Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Kazufumi Ohkawa
2,036 views
入門機械学習読書会二回目
Technology
◦
Read more
3
Save
Share
Embed
Embed presentation
Download
Downloaded 24 times
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
7
/ 24
8
/ 24
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
Git
by
Appresso Engineering Team
PDF
)の品格
by
emasaka
PDF
Lisp tutorial for Pythonista : Day 1
by
Ransui Iso
PDF
ソースコードリーディングの基礎
by
hogemuta
PDF
Tokyo r6 sem3
by
osamu morimoto
PPTX
人工知能概論 11
by
Tadahiro Taniguchi
PPTX
RubySeminar16_Analyze
by
sady_nitro
PDF
分類器 (ナイーブベイズ)
by
Satoshi MATSUURA
Git
by
Appresso Engineering Team
)の品格
by
emasaka
Lisp tutorial for Pythonista : Day 1
by
Ransui Iso
ソースコードリーディングの基礎
by
hogemuta
Tokyo r6 sem3
by
osamu morimoto
人工知能概論 11
by
Tadahiro Taniguchi
RubySeminar16_Analyze
by
sady_nitro
分類器 (ナイーブベイズ)
by
Satoshi MATSUURA
Similar to 入門機械学習読書会二回目
PDF
Sakusaku svm
by
antibayesian 俺がS式だ
PDF
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
PPTX
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
PDF
20191117_choco_bayes_pub
by
Yoichi Tokita
PDF
パターン認識 04 混合正規分布
by
sleipnir002
PDF
トピックモデル3.1節
by
Akito Nakano
PDF
3.1節 統計的学習アルゴリズム
by
Akito Nakano
PDF
第1回 Jubatusハンズオン
by
JubatusOfficial
PDF
第1回 Jubatusハンズオン
by
Yuya Unno
PDF
集合知プログラミング勉強会 7章(前半)
by
koba cky
PPTX
RでKaggleの登竜門に挑戦
by
幹雄 小川
PPTX
20170707 rでkaggle入門
by
Nobuaki Oshiro
PPTX
0610 TECH & BRIDGE MEETING
by
健司 亀本
PDF
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
PDF
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
PDF
no_bayes_no_life_nb_keep_evolving
by
phyllo
PPTX
30分でわかる『R』によるデータ分析|データアーティスト
by
Satoru Yamamoto
PPTX
R超入門機械学習をはじめよう
by
幹雄 小川
PDF
R による文書分類入門
by
Takeshi Arabiki
PDF
データに隠れた構造を推定して予測に活かす 〜行列分解とそのテストスコアデータへの応用〜
by
Atsunori Kanemura
Sakusaku svm
by
antibayesian 俺がS式だ
SappoRo.R #2 初心者向けWS資料
by
考司 小杉
StanとRでベイズ統計モデリングに関する読書会(Osaka.stan) 第四章
by
nocchi_airport
20191117_choco_bayes_pub
by
Yoichi Tokita
パターン認識 04 混合正規分布
by
sleipnir002
トピックモデル3.1節
by
Akito Nakano
3.1節 統計的学習アルゴリズム
by
Akito Nakano
第1回 Jubatusハンズオン
by
JubatusOfficial
第1回 Jubatusハンズオン
by
Yuya Unno
集合知プログラミング勉強会 7章(前半)
by
koba cky
RでKaggleの登竜門に挑戦
by
幹雄 小川
20170707 rでkaggle入門
by
Nobuaki Oshiro
0610 TECH & BRIDGE MEETING
by
健司 亀本
2013.07.15 はじパタlt scikit-learnで始める機械学習
by
Motoya Wakiyama
2013 JOI春合宿 講義6 機械学習入門
by
Hiroshi Yamashita
no_bayes_no_life_nb_keep_evolving
by
phyllo
30分でわかる『R』によるデータ分析|データアーティスト
by
Satoru Yamamoto
R超入門機械学習をはじめよう
by
幹雄 小川
R による文書分類入門
by
Takeshi Arabiki
データに隠れた構造を推定して予測に活かす 〜行列分解とそのテストスコアデータへの応用〜
by
Atsunori Kanemura
More from Kazufumi Ohkawa
PDF
QMの城(FMOを使おう)/MIshimasyk_22_fmkz_pub.pdf
