Download as PDF, PPTX










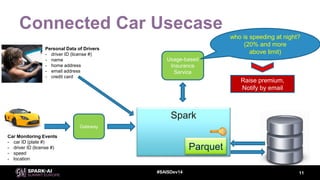



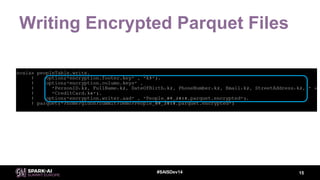
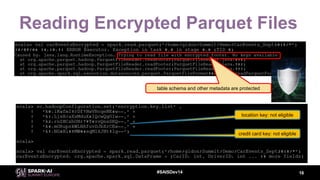

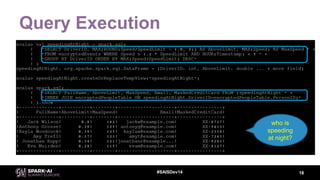







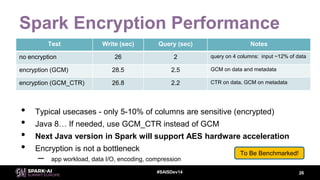





This document discusses efficient Spark analytics on encrypted data using Parquet modular encryption. It provides an overview of the problem of protecting sensitive data at rest while preserving analytics performance. It then describes Parquet modular encryption which enables columnar projection, predicate pushdown and fine-grained access control on encrypted Parquet data. Finally, it demonstrates a connected car use case and shows the performance implications of encryption on Spark analytics are minimal.























































































