Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
Uploaded by
Hiroshi Shimizu
PDF, PPTX
13,340 views
glmmstanパッケージを作ってみた
glmmをstanで実行するためのパッケージを作りました。 lmer()と同じ文法でコードを書くと,簡単にMCMC推定できます。
Software
◦
Read more
18
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 71
2
/ 71
3
/ 71
4
/ 71
5
/ 71
6
/ 71
7
/ 71
8
/ 71
9
/ 71
10
/ 71
11
/ 71
12
/ 71
13
/ 71
14
/ 71
15
/ 71
16
/ 71
17
/ 71
18
/ 71
19
/ 71
20
/ 71
21
/ 71
22
/ 71
23
/ 71
24
/ 71
25
/ 71
26
/ 71
27
/ 71
28
/ 71
29
/ 71
30
/ 71
31
/ 71
32
/ 71
33
/ 71
34
/ 71
35
/ 71
36
/ 71
37
/ 71
38
/ 71
39
/ 71
40
/ 71
41
/ 71
42
/ 71
43
/ 71
44
/ 71
45
/ 71
46
/ 71
47
/ 71
48
/ 71
49
/ 71
50
/ 71
51
/ 71
52
/ 71
53
/ 71
54
/ 71
55
/ 71
56
/ 71
57
/ 71
58
/ 71
59
/ 71
60
/ 71
61
/ 71
62
/ 71
63
/ 71
64
/ 71
65
/ 71
66
/ 71
67
/ 71
68
/ 71
69
/ 71
70
/ 71
71
/ 71
More Related Content
PDF
階層ベイズとWAIC
by
Hiroshi Shimizu
PPTX
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
PPTX
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
PDF
Stanコードの書き方 中級編
by
Hiroshi Shimizu
PDF
階層モデルの分散パラメータの事前分布について
by
hoxo_m
PDF
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
PPTX
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
PDF
Tokyo r53
by
Hiroshi Shimizu
階層ベイズとWAIC
by
Hiroshi Shimizu
rstanで簡単にGLMMができるglmmstan()を作ってみた
by
Hiroshi Shimizu
MCMCでマルチレベルモデル
by
Hiroshi Shimizu
Stanコードの書き方 中級編
by
Hiroshi Shimizu
階層モデルの分散パラメータの事前分布について
by
hoxo_m
心理学におけるベイズ統計の流行を整理する
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング 1,2章
by
Miki Katsuragi
Tokyo r53
by
Hiroshi Shimizu
What's hot
PDF
Stan超初心者入門
by
Hiroshi Shimizu
PDF
順序データでもベイズモデリング
by
. .
PDF
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
PDF
Introduction to statistics
by
Kohta Ishikawa
PPT
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
PDF
統計学基礎
by
Yuka Ezura
Stan超初心者入門
by
Hiroshi Shimizu
順序データでもベイズモデリング
by
. .
エクセルで統計分析 統計プログラムHADについて
by
Hiroshi Shimizu
Introduction to statistics
by
Kohta Ishikawa
100614 構造方程式モデリング基本の「き」
by
Shinohara Masahiro
統計学基礎
by
Yuka Ezura
Similar to glmmstanパッケージを作ってみた
PDF
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
PDF
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
PDF
みどりぼん9章前半
by
Akifumi Eguchi
PDF
Tokyo r94 beginnerssession3
by
kotora_0507
PPTX
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
PDF
データ解析のための統計モデリング入門9章後半
by
Motoya Wakiyama
PDF
データ解析のための統計モデリング入門9章後半
by
Motoya Wakiyama
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
PDF
Stanの紹介と応用事例(age heapingの統計モデル)
by
. .
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
20190512 bayes hands-on
by
Yoichi Tokita
PPTX
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
PDF
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PPTX
MCMC and greta package社内勉強会用スライド
by
Shuma Ishigami
PDF
入門機械学習読書会二回目
by
Kazufumi Ohkawa
PDF
MLaPP 9章 「一般化線形モデルと指数型分布族」
by
moterech
PDF
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
PDF
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
一般化線形モデル (GLM) & 一般化加法モデル(GAM)
by
Deep Learning Lab(ディープラーニング・ラボ)
RStanとShinyStanによるベイズ統計モデリング入門
by
Masaki Tsuda
みどりぼん9章前半
by
Akifumi Eguchi
Tokyo r94 beginnerssession3
by
kotora_0507
心理学者のためのGlmm・階層ベイズ
by
Hiroshi Shimizu
データ解析のための統計モデリング入門9章後半
by
Motoya Wakiyama
データ解析のための統計モデリング入門9章後半
by
Motoya Wakiyama
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
データ解析のための統計モデリング入門 6.5章 後半
by
Yurie Oka
Stanの紹介と応用事例(age heapingの統計モデル)
by
. .
