Download as PDF, PPTX

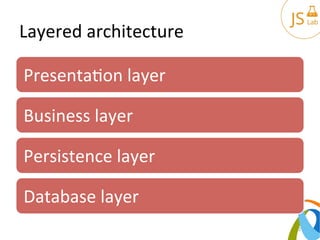









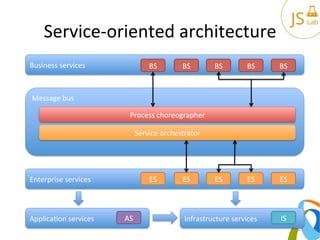










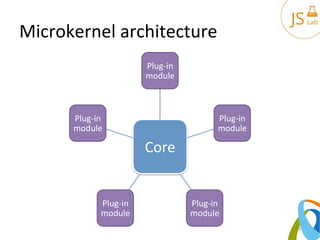








The document provides an overview of various architectural patterns including layered, event-driven, service-oriented, pipeline, microkernel, and space-based architectures. It discusses the characteristics, advantages, and implementation challenges of each pattern, emphasizing their applicability to different business models and requirements. The author also includes contact information and links for further reading.




![[WSO2Con EU 2017] Jump to the Next Curve with DevOps](https://cdn.slidesharecdn.com/ss_thumbnails/jumptothenextcurvewithdevopschamithedited-171107085752-thumbnail.jpg?width=640&height=640&fit=bounds)























































































