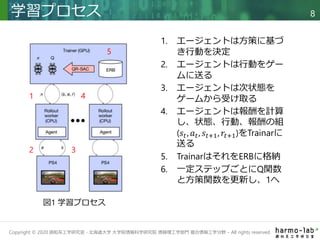
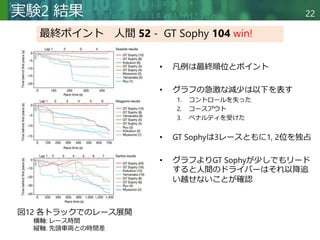
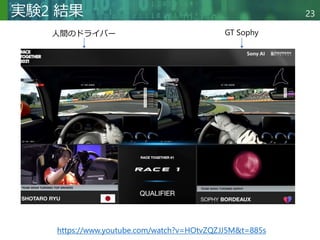
PlayStation4(PS4)用ゲームソフトGran Turismo (GT) Sportを用いて深層強化学習エージェントと人間のプロが対決.このゲームは実際のレースカーの非線形制御の課題を忠実に再現している.強化学習エージェントの学習にあたって、最先端のモデルフリーの深層強化学習アルゴリズムOR-SACの開発,スポーツマンシップを守りつつ競争力のある報酬関数の構築,更に学習シナリオにも工夫を加えたことで卓越したスピードと優れた戦術を組み合わせた統合制御方策を学習した.本論文のエージェント,Gran Turismo Sophy(GT Sophy)は世界最高のGTのドライバー4人と直接対決の末、勝利を飾った.





![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
5
関連研究
• 近年は実際のサイズ、スケール、シミュレーションを活用した自律走
行レースの研究が盛ん
• 一般的には、事前に軌道を計算[1,2]し、モデル予測制御を用いて軌道
を実行[3,4]
– わずかなモデリングエラーが致命的になることも
– ドライバーの数が増えるとモデリング精度に対する要求は更に増加
• モデリング上の複雑さを回避するために機械学習を用いた様々な方法
を模索
– 教師あり学習を使った車両ダイナミクスのモデル化[5,6,7]、模倣学習[8]、進化的アプ
ローチ[9]、強化学習[10]
• いくつかの研究では、単独走行で人間を凌駕したり、単純な追い越し
シナリオに進展
• しかし、最高レベルのレースに取り組んだものはない
1. Theodosis, P. A. & Gerdes, J. C. In Dynamic Systems and Control ConferenceVol. 45295, 235–241 (American Society of Mechanical Engineers, 2012).
2. Funke, J. et al. In 2012 IEEE Intelligent Vehicles Symposium 541–547 (IEEE, 2012).
3. Laurense, V. A., Goh, J. Y. & Gerdes, J. C. In 2017 American Control Conference (ACC) 5586–5591 (IEEE, 2017).
4. . Kritayakirana, K. & Gerdes, J. C. Autonomous vehicle control at the limits of handling. Int. J. Veh. Auton. Syst. 10, 271–296 (2012).
5. Spielberg, N. A., Brown, M., Kapania, N. R., Kegelman, J. C. & Gerdes, J. C. Neural network vehicle models for high-performance automated driving. Sci. Robot. 4, eaaw1975 (2019).
6. Williams, G., Drews, P., Goldfain, B., Rehg, J. M. & Theodorou, E. A. Information-theoretic model predictive control: theory and applications to autonomous driving. IEEE Trans. Robot. 34, 1603–1622 (2018).
7. Rutherford, S. J. & Cole, D. J. Modelling nonlinear vehicle dynamics with neural networks. Int. J. Veh. Des. 53, 260–287 (2010).
8. Pomerleau, D. A. In Robot Learning (eds Connell, J. H. & Mahadevan, S.) 19–43 (Springer, 1993).
9. Togelius, J. & Lucas, S. M. In 2006 IEEE International Conference on Evolutionary Computation 1187–1194 (IEEE, 2006).
10. Pyeatt, L. D. & Howe, A. E. Learning to race: experiments with a simulated race car. In Proc. Eleventh International FLAIRS Conference 357–361 (AAAI, 1998).](https://image.slidesharecdn.com/20220912dl-220912121032-db3b2431/85/Outracing-champion-Gran-Turismo-drivers-with-deep-reinforcement-learning-5-320.jpg)

![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
7
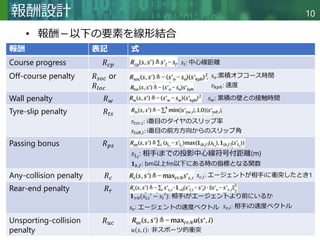
提案手法
• チャンピオンレベルのレーシングエージェント、
Gran Turismo Sophy(GT Sophy)を構築
– モデルフリー、オフポリシー深層強化学習アルゴリズムQR-SACを
開発
• SAC[11,12]をN-step報酬[13]を扱うように修正
• 将来の報酬の期待値をそれらの報酬の確率分布[14]で表現
– PlayStation4(PS4)用ゲームソフトGran Turismo (GT) Sport
(https://www.gran-turismo.com/us/ )において人間のトップドライ
バーと渡り合うために開発
11. Haarnoja, T., Zhou, A., Abbeel, P. & Levine, S. In Proc. 35th International Conference on Machine Learning 1856–1865 (PMLR, 2018).
12. Haarnoja, T. et al. Soft actor-critic algorithms and applications. Preprint at https://arxiv. org/abs/1812.05905 (2018).
13. Mnih, V. et al. In Proc. 33rd International Conference on Machine Learning 1928–1937 (PMLR, 2016).
14. Dabney, W., Rowland, M., Bellemare, M. G. & Munos, R. In 32nd AAAI Conference on Artificial Intelligence (AAAI, 2018)](https://image.slidesharecdn.com/20220912dl-220912121032-db3b2431/85/Outracing-champion-Gran-Turismo-drivers-with-deep-reinforcement-learning-7-320.jpg)
![Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
Copyright © 2020 調和系工学研究室 - 北海道大学 大学院情報科学研究院 情報理工学部門 複合情報工学分野 – All rights reserved.
9
観測値と行動
3次元速度
3次元角加速度
3次元加速度
各タイヤの荷重
タイヤのスリップ角
コース上のスカラー進行(sin成分とcos成分で表現)
コース表面の傾斜
コース中心線に対する車両の向き
先のコースを記述する(左、中央、右)コース点
車両接触フラグ
スリップストリームスカラー
相対重心位置
相対速度
相対加速度
• 前方車用と後方車
用の2つのリスト
• エージェントから
の距離が近い順に
リストに格納
タイムトライアル レース
タイムトライアルの観測値
+
• 行動
行動 値
加速度変更
(加速とブレーキ)
[-1,1]
ステアリング操作 [-1,1]
• 観測値
コースの各辺と中心線に沿って等間隔に
配置された60個の3次元点として符号化
点群の間隔は現在の速度の関数
常に次の6秒間の移動距離
図2 コースセグメント](https://image.slidesharecdn.com/20220912dl-220912121032-db3b2431/85/Outracing-champion-Gran-Turismo-drivers-with-deep-reinforcement-learning-9-320.jpg)









![[DL輪読会]画像を使ったSim2Realの現況](https://cdn.slidesharecdn.com/ss_thumbnails/imagesim2real-201030025320-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Pay Attention to MLPs (gMLP)](https://cdn.slidesharecdn.com/ss_thumbnails/kobayashi-210528032327-thumbnail.jpg?width=640&height=640&fit=bounds)
















