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
20190512 bayes hands-on
by
Yoichi Tokita
NagoyaStat#7 StanとRでベイズ統計モデリング(アヒル本)4章の発表資料
by
nishioka1
Stanでpsychophysics──階層ベイズモデルで恒常法データを分析する──【※Docswellにも同じものを上げています】
by
Hiroyuki Muto
パターン認識モデル初歩の初歩
by
t_ichioka_sg
MCMC and greta package社内勉強会用スライド
by
Shuma Ishigami
入門機械学習読書会二回目
by
Kazufumi Ohkawa
MLaPP 9章 「一般化線形モデルと指数型分布族」
by
moterech
データ解析のための統計モデリング入門-6章後半
by
yukit_cesc
データ解析のための統計モデリング入門10章前半
by
Shinya Akiba
More from Hiroshi Shimizu
PDF
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
PDF
Stanでガウス過程
by
Hiroshi Shimizu
PDF
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
PDF
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
PDF
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
PDF
媒介分析について
by
Hiroshi Shimizu
PDF
負の二項分布について
by
Hiroshi Shimizu
PDF
社会心理学とGlmm
by
Hiroshi Shimizu
PDF
Rで潜在ランク分析
by
Hiroshi Shimizu
PDF
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
PPTX
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
PPTX
Latent rank theory
by
Hiroshi Shimizu
PDF
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
PPTX
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
PPTX
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
PDF
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
PDF
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
PDF
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
PDF
Mplusの使い方 中級編
by
Hiroshi Shimizu
Cmdstanr入門とreduce_sum()解説
by
Hiroshi Shimizu
Stanでガウス過程
by
Hiroshi Shimizu
階層ベイズと自由エネルギー
by
Hiroshi Shimizu
StanとRでベイズ統計モデリング読書会 導入編(1章~3章)
by
Hiroshi Shimizu
SapporoR#6 初心者セッションスライド
by
Hiroshi Shimizu
媒介分析について
by
Hiroshi Shimizu
負の二項分布について
by
Hiroshi Shimizu
社会心理学とGlmm
by
Hiroshi Shimizu
Rで潜在ランク分析
by
Hiroshi Shimizu
エクセルで統計分析5 マルチレベル分析のやり方
by
Hiroshi Shimizu
Rで因子分析 商用ソフトで実行できない因子分析のあれこれ
by
Hiroshi Shimizu
Latent rank theory
by
Hiroshi Shimizu
エクセルでテキストマイニング TTM2HADの使い方
by
Hiroshi Shimizu
マルチレベルモデル講習会 実践編
by
Hiroshi Shimizu
マルチレベルモデル講習会 理論編
by
Hiroshi Shimizu
Excelでも統計分析 HADについて SappoRo.R#3
by
Hiroshi Shimizu
エクセルで統計分析2 HADの使い方
by
Hiroshi Shimizu
エクセルで統計分析4 因子分析のやり方
by
Hiroshi Shimizu
エクセルで統計分析3 回帰分析のやり方
by
Hiroshi Shimizu
Mplusの使い方 中級編
by
Hiroshi Shimizu
glmmstanパッケージを作ってみた
1.
glmmstanパッケージ を作ってみた 2015年11月14日 SapporoR #5 @simizu706
2.
自己紹介 • 清水裕士(@simizu706) – 関西学院大学社会学部 •
専門 – 社会心理学 • 趣味 – 心理統計,統計ソフト開発 – 最近はstanとか • Web: – http://norimune.net
3.
統計ソフトを作ってます • Excelで動く心理統計用ソフト – HAD –
「HAD」でググると一番上に出てきます。 – norimune.net/had
4.
注意 • 30分でスライド70枚超を疾走します – Lightning
Talk • あとでスライドシェアにアップするので それで確認してください • ネットがつながる人はダウンロードして みて,一度MCMCハァハァしてみてください
5.
結論 • glmmstanパッケージを作った – なんかいろんな線形モデルを簡単にMCMCで推定す ることができるglmmstan関数が入っている –
githubにあげているので使ってみてください – ただし,Rtoolsが必須なので事前に入れてください • インストール方法 library(devtools) install_github("norimune/glmmstan")
6.
