Downloaded 10 times

![State Storage Example
Batch 1
Batch 2
Batch 3
State
= 10
[1-4]
[5-8]
[9-10]
Count: 10
State
= 36
State
= 55
Count: 10 + 26 = 36
Count: 36 + 19 = 55
Running Count](https://image.slidesharecdn.com/sdylgji6rbakspxnbbge-signature-af5252a2f51615aa5a96d258312551192748380954a4c8ac8d323cd5a1815ba1-poli-190517185812/85/Rocks-db-state-store-in-structured-streaming-2-320.jpg)
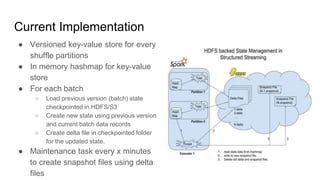



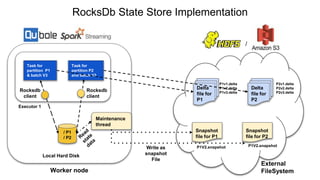


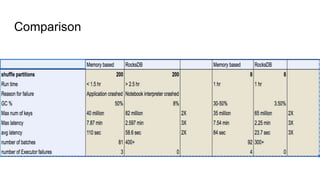
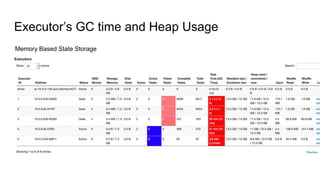


The document describes the implementation of a RocksDB state store in structured streaming to address scalability and latency issues found in the current hashmap-based approach. It outlines the transaction-based usage of RocksDB for state management across batches, ensuring consistency, isolation, and durability through a series of operational tasks, including snapshot creation and delta file management. Performance analysis and configurations are provided, showing setup details and the comparison of garbage collection times between the two storage methods.



































































