
51
At: DSsrc(Vdic)
Ar: DStgt(Vrule)
Ad: DStgt(Vdic)
(BiLSTM)
Postprocessing](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-51-2048.jpg)
![[Study 4] Exp 5. Error Analysis
◆Detailed normalization performance
- Our method outperformed MeCab+ER for all categories.
- Major errors ( ) by our model were mis-detection and
invalid tag prediction.
- Kanji conversion accuracy was 97% (67/70).
52
ほんと (に少人数で) → ほんとう ‘actually’ すげぇ → すごい ‘great’
フツー (の話をして) → 普通 ‘ordinary’ そーゆー → そう|いう ‘such’
な~に (言ってんの) → なに ‘what’ まぁるい → まるい ‘round’
Examples
of TPs
ガコンッ → ガコン ‘thud’ ゴホゴホ → ごほごホ ‘coughing sound’
はぁぁ → はああ ‘sighing sound’ おお~~ → 王 ‘king’
ケータイ → ケイタイ ‘cell phone’ ダルい → だるい ‘dull’
Examples
of FPs ×
?](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-52-2048.jpg)
![[Study 4] Conclusion
- We proposed a text editing-based method for Japanese WS,
POS tagging, and LN.
- We proposed effective generation methods of pseudo-labeled data
for Japanese LN.
- The proposed method outperformed an existing method
on the joint segmentation and normalization task.
53](https://image.slidesharecdn.com/20211216higashiyamadd-211228030207/75/Word-Segmentation-and-Lexical-Normalization-for-Unsegmented-Languages-53-2048.jpg)







































![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)






























