More Related Content

PDF

PDF
AtCoder Beginner Contest 022 解説 
PDF

PDF

PDF
AtCoder Regular Contest 033 解説 
PDF
AtCoder Beginner Contest 011 解説 
PDF
プログラミングコンテストでのデータ構造 2 ~平衡二分探索木編~ 
PDF
AtCoder Beginner Contest 017 解説 What's hot

PDF

PDF

PDF
AtCoder Beginner Contest 007 解説 
PDF

PDF
実践・最強最速のアルゴリズム勉強会 第四回講義資料(ワークスアプリケーションズ & AtCoder) 
PPTX

PDF

PDF
区間分割の仕方を最適化する動的計画法 (JOI 2021 夏季セミナー) 
PDF

PDF
AtCoder Beginner Contest 026 解説 
PDF

PDF
その文字列検索、std::string::findだけで大丈夫ですか?【Sapporo.cpp 第8回勉強会(2014.12.27)】 
PPTX

PDF

PPTX

PDF

PDF

PDF

PDF

PDF
AtCoder Beginner Contest 018 解説 Similar to Wavelet matrix implementation

PDF

PDF

PDF
PFI Christmas seminar 2009 
PDF

PDF
An Experimental Study of Bitmap Compression vs. Inverted List Compression 
PDF

PDF

PDF
CMSI計算科学技術特論A (2015) 第11回 行列計算における高速アルゴリズム2 
PDF

PDF
El text.tokuron a(2019).yamamoto190627 
PDF

PDF

PDF

PDF
第11回 配信講義 計算科学技術特論B(2022) 
PDF

PDF

PPTX

PDF

PDF

PDF
More from MITSUNARI Shigeo

PDF

PDF

PDF

PDF

PDF

PDF

PDF

PDF
Intel AVX-512/富岳SVE用SIMDコード生成ライブラリsimdgen 
PDF

PDF

PDF

PDF

PDF

PDF
深層学習フレームワークにおけるIntel CPU/富岳向け最適化法 
PDF

PDF

PDF
Lifted-ElGamal暗号を用いた任意関数演算の二者間秘密計算プロトコルのmaliciousモデルにおける効率化 
PDF

PDF

PDF
Wavelet matrix implementation
- 1.
- 2.
今回の実装(中のもの)
Succinct vector
https://github.com/herumi/cybozulib/blob/m
aster/include/cybozu/sucvector.hpp
Wavelet matrix
https://github.com/herumi/cybozulib/blob/m
aster/include/cybozu/wavelet_matrix.hpp
Benchmark code
https://github.com/herumi/opti/
rank_test.cpp, wm_test.cpp
2 / 16
- 3.
- 4.
- 5.
step 1
データをインタリーブする
オリジナルのv, L,Sがばらばらにあると
それぞれのアクセス時にキャッシュミス発生
rank(i)の計算に必要なi番目のv, L, Sをセット
256bitのv, 32bitのL, 8bit x 4のS
Block {
uint64_t org[4];
uint32_t L;
uint8_t S[4];
};
5 / 16
- 6.
step 2
N <2^32の制限を外したい
uint32_t L → uint64_t Lへ変更
Blockがuint64_tの倍数でなくなりpadding発生
もったいないのでuint8_t S[8];にする
つまり256個ずつではなく512個ずつに
するとSの累積和が256を超えるのでuint8_tに入
らない → 累積和をあきらめる
必要量はbitあたり(64 + 8 * 8) / 512 = 1 / 4
Block {
uint64_t org[8];
uint64_t L;
uint8_t S[8];
}; 6 / 16
- 7.
step 3
uint8_t S[8];の部分和を高速に求める
SIMD命令のpsadbwを使ったテクニック
http://homepage1.nifty.com/herumi/diary/1206.h
tml#25
2012年度夏のプログラム・シンポジウム
http://spro2012.prosym.jp/
http://www.slideshare.net/herumi/prosym2012/
7 / 16
- 8.
step 4
step 0のuint8_tS[4];を見直す
S[i] = [0, i * 64)のビットの和
S[0]は常に0
この領域を使ってみる
2^32 * 256 = 2^40までOK
オリジナルのビットベクトルだけで128GiB
現時点では殆ど制限にならないだろう
必要量はbitあたり1/4で今までと変わらない
ブロックの単位が512bitから256bit
キャッシュミスがへる
累積和テーブルOK
psadbwのせこい最適化不要(ちょっと残念…)
8 / 16
- 9.
rankのベンチマーク
Xeon 5650 +96GiB + gcc 4.6.3
N=2^31のランダムなビットベクトルのrank
時間(clk)
SucVec : 私の実装(cybozu/sucvector.hpp)
marisa : marisa-0.2.2(括弧内は0.2.0)
sux : sux-0.7
sdsl : sdsl (2012/9/5時点のsnapshot)
shell : shellinford-r27
wat : wat_array-0.0.6
SucVec marisa sux sdsl shell wat
84.22 152.95(162.77) 143.23 103.73 385.82 312.51
9 / 16
- 10.
selectの実装
テーブルLを使って大雑把な2分探索
レンジが256bitになったら64bit単位で探索
64bit(8bitx 8)をpopcntを使って8bitまで狭める
最後の8bitはテーブル引き
2分探索の初期値(0, L.size())を狭める
selTbl[i] = select(1024 * i)をテーブルに持つ
posUnit = 1024は適当
必要なメモリはbitあたり1 / 1024 * 32 = 1 / 32
ベンチマーク(rankと同じ条件)
SucVec marisa sux sdsl shell wat
608.45 622.96(659.30) 891.47 -- 1816.38 2205.60
10 / 16
- 11.
- 12.
how to createtable for rank
rankの高速化のためのテーブル生成は再帰を
使えば比較的簡潔にかける
rankLtにも同様のテクニックが使える
void initFromTbl(std::vector<size_t>& tbl,
size_t pos, size_t from, size_t i) {
if (i == valBitLen_) {
tbl[pos] = from;
} else {
initFromTbl(tbl,pos,
svv[i].rank(false, from), i + 1);
initFromTbl(tbl,pos+(size_t(1)<<(valBitLen_-1-i)),
svv[i].rank(true, from) + offTbl[i], i + 1);
}
}
12 / 16
- 13.
- 14.
how to createtable for select
各文字vに対してselTbl[i] = select(256 * i);を
求めるとNが大きいときすさまじく遅かった
入力ベクトルをC回なめることになる
使い物にならない
入力ベクトルを一度なめるだけで各Nに対して
まとめてselTbl[i]を作るように修正
14 / 16
- 15.
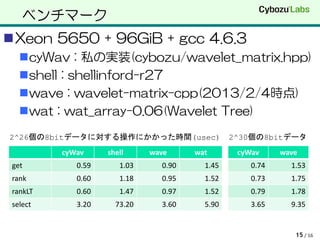
ベンチマーク
Xeon 5650 +96GiB + gcc 4.6.3
cyWav : 私の実装(cybozu/wavelet_matrix.hpp)
shell : shellinford-r27
wave : wavelet-matrix-cpp(2013/2/4時点)
wat : wat_array-0.06(Wavelet Tree)
2^26個の8bitデータに対する操作にかかった時間(usec) 2^30個の8bitデータ
cyWav shell wave wat cyWav wave
get 0.59 1.03 0.90 1.45 0.74 1.53
rank 0.60 1.18 0.95 1.52 0.73 1.75
rankLT 0.60 1.47 0.97 1.52 0.79 1.78
select 3.20 73.20 3.60 5.90 3.65 9.35
15 / 16
- 16.
参考文献
echizen_tmさん
ウェーブレット行列最速攻略〜予告編〜
http://ja.scribd.com/doc/102636443/Wavelet-
Matrix
hiroshi-manabeさん
https://github.com/hiroshi-manabe/wavelet-
matrix-cpp/
岡野原さん
http://code.google.com/p/wat-array/
その他いろいろ
16 / 16