by
Kazufumi Ohkawa
PDF
圏論walker
by
Kazufumi Ohkawa
PPTX
ハッピーハッピー構造生成まつり’67
by
Kazufumi Ohkawa
PPTX
ClickでCLIをお手軽につくるぅぅぅ
by
Kazufumi Ohkawa
PPTX
SAR精度70% その先へ
by
Kazufumi Ohkawa
PPTX
視覚化サービス構築の際に気をつけること
by
Kazufumi Ohkawa
PPTX
量子化学計算外伝 すごいよ!! FMO
by
Kazufumi Ohkawa
PDF
あまり知られていない静岡の言語戦争の歴史
by
Kazufumi Ohkawa
PDF
IPython notebookを使おう
by
Kazufumi Ohkawa
PPTX
Mishimasyk141025
by
Kazufumi Ohkawa
PPTX
実践コンピュータビジョン8章
by
Kazufumi Ohkawa
PPTX
R -> Python
by
Kazufumi Ohkawa
PDF
ChEMBLを使おう
by
Kazufumi Ohkawa
PDF
Unigram mixtures
by
Kazufumi Ohkawa
PDF
エンジョイ☆スクレイピング
by
Kazufumi Ohkawa
PDF
Redmineでもめない会議☆
by
Kazufumi Ohkawa
PDF
pythonでオフィス快適化計画
by
Kazufumi Ohkawa
PDF
入門機械学習読書会9章
by
Kazufumi Ohkawa
PPTX
入門機械学習6章
by
Kazufumi Ohkawa
PDF
Javascriptを書きたくないヒ トのためのPythonScript
by
Kazufumi Ohkawa
QMの城(FMOを使おう)/MIshimasyk_22_fmkz_pub.pdf
by
Kazufumi Ohkawa
圏論walker
by
Kazufumi Ohkawa
ハッピーハッピー構造生成まつり’67
by
Kazufumi Ohkawa
ClickでCLIをお手軽につくるぅぅぅ
by
Kazufumi Ohkawa
SAR精度70% その先へ
by
Kazufumi Ohkawa
視覚化サービス構築の際に気をつけること
by
Kazufumi Ohkawa
量子化学計算外伝 すごいよ!! FMO
by
Kazufumi Ohkawa
あまり知られていない静岡の言語戦争の歴史
by
Kazufumi Ohkawa
IPython notebookを使おう
by
Kazufumi Ohkawa
Mishimasyk141025
by
Kazufumi Ohkawa
実践コンピュータビジョン8章
by
Kazufumi Ohkawa
R -> Python
by
Kazufumi Ohkawa
ChEMBLを使おう
by
Kazufumi Ohkawa
Unigram mixtures
by
Kazufumi Ohkawa
エンジョイ☆スクレイピング
by
Kazufumi Ohkawa
Redmineでもめない会議☆
by
Kazufumi Ohkawa
pythonでオフィス快適化計画
by
Kazufumi Ohkawa
入門機械学習読書会9章
by
Kazufumi Ohkawa
入門機械学習6章
by
Kazufumi Ohkawa
Javascriptを書きたくないヒ トのためのPythonScript
by
Kazufumi Ohkawa
入門機械学習読書会二回目
1.
第2回入門機械学習 読書会 2013.04.27 @kzfm
2.
準備 ! R !
http://www.r-project.org/ ! Rstudio ! http://www.rstudio.com/ ! サンプルコード ! https://github.com/johnmyleswhite/ ML_for_Hackers ! source( package_installer.R )を実行 > setwd("/Users/kzfm/lang/rcode/ML_̲for_̲Hackers/") > source("package_̲installer.R")
3.
私とR @kzfm (http://blog.kzfmix.com/) 医療統計からテキストマイニングまで幅広くこなす
4.
ファイル読み込み ! 前回の反省 !
setwdでwdを変更しないで、getwdで表示さ れるwdに必要なファイルを移動させて読み込む という方法でもいいかも
5.
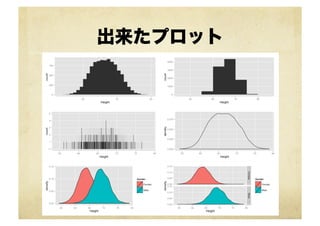
2-9から library(ggplot2) library(gridExtra) setwd("~∼/lang/rcode/ML_̲for_̲Hackers/02-‐‑‒Exploration/")
heights.weights <-‐‑‒ read.csv("data// 01_̲heights_̲weights_̲genders.csv", header=TRUE, sep=',') g <-‐‑‒ ggplot(heights.weights, aes(x=Height)) g1 <-‐‑‒ g + geom_̲histogram(binwidth=1) g2 <-‐‑‒ g + geom_̲histogram(binwidth=5) g3 <-‐‑‒ g + geom_̲histogram(binwidth=0.001) g4 <-‐‑‒ g + geom_̲density() g5 <-‐‑‒ g + geom_̲density(aes(fill=Gender)) g6 <-‐‑‒ g5 + facet_̲grid(Gender ~∼ .) grid.arrange(g1, g2, g3, g4, g5, g6, ncol=2, nrow=3) ! install.packages(gridExtra)する
6.