インストール方法2 proxyによってgithubに接続できない場合は以下のコードを実 行してください library(devtools) library(httr) set_config(use_proxy(url="proxyのURL", port=8080, username = "ユーザーID", password
= "パスワード")) install_github("norimune/glmmstan")
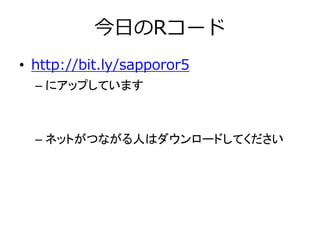
7.
今日のRコード • http://bit.ly/sapporor5 – にアップしています –
ネットがつながる人はダウンロードしてください
8.
今日のお話 • いろんな統計モデルをベイズ推定したい • glmmstanパッケージを作った •
glmmstanでベイズ推定してみた • まとめ
9.
今日のお話 • いろんな統計モデルをベイズ推定したい • glmmstanパッケージを作った •
glmmstanでベイズ推定してみた • まとめ
10.
さて,ベイズ推定したい • なぜベイズ推定なのか – いろいろいいことがあるから •
最小二乗法と比較して – 複雑なモデルを推定できる • 最尤法と比較して – より複雑なモデルを推定できる – 分散パラメータが不偏推定量になる 細かいことはいいから, とにかくベイズ推定したい!
11.
ベイズ推定といえばMCMC • マルコフ連鎖モンテカルロ法 – パラメータの推定を乱数を用いたシミュレーション で行う 細かいことはいいから, とにかくMCMC推定したい!
12.
RでのMCMCソフトウェア事情 • MCMCglmmパッケージ – 比較的簡単にGLMMをMCMCできる –
変量効果が複数あるとほぼ推定できない • rBUGS – コードを書けば,いろんなモデルを推定できる – 相関が高い変量効果の推定では,いつまでたっても収束 しないという事態がある(らしい) • rstanパッケージ – 複雑な階層ベイズのモデルでも早く収束する – NUTSという最新のMCMCアルゴリズムを使っている
13.
stanかわいいよstan • ベイズ推定(MCMC)用のフリーソフト – R上からでもrstanパッケージをいれると動かせる •
rstanパッケージのインストール – rstan2.7から簡単にインストールできる – ただしRtoolsが必要 – install.packages(“rstan”)で可能
14.
今日使うデータ • 野球のデータ – 2014年のプロ野球野手140名の打撃成績と翌年 の年俸 –
プロ野球Freakからダウンロードできる • http://baseball-freak.com/ • (ただし,年俸のデータはWikipediaから集めた) • glmmstanパッケージに入っている data(baseball)
15.
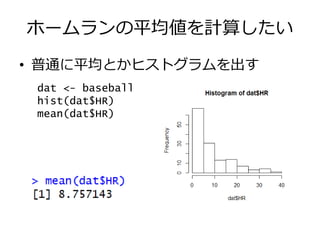
ホームランの平均値を計算したい • 普通に平均とかヒストグラムを出す dat <-
baseball hist(dat$HR) mean(dat$HR)
16.
平均値をrstanで計算したい • stanにおけるモデリング – データが正規分布だと仮定(無茶は承知 data{ real
HR[140]; } parameters{ real<lower=0> m; real<lower=0> s; } model{ HR ~ normal(m,s); } これぐらいなら簡単に書ける?
17.
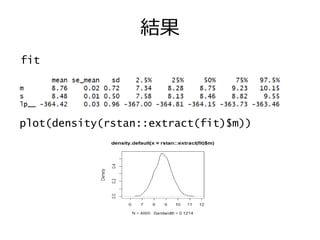
結果 plot(density(rstan::extract(fit)$m)) fit
18.
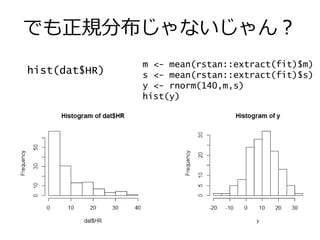
でも正規分布じゃないじゃん? hist(dat$HR) m <- mean(rstan::extract(fit)$m) s
<- mean(rstan::extract(fit)$s) y <- rnorm(140,m,s) hist(y)
19.