![step 1
データをインタリーブする
オリジナルのv, L, Sがばらばらにあると
それぞれのアクセス時にキャッシュミス発生
rank(i)の計算に必要なi番目のv, L, Sをセット
256bitのv, 32bitのL, 8bit x 4のS
Block {
uint64_t org[4];
uint32_t L;
uint8_t S[4];
};
5 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-5-320.jpg)
![step 2
N < 2^32の制限を外したい
uint32_t L → uint64_t Lへ変更
Blockがuint64_tの倍数でなくなりpadding発生
もったいないのでuint8_t S[8];にする
つまり256個ずつではなく512個ずつに
するとSの累積和が256を超えるのでuint8_tに入
らない → 累積和をあきらめる
必要量はbitあたり(64 + 8 * 8) / 512 = 1 / 4
Block {
uint64_t org[8];
uint64_t L;
uint8_t S[8];
}; 6 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-6-320.jpg)
![step 3
uint8_t S[8];の部分和を高速に求める
SIMD命令のpsadbwを使ったテクニック
http://homepage1.nifty.com/herumi/diary/1206.h
tml#25
2012年度夏のプログラム・シンポジウム
http://spro2012.prosym.jp/
http://www.slideshare.net/herumi/prosym2012/
7 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-7-320.jpg)
![step 4
step 0のuint8_t S[4];を見直す
S[i] = [0, i * 64)のビットの和
S[0]は常に0
この領域を使ってみる
2^32 * 256 = 2^40までOK
オリジナルのビットベクトルだけで128GiB
現時点では殆ど制限にならないだろう
必要量はbitあたり1/4で今までと変わらない
ブロックの単位が512bitから256bit
キャッシュミスがへる
累積和テーブルOK
psadbwのせこい最適化不要(ちょっと残念…)
8 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-8-320.jpg)

![selectの実装
テーブルLを使って大雑把な2分探索
レンジが256bitになったら64bit単位で探索
64bit(8bit x 8)をpopcntを使って8bitまで狭める
最後の8bitはテーブル引き
2分探索の初期値(0, L.size())を狭める
selTbl[i] = select(1024 * i)をテーブルに持つ
posUnit = 1024は適当
必要なメモリはbitあたり1 / 1024 * 32 = 1 / 32
ベンチマーク(rankと同じ条件)
SucVec marisa sux sdsl shell wat
608.45 622.96(659.30) 891.47 -- 1816.38 2205.60
10 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-10-320.jpg)
![how to create table for rank
rankの高速化のためのテーブル生成は再帰を
使えば比較的簡潔にかける
rankLtにも同様のテクニックが使える
void initFromTbl(std::vector<size_t>& tbl,
size_t pos, size_t from, size_t i) {
if (i == valBitLen_) {
tbl[pos] = from;
} else {
initFromTbl(tbl,pos,
svv[i].rank(false, from), i + 1);
initFromTbl(tbl,pos+(size_t(1)<<(valBitLen_-1-i)),
svv[i].rank(true, from) + offTbl[i], i + 1);
}
}
12 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-12-320.jpg)

![how to create table for select
各文字vに対してselTbl[i] = select(256 * i);を
求めるとNが大きいときすさまじく遅かった
入力ベクトルをC回なめることになる
使い物にならない
入力ベクトルを一度なめるだけで各Nに対して
まとめてselTbl[i]を作るように修正
14 / 16](https://image.slidesharecdn.com/wavelet-matrix-impl-130220180415-phpapp01/85/Wavelet-matrix-implementation-14-320.jpg)