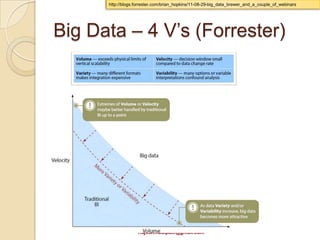
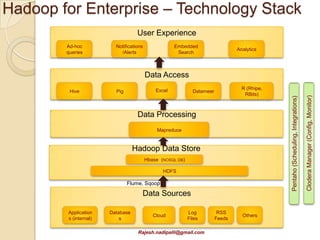
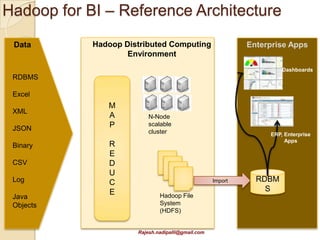
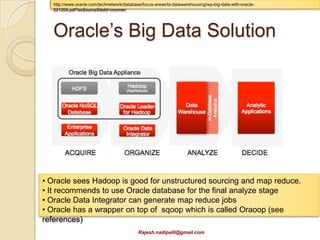
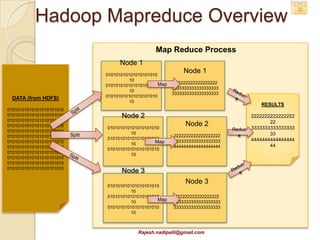
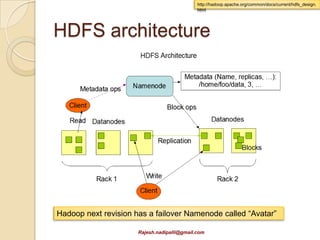
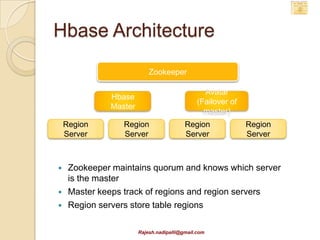
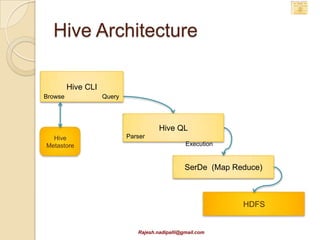
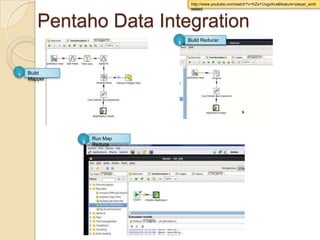
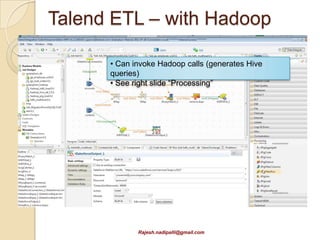
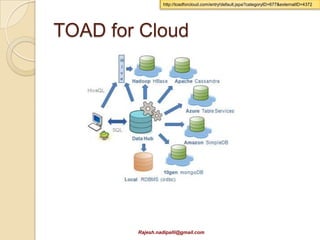
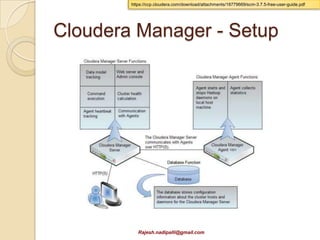
This document discusses Hadoop and how it is gaining adoption in the enterprise. It provides an overview of the Hadoop ecosystem including the core components of HDFS, MapReduce, Hive, Pig and HBase. It describes how enterprises are using Hadoop to store and analyze large amounts of structured and unstructured data across clustered servers. The document also discusses data integration tools like Pentaho and Talend that can help schedule and develop ETL processes for Hadoop. Finally, it provides some references and examples of companies that are using Hadoop for applications like log analysis, machine learning and data mining.






























































































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)






