Download as PDF, PPTX







![DataFrame
noun – [dey-tuh-freym]
9
1. A distributed collection of rows organized into
named columns.
2. An abstraction for selecting, filtering, aggregating
and plotting structured data (cf. R, Pandas).
3. Archaic: Previously SchemaRDD (cf. Spark< 1.3).](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-9-320.jpg)








![Write Less Code: Compute an Average
private IntWritable one =
new IntWritable(1)
private IntWritable output =
new IntWritable()
proctected void map(
LongWritable key,
Text value,
Context context) {
String[] fields = value.split("t")
output.set(Integer.parseInt(fields[1]))
context.write(one, output)
}
IntWritable one = new IntWritable(1)
DoubleWritable average = new DoubleWritable()
protected void reduce(
IntWritable key,
Iterable<IntWritable> values,
Context context) {
int sum = 0
int count = 0
for(IntWritable value : values) {
sum += value.get()
count++
}
average.set(sum / (double) count)
context.Write(key, average)
}
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [x.[1], 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
18](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-18-320.jpg)
![Write Less Code: Compute an Average
Using RDDs
data = sc.textFile(...).split("t")
data.map(lambda x: (x[0], [int(x[1]), 1]))
.reduceByKey(lambda x, y: [x[0] + y[0], x[1] + y[1]])
.map(lambda x: [x[0], x[1][0] / x[1][1]])
.collect()
Using DataFrames
sqlCtx.table("people")
.groupBy("name")
.agg("name", avg("age"))
.map(lambda …)
.collect()
Full API Docs
• Python
• Scala
• Java
• R
19
Using SQL
SELECT name, avg(age)
FROM people
GROUP BY name](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-19-320.jpg)



![Machine Learning Pipelines
26
tokenizer = Tokenizer(inputCol="text",
outputCol="words”)
hashingTF = HashingTF(inputCol="words",
outputCol="features”)
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
df = sqlCtx.load("/path/to/data")
model = pipeline.fit(df)
ds0 ds1 ds2 ds3tokenizer hashingTF lr.model
lr
Pipeline Model](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-26-320.jpg)


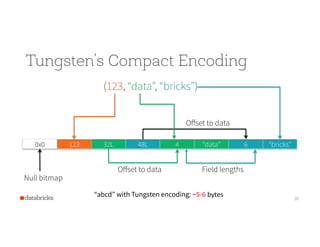
![The overheads of JVM objects
“abcd”
29
• Native: 4 byteswith UTF-8 encoding
• Java: 48 bytes
java.lang.String object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) ...
4 4 (object header) ...
8 4 (object header) ...
12 4 char[] String.value []
16 4 int String.hash 0
20 4 int String.hash32 0
Instance size: 24 bytes (reported by Instrumentation API)
12 byte object header
8 byte hashcode
20 bytes data + overhead](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-29-320.jpg)

![• Type-safe: operate on domain
objectswith compiled lambda
functions
• Fast: Code-generated
encodersfor fast serialization
• Interoperable: Easily convert
DataFrame ßà Dataset
withoutboilerplate
32
Coming soon: Datasets
val df = ctx.read.json("people.json")
// Convert data to domain objects.
case class Person(name: String, age: Int)
val ds: Dataset[Person] = df.as[Person]
ds.filter(_.age > 30)
// Compute histogram of age by name.
val hist = ds.groupBy(_.name).mapGroups {
case (name, people: Iter[Person]) =>
val buckets = new Array[Int](10)
people.map(_.age).foreach { a =>
buckets(a / 10) += 1
}
(name, buckets)
}
Preview
in
Spark
1.6](https://image.slidesharecdn.com/sparksql-151028143749-lva1-app6892/85/Spark-Summit-EU-2015-Spark-DataFrames-Simple-and-Fast-Analysis-of-Structured-Data-32-320.jpg)


The document discusses Spark SQL and DataFrames, highlighting their capabilities for efficient analytics on structured data. It emphasizes the advantages of writing less code, reading less data, and leveraging the optimizer for performance improvements. Additionally, it covers features like data source integration, machine learning pipelines, and a rich function library introduced in various Spark versions.





























































