負の二項分布で平均値を計算 data{ int HR[140]; } parameters{ real<lower=0> m; real<lower=0>
s; } model{ HR ~ neg_binomial_2(m,s); } 負の二項分布 整数型
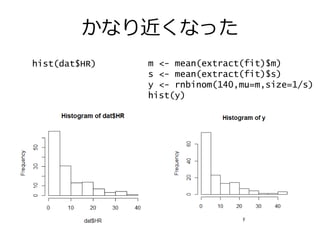
20.
かなり近くなった hist(dat$HR) m <-
mean(extract(fit)$m) s <- mean(extract(fit)$s) y <- rnbinom(140,mu=m,size=1/s) hist(y)
21.
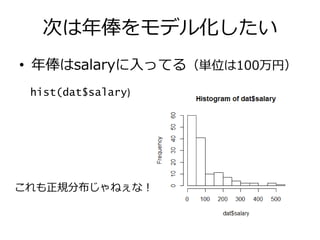
次は年俸をモデル化したい • 年俸はsalaryに入ってる(単位は100万円) これも正規分布じゃねぇな! hist(dat$salary)
22.
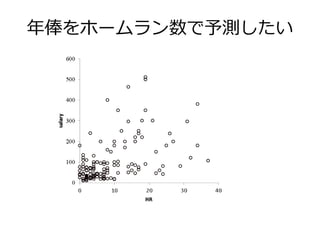
年俸をホームラン数で予測したい
23.
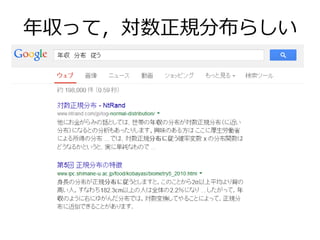
年収って,対数正規分布らしい
24.
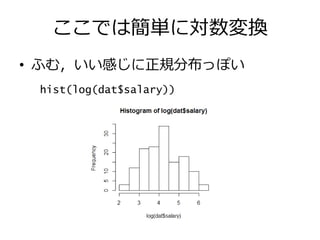
ここでは簡単に対数変換 • ふむ,いい感じに正規分布っぽい hist(log(dat$salary))
25.
lmを使う場合 model <- lm(log(salary)~HR,data=dat) plot(dat$HR,log(dat$salary)) abline(model)
26.
対数年俸をホームランで予測 • HR1本打つと年俸はどれぐらい上がる? data{ real salary[140]; real
HR[140]; } parameters{ real<lower=0> alpha; real<lower=0> beta; real<lower=0> s; } model{ real predict[140]; for(i in 1:140) predict[i] <- alpha+beta*HR[i]; salary ~ normal(predict,s); } お,おう,まだいけるかな・・
27.
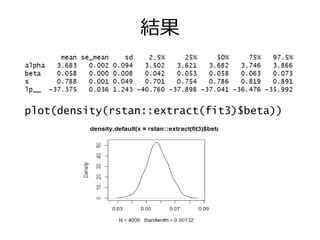
結果 plot(density(rstan::extract(fit3)$beta))
28.
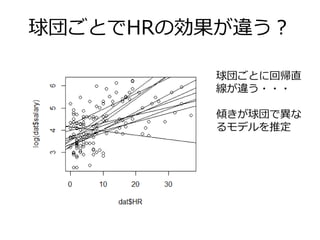
球団ごとでHRの効果が違う? 球団ごとに回帰直 線が違う・・・ 傾きが球団で異な るモデルを推定
29.
球団によってHRの効果が違う • 線形混合モデル – データがクラスタでネストされていて,クラスタ内 に相関がある場合に使える –
あるいは,回帰モデルがクラスタによって違うこと を考慮に入れられる • 階層ベイズを使う – 回帰係数自体が,正規分布に従うような階層的 なモデルを考える
30.
階層ベイズのstanコード data{ real salary[140]; real HR[140]; int
team[140]; } parameters{ real alpha; real beta[12]; real gamma; real<lower=0> s; real<lower=0> tau; } model{ real predict[140]; for(j in 1:12) beta[j] ~ normal(gamma,tau); for(i in 1:140) predict[i] <- alpha + beta[team[i]]*HR[i]; salary ~ normal(predict,s); }
31.
結果
32.
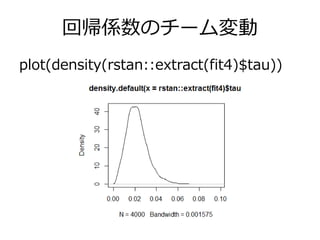
回帰係数のチーム変動 plot(density(rstan::extract(fit4)$tau))
33.