出来たプロット
7.
ヒストグラムの注意点 ! binの幅で見た目が変わる !
適切な幅を決めるのは難しい ! 単峰なのか多峰なのか掴みづらいことが多い ! 密度プロットを併用しよう
8.
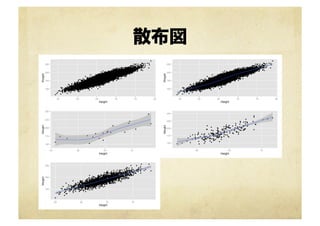
散布図を描く h <-‐‑‒ ggplot(heights.weights,
aes(x=Height, y=Weight)) h1 <-‐‑‒ h + geom_̲point() h2 <-‐‑‒ h1 + geom_̲smooth() h3 <-‐‑‒ ggplot(heights.weights[1:20,], aes(x=Height, y=Weight)) + geom_̲point() + geom_̲smooth() h4 <-‐‑‒ ggplot(heights.weights[1:200,], aes(x=Height, y=Weight)) + geom_̲point() + geom_̲smooth() h5 <-‐‑‒ ggplot(heights.weights[1:2000,], aes(x=Height, y=Weight)) + geom_̲point() + geom_̲smooth() grid.arrange(h1, h2, h3, h4, h5, ncol=2, nrow=3) ! 散布図
9.
散布図
10.
5章でやるので飛ばす c <-‐‑‒ coef(logit.mode)
ggplot(height.weights, aes(x = Weight, y=Height, color=Gender)) + geom_̲point() + stat_̲abline(intercept = -‐‑‒c[1]/c[2], slope=-‐‑‒c[3]/c[2], geom='abline', color='black')
11.
3章 スパムフィルタ ベイズ分類
12.
教師あり/なし学習 ! 教師あり学習(きょうしありがくしゅう, Supervised
learning)とは、機械学習の手 法の一つである ! 事前に与えられたデータをいわば「例題(=先 生からの助言)」とみなして、それをガイドに 学習(=データへの何らかのフィッティング) を行うところからこの名がある。 ! wikipediaより
13.
サイコロを振る ! 6面体(A)と8面体(B)の サイコロを振る !
同時に振って両方3が出 る確率 ! Aで3が出た状態でBが 3になる確率 ! Bで3が出た状態でAが 3になる確率
14.
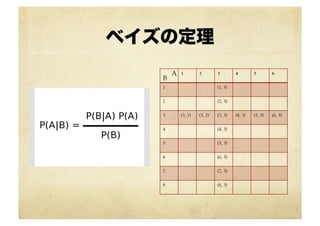
ベイズの定理 1 2 3
4 5 6 1 (1, 3) 2 (2, 3) 3 (3, 1) (3, 2) (3, 3) (4, 3) (5, 3) (6, 3) 4 (4, 3) 5 (5, 3) 6 (6, 3) 7 (7, 3) 8 (8, 3) B A
15.
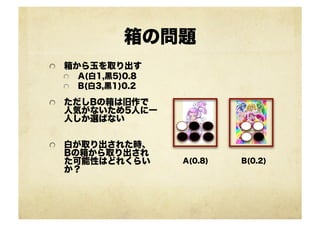
箱の問題 ! 箱から玉を取り出す !
A(白1,黒5)0.8 ! B(白3,黒1)0.2 ! ただしBの箱は旧作で 人気がないため5人に一 人しか選ばない ! 白が取り出された時、 Bの箱から取り出され た可能性はどれくらい か? A(0.8) B(0.2)
16.
ベイズの定理を使う ! P(B¦白)
= P(白¦B) x P(B) / P(白) = 0.75 * 0.2 / 0.4 = 0.375 • もともとBが選ばれる確率が20%だったのが、 白が観察されたことで37.5%に上昇した • 箱から取り出す確率が変化する不思議(もとの箱 を取り出す確率は単なる仮定と考えることもで きる。)
17.
スパム分類 ! P(spam¦words)
= P(words¦spam) * P(spam) / P(words) ! スパムと非スパムから単語の頻度が分かれば、 ある単語が文中に現れた場合にそれがスパムで ある確率を出すことができる
18.
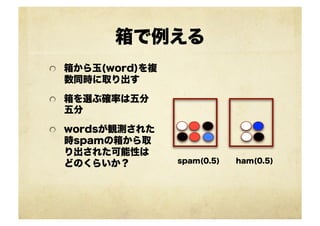
箱で例える ! 箱から玉(word)を複 数同時に取り出す !
