More Related Content

PPTX

PDF
วิธีการสุ่มตัวอย่างและการเก็บรวบรวมข้อมูล 
PPT

PPTX

PPT
Research10 sample selection 
PPT

PDF
Probability sampling with known types 
PPT
Similar to 12 sampling

PDF
Sampling pattern - unknown 
PPT

PPT

PPT
ການກຳນົດກຸ່ມຕົວຢ່າງ ສຳຫຼັບສະຖິຕິການວິໄຈStatistics sampling 
PDF

PPTX

PPTX

PPTX

PPTX

PPT

PPT

PPT
Week 5 scale_and_measurement 
DOC

PPTX
Spc basic for training in thai 
PDF
วิชาโปรแกรมสำเร็จรูปทางสถิติเพื่อการวิจัย 
PPT
Sampling For Internal Auditors 
PPTX

PPTX

PDF

PDF
More from noinasang

PPTX

PDF

PDF

PPTX
17 การวัดการกระจายของข้อมูล 
PPTX
PPTX

PPTX

PPTX

PPTX

PPTX

PDF

PDF

PDF

PDF

PPTX
17 การวัดการกระจายของข้อมูล 
PPTX

PPTX

PPTX

PPTX

PPTX
12 sampling
- 1.
- 2.
- 3.
- 4.
- 5.
- ตารางเลขสุ่ม
862 245458 396 522 498 298 665 635 665 113 917
223 398 183 765 138 369 163 743 593 252 581 355
749 824 721 967 287 556 628 843 725 731 553 253
522 967 259 532 618 624 396 562 134 563 932 441
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
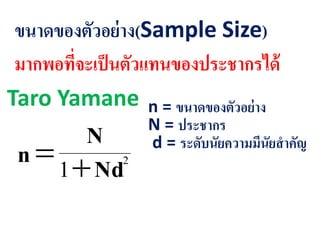
ตัวอย่าง ประชากร 500คน ต้องการความมีนัยสาคัญทาง
สถิติ .05 (ยอมรับให้เกิดความผิดพลาด 5 %)
2
1 Nd
N
n
2
055001
500
))(.(n
22222.n
กลุ่มตัวอย่าง คือ 223 คน