今日のお話 • いろんな統計モデルをベイズ推定したい • glmmstanパッケージを作った •
glmmstanでベイズ推定してみた • まとめ
34.
ベイズ推定をstanでやりたい • でもstanは初心者には敷居が高い – データの読み込みとそれに対応した変数の宣言 など,慣れないとぱっとさっとはできない •
Rのコードだけ書いて,ぱぱっとベイズ推 定したい – たとえば・・・glmer()と同じ書き方をしたらできる, みたいな。
35.
で,新しいパッケージを作った • glmmstanパッケージを作った – なんかいろんな線形モデルを簡単にMCMCで推 定することができるglmmstan関数が入っている –
githubにあげているので使ってみてください • インストール方法 library(devtools) install_github("norimune/glmmstan")
36.
GLMMってなんだっけ • Generalized Linear
Mixed Modeling – 一般化線形混合モデル – 線形モデル+指数分布族+変量効果 • どういうときにGLMMを使うのか? – データが離散分布に従うが,過分散が生じるとき • 個体差が大きい場合 – データがネストされた構造になっていて,グルー プごとに効果が異なるとき
37.
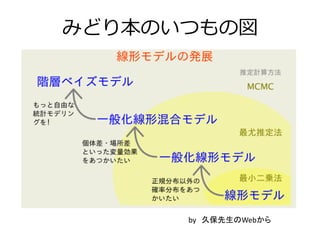
みどり本のいつもの図 by 久保先生のWebから
38.
GLMMができると・・ • 線形モデルは全部できる – t検定,重回帰分析,ロジスティック回帰,ポアソン回 帰,一般化線形モデル,階層線形モデル,Mixedモデ ル,一般化線形混合モデル •
glmmstanで遊んでみてください – いろんなモデルをベイズ推定してみる – 慣れてきたらstanコードを修正してみる – ハマってきたらstanコードを自分で書いてみる – 興奮してきたら新しい統計モデルを作ってみる
39.
glmmstanの特徴 • モデルを書くとstanコードを自動生成 – lm()や,glm(),そしてlmer()と同じようにモデルを書け ば,内部でstanコードを作成してstanを実効 •
モデル式は~を使って書くのはlm()と同じ – fit <- glmmstan(salary ~ HR, data=dat) • 階層ベイズはlmer()と同じ文法で書く – fit <- glmmstan(salary ~ HR+(1|team), data=dat)
40.
glmmstanの特徴 • 全てのモデルでWAICを出力 – 最尤法におけるAICのMCMC版 –
ただし,階層モデルの場合は局所パラメータを固 定効果として推定したWAICを出力 • このあたりはHijiyamaRで発表 • 比較的いろんな分布を扱える – 正規分布以外に,離散,連続様々
41.
使える分布とリンク関数 • 正規分布(”gaussian” or
“normal”) • ベルヌーイ分布(”bernoulli”)ロジットリンク • 二項分布(”binomial”) ロジットリンク • ポアソン分布(”poisson”) 対数リンク • 負の二項分布(”nbinomial”) 対数リンク • ガンマ分布(”gamma”) 対数リンク • 対数正規分布(”lognormal”) 対数リンク • ベータ分布(”beta”)ロジットリンク • 順序カテゴリカル(”ordered”)ロジットリンク
42.
備考 • リンク関数って? – 予測値をデータの分布に合わせて変換するもの •
基本は2種類 – 0未満にならない分布=対数リンク • ポアソン,負の二項分布,ガンマ,対数正規分布・・ – 下限と上限が決まってる分布=ロジットリンク • ベルヌーイ,二項分布,ベータ分布,順序・・
43.
glmmstanの特徴 • 交互作用項と単純効果の分析 – 交互作用項があるとき,スライス変数を指定する ことで単純効果の分析が可能 –
今のところ±1SDでスライス • オフセット項を追加できる – みどり本6章,「offset項わざ」を参照 – 今のところポアソンか負の二項分布のみ可
44.
今日のお話 • いろんな統計モデルをベイズ推定したい • glmmstanパッケージを作った •
glmmstanでベイズ推定してみた • まとめ
45.