箱を選ぶ確率は五分 五分 ! wordsが観測された 時spamの箱から取 り出された可能性は どのくらいか? spam(0.5) ham(0.5)
19.
数式の補足 ! 単純ベイズ分類器 !
条件付き独立を仮定 条件付き独立を仮定しているので Zは定数
20.
作業のながれ(やる?) ! tm(text
mining) パッケージを利用して TDM(term document matrix) をつくる ! 分類器をつくる ! 未知の単語が出てきた 場合どうするか ! テストする
21.
IRISで分類する
22.
e1071を使う data(iris) library(e1071) classifier<-‐‑‒naiveBayes(iris[,1:4],
iris[,5]) train <-‐‑‒ predict(classifier, iris[,-‐‑‒5]) table(train,iris[,5],dnn=list('predicted','actual')) actual predicted setosa versicolor virginica setosa 50 0 0 versicolor 0 47 3 virginica 0 3 47
23.
何をやったのか? library(ggplot2) g <-‐‑‒
ggplot(iris, aes(x=Petal.Length, color=Species)) pl <-‐‑‒ classifier$tables$Petal.Length g + geom_̲histogram() + stat_̲function(fun=dnorm, colour='red', args=list(mean=pl[1,1], sd=pl[1,2])) + stat_̲function(fun=dnorm, colour='green', args=list(mean=pl[2,1], sd=pl[2,2])) + stat_̲function(fun=dnorm, colour='blue', args=list(mean=pl[3,1], sd=pl[3,2]))
24.
3章まとめ ! ベイズ分類をつかってみました !
文書に対して行いたいのならpythonのNLTK が便利です。 ! Pythonでは他にscikit-learnという機械学習 パッケージもあります
Download








![散布図を描く
h
<-‐‑‒
ggplot(heights.weights,
aes(x=Height,
y=Weight))
h1
<-‐‑‒
h
+
geom_̲point()
h2
<-‐‑‒
h1
+
geom_̲smooth()
h3
<-‐‑‒
ggplot(heights.weights[1:20,],
aes(x=Height,
y=Weight))
+
geom_̲point()
+
geom_̲smooth()
h4
<-‐‑‒
ggplot(heights.weights[1:200,],
aes(x=Height,
y=Weight))
+
geom_̲point()
+
geom_̲smooth()
h5
<-‐‑‒
ggplot(heights.weights[1:2000,],
aes(x=Height,
y=Weight))
+
geom_̲point()
+
geom_̲smooth()
grid.arrange(h1,
h2,
h3,
h4,
h5,
ncol=2,
nrow=3)
! 散布図](https://image.slidesharecdn.com/ml130525-130524231918-phpapp02/85/slide-8-320.jpg)
![5章でやるので飛ばす
c
<-‐‑‒
coef(logit.mode)
ggplot(height.weights,
aes(x
=
Weight,
y=Height,
color=Gender))
+
geom_̲point()
+
stat_̲abline(intercept
=
-‐‑‒c[1]/c[2],
slope=-‐‑‒c[3]/c[2],
geom='abline',
color='black')](https://image.slidesharecdn.com/ml130525-130524231918-phpapp02/85/slide-10-320.jpg)






![e1071を使う
data(iris)
library(e1071)
classifier<-‐‑‒naiveBayes(iris[,1:4],
iris[,5])
train
<-‐‑‒
predict(classifier,
iris[,-‐‑‒5])
table(train,iris[,5],dnn=list('predicted','actual'))
actual
predicted
setosa
versicolor
virginica
setosa
50
0
0
versicolor
0
47
3
virginica
0
3
47](https://image.slidesharecdn.com/ml130525-130524231918-phpapp02/85/slide-22-320.jpg)
![何をやったのか?
library(ggplot2)
g
<-‐‑‒
ggplot(iris,
aes(x=Petal.Length,
color=Species))
pl
<-‐‑‒
classifier$tables$Petal.Length
g
+
geom_̲histogram()
+
stat_̲function(fun=dnorm,
colour='red',
args=list(mean=pl[1,1],
sd=pl[1,2]))
+
stat_̲function(fun=dnorm,
colour='green',
args=list(mean=pl[2,1],
sd=pl[2,2]))
+
stat_̲function(fun=dnorm,
colour='blue',
args=list(mean=pl[3,1],
sd=pl[3,2]))](https://image.slidesharecdn.com/ml130525-130524231918-phpapp02/85/slide-23-320.jpg)
















































