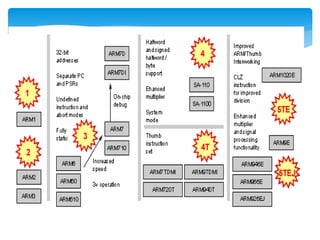
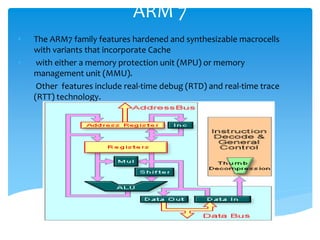
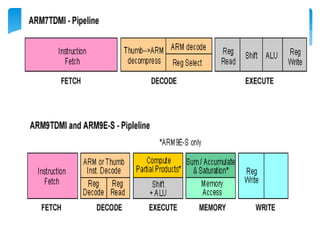
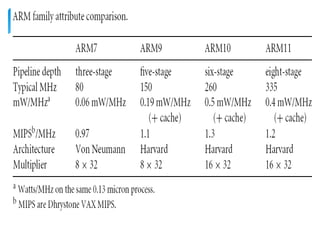
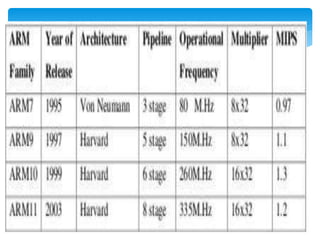
This document provides an overview of four ARM architecture families: ARM7, ARM9, ARM10, and ARM11. It describes the key features and performance improvements of each family over previous generations. The ARM9 introduced a 5-stage pipeline compared to ARM7's 3-stage pipeline, improving clock speed. ARM10 added a branch predictor and separate load/store unit. ARM11 supported SIMD instructions and reduced cache aliasing problems. Each new family optimized the pipeline design and added capabilities to enhance performance and efficiency.









































![Interfacing technique with 8085- ADC[0808]](https://cdn.slidesharecdn.com/ss_thumbnails/adc-160307140900-thumbnail.jpg?width=640&height=640&fit=bounds)



























