まずは平均値を出してみたい • 正規分布を仮定したホームランの平均値 – モデル式 •
lm()形式。HR ~ 1で切片だけを推定ということ • 正規分布の場合はfamilyは省略できる library(glmmstan) data(baseball) dat <- baseball #ここではdatにいれなおしてる fit0 <- glmmstan(HR~1,data=dat)
46.
glmmstanを実行 • 並列化しないとき – cores
= 1を指定すると,並列化せず,チェインごとの 結果が表示される – PCによっては並列化できないことがある – その場合は,cores=1を加えること。 • 並列化するとき – 何も指定しないと,自動的にstanは並列化する (rstan2.7から) – その場合は同時にチェインを走らせるので出力はシ ンプル
47.
出力1 • output_result()で要約を出力 ※scaleとあるのは尺度パラメータ(残差分散)
48.
出力2 • output_stan()でstanの結果を返す – Rhatが1.05以下なら収束しているといわれている ※print()でも普通のstanの結果が出せるが,output_stan() のほうが必要な結果を見られる
49.
出力3 • MCMC要素を取り出すのはoutput_beta() – 回帰係数と尺度パラメータのMCMC要素をデータ フレーム型で返す
50.
出力4 • こんな感じ • MAP推定値が知りたい –
分布の密度が最大の値が知りたい時もある – そこで,map_mcmc()を用意してみた beta <- output_beta(fit0) plot(density(beta$Intercept))
51.
出力5 • もちろん他のパッケージを使うこともで きる – ggmcmc –
shinystan library(ggmcmc) library(ggmcmc) S <- ggs(fit0) ggs_density(S,family="beta")
52.
重回帰分析をしてみる • 年俸をHRと三振で予測する – 年俸をそのままモデルに投入 fit1
<- glmmstan(salary~HR+K,data=dat) output_result(fit1)
53.
分布を変えてみる • 対数正規分布を使い,年俸を予測 – familyを変えるだけ –
リンク関数は,自動的に決まる fit2 <- glmmstan(salary~HR+K,data=dat, family="lognormal")
54.
分布を変えてみる • ポアソン分布でHRの平均値を推定 fit3 <-
glmmstan(HR~1,data=dat, family="poisson")
55.
いろんなモデルを推定してみる • 球団によって回帰係数が違うモデル – 変量効果の指定 •
()を書いて,変量効果のモデルを指定 • |のあとにクラスタ変数を指定 • この場合,チームごとでHRの効果が違うモデルを推定 することを意味してる fit4 <- glmmstan(salary~HR+K+(HR|team), data=dat, family="lognormal")
56.
結果
57.
いろんなモデルを推定してみる • セリーグとパリーグで打率に差があるか – 二項分布を使って,打率を推定+過分散を変量 効果で推定 –
HITは安打数,ATbatsは打数 • これで打率を計算している – (1|player)で選手ごとの打率を推定 fit5 <- glmmstan(cbind(HIT,ATbats-HIT)~ league+(1|player), data=dat, family="binomial")
58.
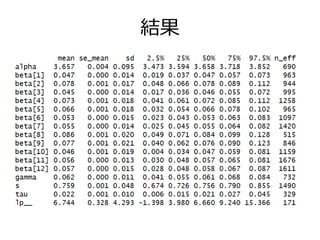
結果 • リーグで打率に差はなさそう – 若干セリーグのほうが高い
59.
stanコードを修正して分析したい • stanコードを指定すると優先的に分析 – stanコードだけを出力して,それを編集し,その コードで分析ができる code1
<- glmmstan(salary~HR+(1+HR|team), data=dat, family="lognormal", codeonly = TRUE) fit <- glmmstan(salary~HR+(1+HR|team), data=dat, family="lognormal", stancode = code1)
60.
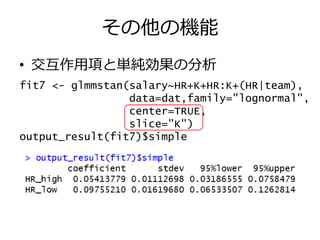
その他の機能 • 交互作用項と単純効果の分析 fit7 <-
glmmstan(salary~HR+K+HR:K+(HR|team), data=dat,family="lognormal", center=TRUE, slice="K") output_result(fit7)$simple
61.
その他の機能 • オフセット項を追加できる – 打席数に対するHRの割合の分布を検討したい –
今のところポアソンか負の二項分布の場合のみ ※Log()をつけなくてもいい fit8 <- glmmstan(HR~1+(1|player), data=dat, family="poisson", offset="ATbats")
62.
