Download as PDF, PPTX

























![{
"id": "507f1f77bcf86cd7994390",
"projectId": "507f1f77bcf86cd7994390",
"content": "broadcast",
"name": "Жопоног - Газмяз",
"date" : {
"start": "2005-08-09T18:31:42-03:30",
"end": "2005-08-09T18:31:42-03:30"
},
"source": "http://.../playlist.m3u8",
"extra": {
"videoType": "хоккей",
"description": "Чемпионат мира по
гребной травле тараканов ;)"
},
"listeningStatus": "fail",
"status": "enabled"
}
{
"$schema": "…",
"type": "object",
"properties": {
"id": { "type": "string" },
"content": { "type": "string" },
"date": {
"type": "object",
"properties": {
"start": { "type": "string" },
"end": { "type": "string" }
},
"required": ["start","end"]
},
"source": { "type": "string" },
"status": { "type": "string" },
…
},
"required": ["id", "content",
"date", "status"]
}](https://image.slidesharecdn.com/8-161114140545/85/slide-29-320.jpg)
![{
"id": "507f1f77bcf86cd7994390",
"content": "broadcast",
"date" : {
"start": "2005-08-09T18:31:42-03:30",
"end": "2005-08-09T18:31:42-03:30"
},
"status": "enabled"
}
{
"$schema": "…",
"type": "object",
"properties": {
"id": { "type": "string" },
"content": { "type": "string" },
"date": {
"type": "object",
"properties": {
"start": { "type": "string" },
"end": { "type": "string" }
},
"required": ["start","end"]
},
"source": { "type": "string" },
"status": { "type": "string" },
…
},
"required": ["id", "content",
"date", "status"]
}](https://image.slidesharecdn.com/8-161114140545/85/slide-30-320.jpg)










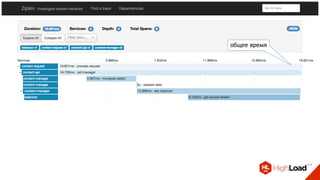
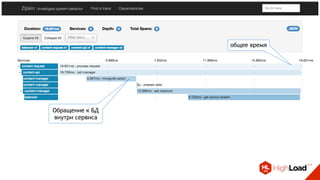
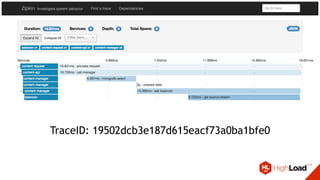



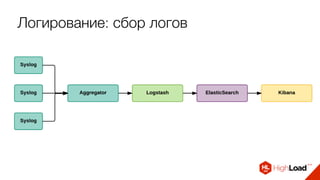








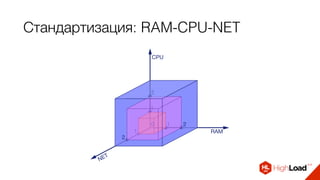
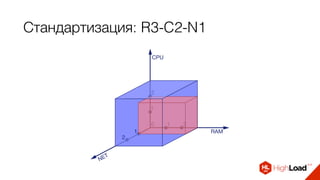
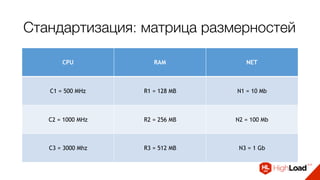
![Стандартизация
•N1C3R1 → [10 Mb] [3000 MHz] [128 MB]
•N1C2R3 → [10 Mb] [1500 MHz] [1 GB]](https://image.slidesharecdn.com/8-161114140545/85/slide-65-320.jpg)
![Стандартизация
•N1C3R1 → [10 Mb] [3000 MHz] [128 MB]
•N1C2R3 → [10 Mb] [1000 MHz] [1 GB]](https://image.slidesharecdn.com/8-161114140545/85/slide-66-320.jpg)



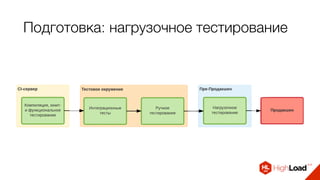
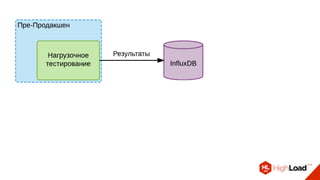
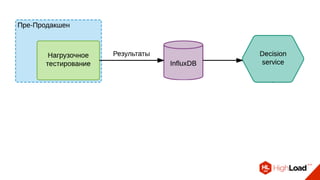
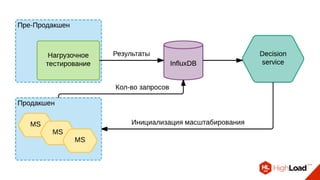









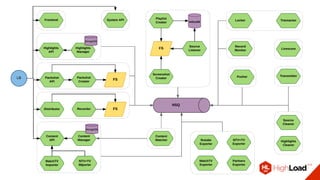
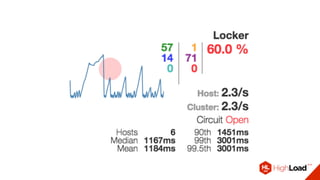
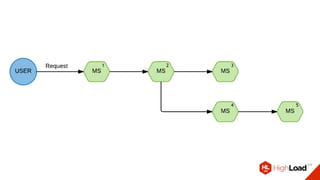
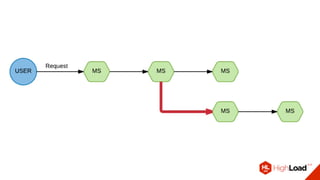
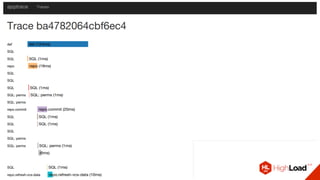
Документ описывает опыт использования микросервисной архитектуры в высоконагруженном проекте, занимающемся интернет-видеоплатформой с более чем 300,000 одновременными пользователями. Он охватывает этапы развития системы, проблемы и решения, связанные с масштабированием и взаимодействием между сервисами. Основные рекомендации включают использование оркестраторов, сбор метрик и применение паттернов защиты, таких как circuit breaker.























































































