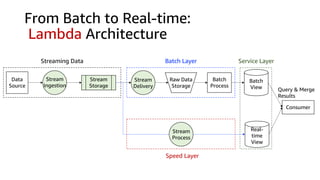
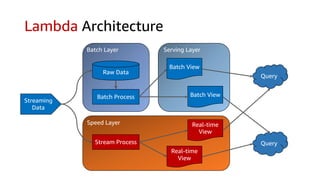
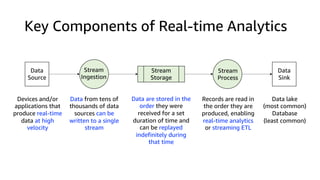
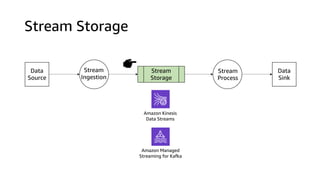
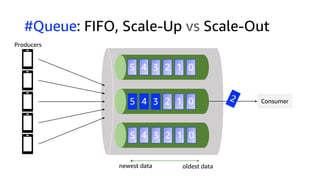
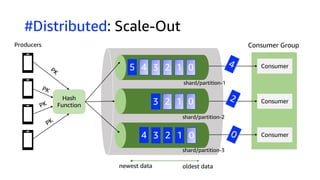
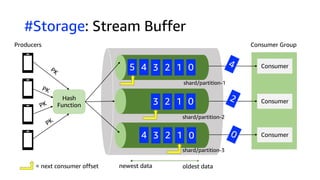
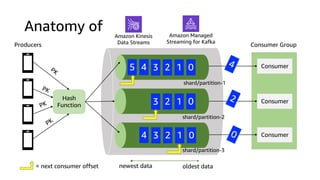
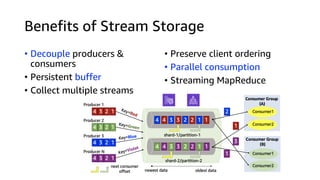
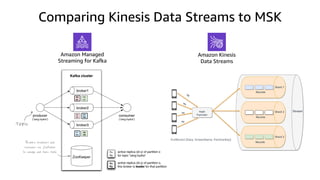
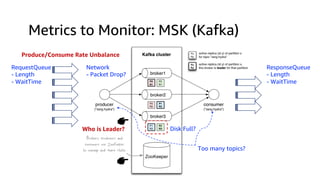
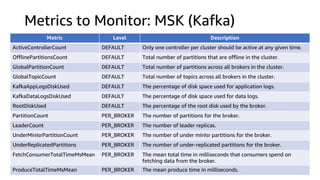
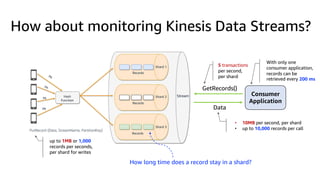
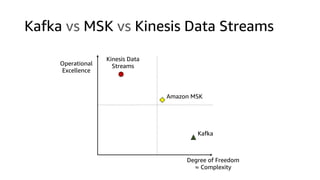
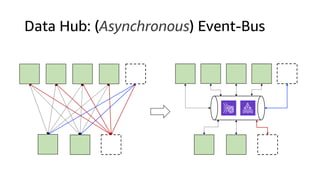
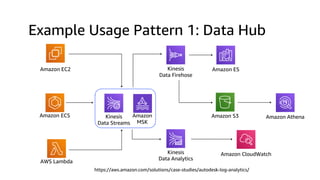
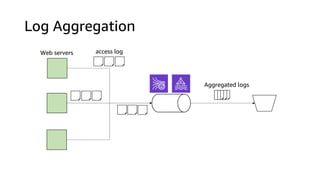
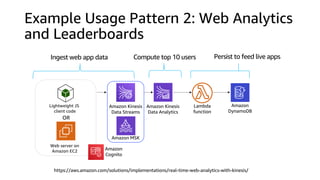
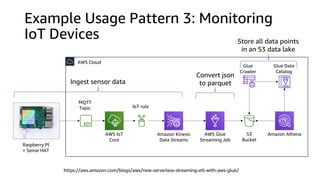
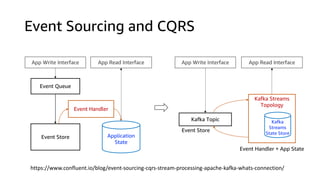
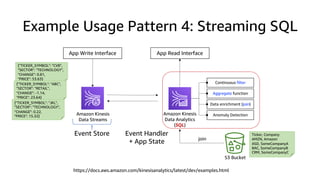
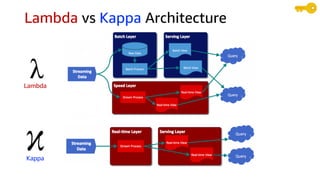
The document compares Amazon Kinesis Data Streams and Amazon Managed Streaming for Kafka (MSK) in the context of real-time analytics, highlighting their key features, monitoring metrics, and architectural patterns. It emphasizes the importance of stream storage, producer-consumer decoupling, and operational characteristics such as scalability and throughput. Additionally, it provides guidance on metrics to monitor for both services and outlines various use cases and best practices.






















































































![[DSC Europe 25] Milos Belcevic - Product Professional's Journey to Full-Stack...](https://cdn.slidesharecdn.com/ss_thumbnails/1zovd6fgsycdg4wvgvls-milos-belcevic-product-professionals-journey-to-full-stack-product-developer-260123083019-d993120d-thumbnail.jpg?width=640&height=640&fit=bounds)