並列化処理 • stan2.7からデフォルトで並列化ができる – なにもしなくても勝手に並列化する •
Pglmmstan()を使っても並列化できる fit9 <- Pglmmstan(salary~HR+K+HR:K+(HR|team), data=dat, family="lognormal")
63.
stanに関する引数 • MCMCについての引数 – iter:サンプリング回数
デフォルトは2000 – warmup:バーンイン期間 デフォルトはiterの半分 – chains:マルコフ連鎖の数 デフォルトは2 – thin:何回おきに採用するか デフォルトは1 • stanにいれる便利な引数 – stancode:いじったstanコードを入力する – standata:いじったstanにいれるdataを入力する – stanmodel:コンパイル済みのモデルを入力する – stanfit:stanの出力を入力する(コンパイルを避ける)
64.
その他の引数 • Stanに入れるためのオブジェクトを返す – codeonly:
TRUEでstanコードだけを返す – dataonly: TRUEでstan用のデータだけを返す – modelonly: TRUEでコンパイル済みのモデルを返す • 推定のオプション – center: TRUEで説明変数を平均値で中心化する – slice: 単純効果をみるときのスライス変数を指定 – offset: オフセット項わざを使うときの変数を指定
65.
その他の引数 • 並列化に関する引数 – parallel:
TRUEで並列化 • ただし,Pglmmstan()を使うほうが楽 – cores:使用するコア数を指定する • デフォルトはchainsとおなじ
66.
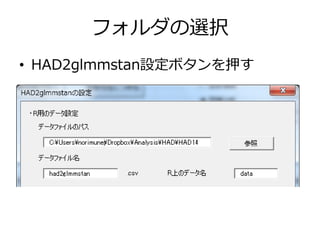
おまけ • HAD2glmmstan – HADからglmmstanのコードを自動生成する機能 –
HADとは・・・norimune.net/had • データファイルも自動作成 – 事前にデータファイルを保存するフォルダを選択 しておく • GUIでモデル選択をして実行 – するとglmmstan用のコードが出力される
67.
フォルダの選択 • HAD2glmmstan設定ボタンを押す
68.
HAD2glmmstan
69.
出力 • 別シートにコードが出力 – コピーしてRに貼り付けて実行
70.
インストール用のコードも生成
71.
Enjoy! @simizu706 http://norimune.net
Download













![平均値をrstanで計算したい
• stanにおけるモデリング
– データが正規分布だと仮定(無茶は承知
data{
real HR[140];
}
parameters{
real<lower=0> m;
real<lower=0> s;
}
model{
HR ~ normal(m,s);
}
これぐらいなら簡単に書ける?](https://image.slidesharecdn.com/glmmstan-151114073837-lva1-app6892/85/glmmstan-16-320.jpg)
![負の二項分布で平均値を計算
data{
int HR[140];
}
parameters{
real<lower=0> m;
real<lower=0> s;
}
model{
HR ~ neg_binomial_2(m,s);
}
負の二項分布
整数型](https://image.slidesharecdn.com/glmmstan-151114073837-lva1-app6892/85/glmmstan-19-320.jpg)

![対数年俸をホームランで予測
• HR1本打つと年俸はどれぐらい上がる?
data{
real salary[140];
real HR[140];
}
parameters{
real<lower=0> alpha;
real<lower=0> beta;
real<lower=0> s;
}
model{
real predict[140];
for(i in 1:140) predict[i] <- alpha+beta*HR[i];
salary ~ normal(predict,s);
}
お,おう,まだいけるかな・・](https://image.slidesharecdn.com/glmmstan-151114073837-lva1-app6892/85/glmmstan-26-320.jpg)

![階層ベイズのstanコード
data{
real salary[140];
real HR[140];
int team[140];
}
parameters{
real alpha;
real beta[12];
real gamma;
real<lower=0> s;
real<lower=0> tau;
}
model{
real predict[140];
for(j in 1:12) beta[j] ~ normal(gamma,tau);
for(i in 1:140) predict[i] <- alpha + beta[team[i]]*HR[i];
salary ~ normal(predict,s);
}](https://image.slidesharecdn.com/glmmstan-151114073837-lva1-app6892/85/glmmstan-30-320.jpg)




























































![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)




























