Download as PDF, PPTX






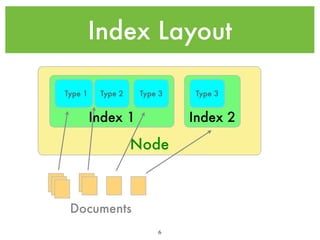
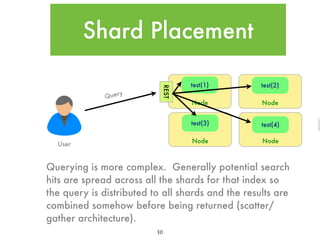


![Analyzer Example
“<p>The quick brown Fox jumps
over the Lazy dog</p>”
Input
“The quick brown Fox jumps
over the Lazy dog”
CharFilter
HTMLStripper
[“The”, “quick”, “brown”, “Fox”,
“jumps”, “over”, “the”, “Lazy”, “dog”]
Tokenizer
Standard
TokenFilter
Stopwords
[ “quick”, “brown”, “Fox”, “jumps”,
“over”, “Lazy”, “dog”]
TokenFilter
Lowercase
[ “quick”, “brown”, “fox”, “jumps”,
“over”, “lazy”, “dog”]
14
Index Terms](https://image.slidesharecdn.com/introtoelasticsearch-131223020953-phpapp01/85/Intro-to-Elasticsearch-14-320.jpg)
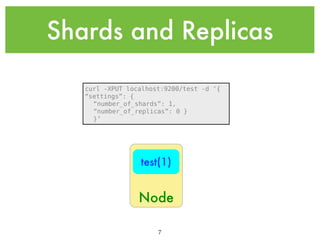
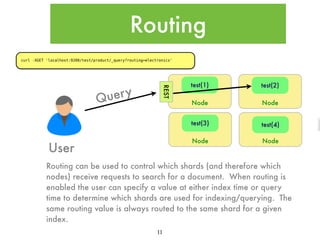
![Testing Analyzers
curl -XGET 'localhost:9200/_analyze?analyzer=standard&pretty&format=text' -d 'this Is a tESt'
{
"tokens" : [ {
"token" : "test",
"start_offset" : 12,
"end_offset" : 16,
"type" : "<ALPHANUM>",
"position" : 4
} ]
}
•ES has several built-in analyzers and analyzer
components (which are highly configurable)
•You can mix-and-match analyzer components to
build custom analyzers and use the Analysis
REST API to test your analyzers.
•Here is an example of the standard analyzer
(default if you don’t explicitly define a mapping)
being applied to a sample text string. Notice
that several common english words (the,is,this,a)
were removed and the case was normalized to
lowercase
15](https://image.slidesharecdn.com/introtoelasticsearch-131223020953-phpapp01/85/Intro-to-Elasticsearch-15-320.jpg)
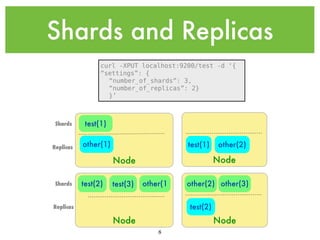
![Testing Analyzers
curl -XGET 'localhost:9200/_analyze?tokenizer=standard&pretty' -d 'this Is A tESt'
{
"tokens" : [ {
"token" : "this",
"start_offset" : 0,
"end_offset" : 4,
"type" : "<ALPHANUM>",
"position" : 1
}, {
"token" : "Is",
"start_offset" : 5,
"end_offset" : 7,
"type" : "<ALPHANUM>",
"position" : 2
}, {
"token" : "A",
"start_offset" : 8,
"end_offset" : 9,
"type" : "<ALPHANUM>",
"position" : 3
}, {
"token" : "tESt",
"start_offset" : 10,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 4
} ]
•We can also test tokenizers
and tokenFilters by
themselves.
•You can mix-and-match
analyzer components to build
custom analyzers and use the
Analysis REST API to test your
analyzers.
}
16](https://image.slidesharecdn.com/introtoelasticsearch-131223020953-phpapp01/85/Intro-to-Elasticsearch-16-320.jpg)





![Index Aliases
curl -XPOST 'http://localhost:9200/_aliases' -d '
{
"actions" : [
{ "add" : { "index" : "logs-2013-10", "alias"
{ "add" : { "index" : "logs-2013-09", "alias"
{ "add" : { "index" : "logs-2013-08", "alias"
{ "add" : { "index" : "logs-2013-07", "alias"
{ "add" : { "index" : "logs-2013-06", "alias"
{ "add" : { "index" : "logs-2013-05", "alias"
]
}'
:
:
:
:
:
:
"logs_last_6months"
"logs_last_6months"
"logs_last_6months"
"logs_last_6months"
"logs_last_6months"
"logs_last_6months"
}
}
}
}
}
}
},
},
},
},
},
},
•Index aliases allow us to manage one or more individual
indexes under a single logical name.
•This is perfect for things like creating an index alias to hold a
sliding window of indexes or providing a filtered “view” on a
subset of an indexes actual data.
•Like other aspects of ES, a REST API is exposed that allows
complete programmatic management of aliases
22](https://image.slidesharecdn.com/introtoelasticsearch-131223020953-phpapp01/85/Intro-to-Elasticsearch-22-320.jpg)

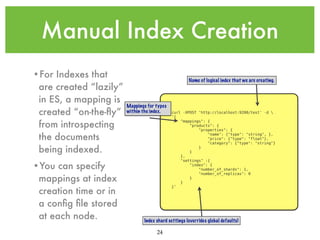

![Dynamic Field Mappings
{
"mappings" : {
"logs" : {
"dynamic_templates" : [
{
"logs": {
"match" : "*",
"mapping" : {
"type" : "multi_field",
"fields" : {
"{name}": {
"type" : "{dynamic_type}",
“index_analyzer”: “keyword”
},
"str": {"type" : "string"}
}
}
}
}
]
}
}
}
•Sometimes we want to control how
certain fields get mapped dynamically
indexes but we don’t know every
possible field ahead of time, dynamic
mapping templates help with this.
•A dynamic mapping template allows us
to use pattern matching to control how
new fields get mapped dynamically
•Within the template spec {dynamic_type}
is a placeholder for the type that ES
automatically infers for a given field and
{name} is the original name of the field
in the source document
26](https://image.slidesharecdn.com/introtoelasticsearch-131223020953-phpapp01/85/Intro-to-Elasticsearch-26-320.jpg)


















Elasticsearch is an open-source, distributed, real-time document indexer with support for online analytics. It has features like a powerful REST API, schema-less data model, full distribution and high availability, and advanced search capabilities. Documents are indexed into indexes which contain mappings and types. Queries retrieve matching documents from indexes. Analysis converts text into searchable terms using tokenizers, filters, and analyzers. Documents are distributed across shards and replicas for scalability and fault tolerance. The REST APIs can be used to index, search, and inspect the cluster.

















![[Azure Governance] Lesson 4 : Azure Policy](https://cdn.slidesharecdn.com/ss_thumbnails/azuregovernance-lesson4-azurepolicy-190519183014-thumbnail.jpg?width=640&height=640&fit=bounds)




























































