


![Sorted Map Datastores
• Each row has a row key (like a Primary Key in RDBMS
terms)
• Users may query by exact row key or by range of row keys
• Data is always stored and returned in sorted order
• Each row has some number of columns
• Each column has a qualifier and some piece of data. Like a
Map<byte[], byte[]>
• Different rows may have different sets of columns
• Each cell has an associated timestamp and may retain a
history of previous values
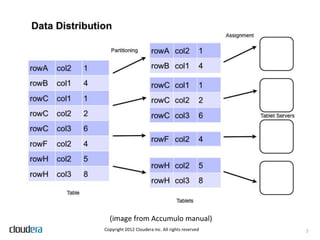
• Columns are grouped into column families and locality
groups
Copyright 2012 Cloudera Inc. All rights reserved 3](https://image.slidesharecdn.com/hbaseandaccumulotoddlipcomjan252012-120130213932-phpapp01/85/HBase-and-Accumulo-Washington-DC-Hadoop-User-Group-3-320.jpg)
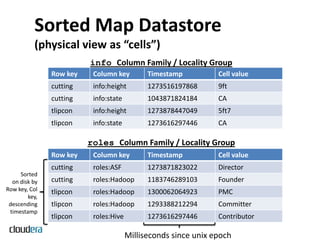
![Sorted Map Datastore
(logical view as “records”)
Implicit PRIMARY KEY in
RDBMS terms Data is all byte[] in HBase
Row key Data
Different types of
data separated into
cutting info: , ‘height’: ‘9ft’, ‘state’: ‘CA’ -
different roles: , ‘ASF’: ‘Director’, ‘Hadoop’: ‘Founder’ -
“column families” tlipcon info: , ‘height’: ‘5ft7, ‘state’: ‘CA’ -
roles: , ‘Hadoop’: ‘Committer’@ts=2010,
‘Hadoop’: ‘PMC’@ts=2011,
‘Hive’: ‘Contributor’ -
Different rows may have different sets A single cell might have different
of columns(table is sparse) values at different timestamps
Useful for *-To-Many mappings](https://image.slidesharecdn.com/hbaseandaccumulotoddlipcomjan252012-120130213932-phpapp01/85/HBase-and-Accumulo-Washington-DC-Hadoop-User-Group-4-320.jpg)



















The document presents a comparison of HBase and Accumulo, both open-source implementations of Google's Bigtable infrastructure, highlighting their scalable storage capabilities, data model, and features. Key differences discussed include access control mechanisms, authentication, locality groups management, and extensibility frameworks, with both systems showing strengths in different areas. The conclusion emphasizes that neither system is superior overall, suggesting that the choice depends on specific use cases and community interaction.






















































































