Downloaded 27 times





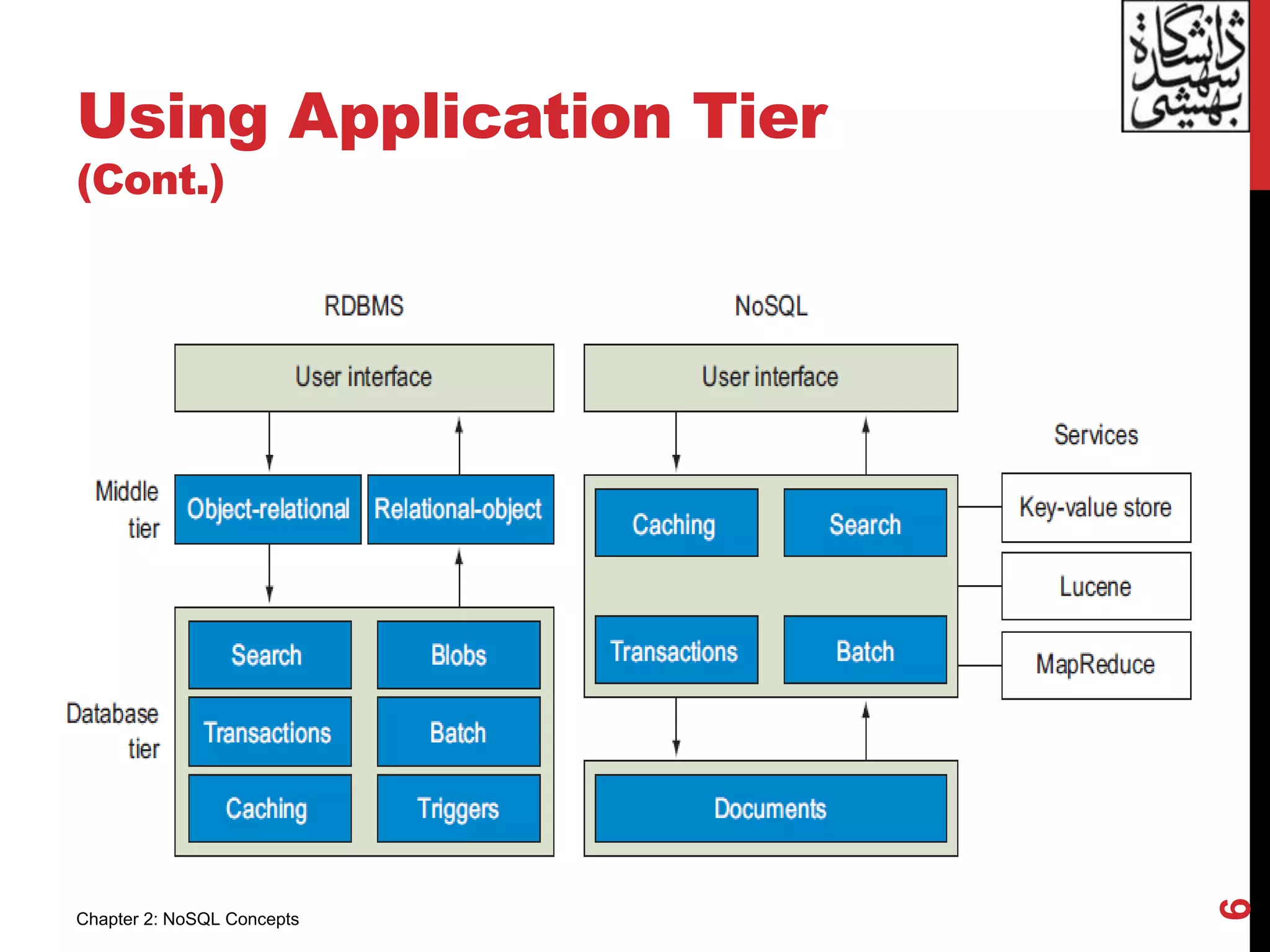























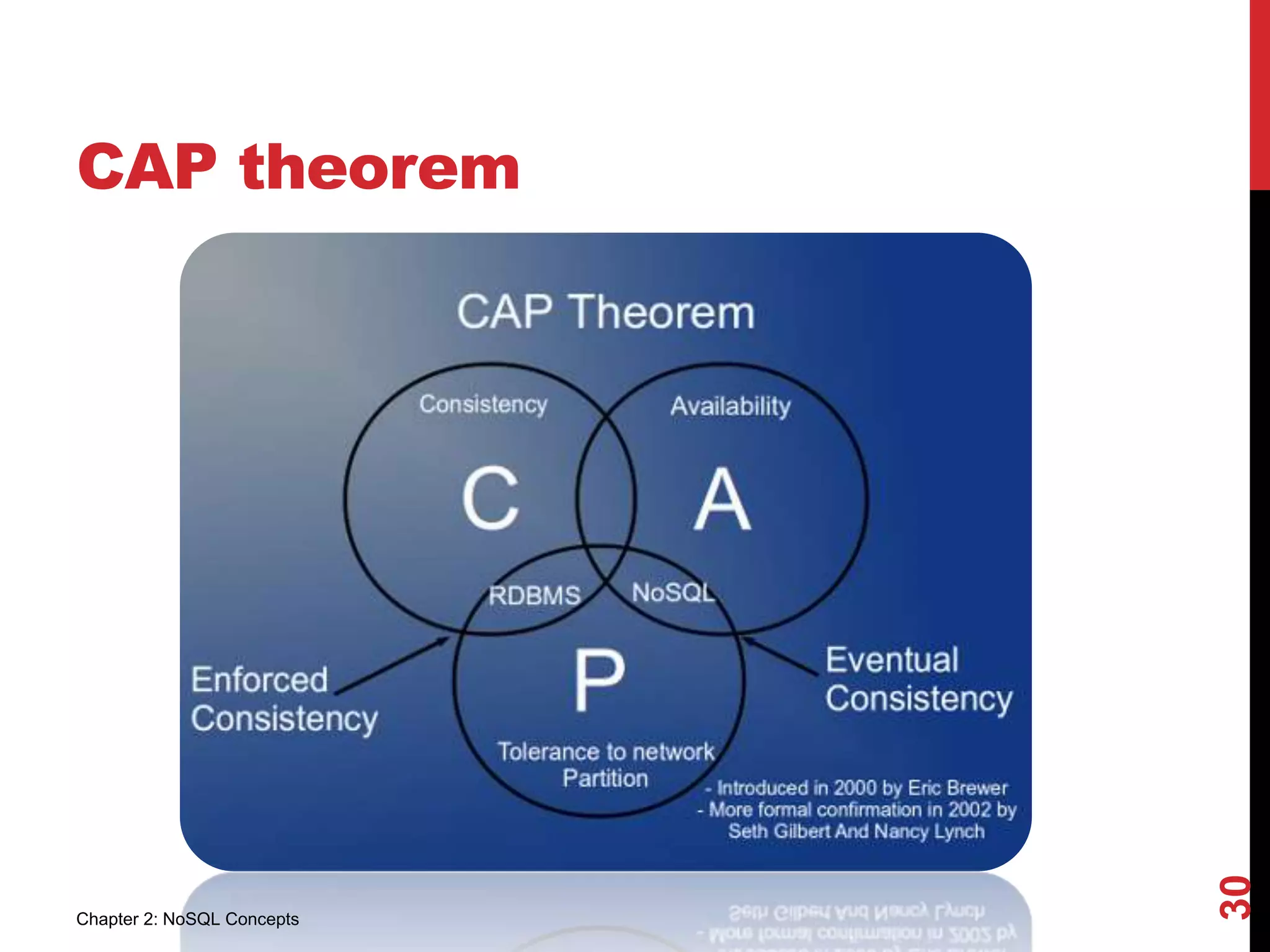


The document outlines key NoSQL concepts, emphasizing simplicity, application tier usage, performance enhancement, and the differences between ACID and BASE models. It discusses sharding for database scalability and the implications of Brewer’s CAP theorem on consistency, availability, and partition tolerance in distributed systems. Overall, it highlights the advantages and challenges of both traditional relational databases and NoSQL databases.










































































