Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
健青
Uploaded by
健児 青木
PDF, PPTX
1,164 views
読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節 潜在意味空間における分類問題
第6回『トピックモデルによる統計的潜在意味解析』読書会 http://topicmodel.connpass.com/event/19498/
Data & Analytics
◦
Read more
2
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 24
2
/ 24
3
/ 24
4
/ 24
5
/ 24
6
/ 24
Most read
7
/ 24
8
/ 24
Most read
9
/ 24
10
/ 24
11
/ 24
12
/ 24
13
/ 24
14
/ 24
15
/ 24
16
/ 24
17
/ 24
18
/ 24
19
/ 24
20
/ 24
21
/ 24
22
/ 24
23
/ 24
24
/ 24
More Related Content
PDF
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
PPTX
物体検出フレームワークMMDetectionで快適な開発
by
Tatsuya Suzuki
PDF
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
PPTX
【論文読み会】Moser Flow: Divergence-based Generative Modeling on Manifolds
by
ARISE analytics
PDF
2019年度チュートリアルBPE
by
広樹 本間
PDF
バイナリニューラルネットとハードウェアの関係
by
Kento Tajiri
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PDF
論文紹介-Multi-Objective Deep Reinforcement Learning
by
Shunta Nomura
【DL輪読会】RLCD: Reinforcement Learning from Contrast Distillation for Language M...
by
Deep Learning JP
物体検出フレームワークMMDetectionで快適な開発
by
Tatsuya Suzuki
[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.
by
Deep Learning JP
【論文読み会】Moser Flow: Divergence-based Generative Modeling on Manifolds
by
ARISE analytics
2019年度チュートリアルBPE
by
広樹 本間
バイナリニューラルネットとハードウェアの関係
by
Kento Tajiri
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
論文紹介-Multi-Objective Deep Reinforcement Learning
by
Shunta Nomura
What's hot
PPTX
論文紹介 No-Reward Meta Learning (RL architecture勉強会)
by
Yusuke Nakata
PDF
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
PPTX
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
PDF
SIGNATE 産業技術総合研究所 衛星画像分析コンテスト 2位入賞モデルの工夫点
by
Ken'ichi Matsui
PDF
[DL輪読会]Conditional Neural Processes
by
Deep Learning JP
PDF
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
PPTX
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
PDF
PRML Chapter5.2
by
Takuya Minagawa
PDF
OpenOpt の線形計画で圧縮センシング
by
Toshihiro Kamishima
PPTX
近年のHierarchical Vision Transformer
by
Yusuke Uchida
PDF
時系列データと確率的プログラミング tfp.sts
by
Yuta Kashino
PDF
ベイズ機械学習(an introduction to bayesian machine learning)
by
医療IT数学同好会 T/T
PDF
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
PDF
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
PPTX
最尤推定法(NNでの応用)
by
MatsuiRyo
PDF
GAN(と強化学習との関係)
by
Masahiro Suzuki
PDF
定理証明支援系Coqについて
by
Yoshihiro Mizoguchi
PPTX
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
論文紹介 No-Reward Meta Learning (RL architecture勉強会)
by
Yusuke Nakata
深層生成モデルを用いたマルチモーダル学習
by
Masahiro Suzuki
【DL輪読会】Llama 2: Open Foundation and Fine-Tuned Chat Models
by
Deep Learning JP
SIGNATE 産業技術総合研究所 衛星画像分析コンテスト 2位入賞モデルの工夫点
by
Ken'ichi Matsui
[DL輪読会]Conditional Neural Processes
by
Deep Learning JP
深層学習による自然言語処理入門: word2vecからBERT, GPT-3まで
by
Yahoo!デベロッパーネットワーク
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
【DL輪読会】DINOv2: Learning Robust Visual Features without Supervision
by
Deep Learning JP
[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...
by
Deep Learning JP
PRML Chapter5.2
by
Takuya Minagawa
OpenOpt の線形計画で圧縮センシング
by
Toshihiro Kamishima
近年のHierarchical Vision Transformer
by
Yusuke Uchida
時系列データと確率的プログラミング tfp.sts
by
Yuta Kashino
ベイズ機械学習(an introduction to bayesian machine learning)
by
医療IT数学同好会 T/T
Optuna Dashboardの紹介と設計解説 - 2022/12/10 Optuna Meetup #2
by
Preferred Networks
モデルではなく、データセットを蒸留する
by
Takahiro Kubo
最尤推定法(NNでの応用)
by
MatsuiRyo
GAN(と強化学習との関係)
by
Masahiro Suzuki
定理証明支援系Coqについて
by
Yoshihiro Mizoguchi
[DL輪読会]Flow-based Deep Generative Models
by
Deep Learning JP
Viewers also liked
PDF
テクノアルファ株式会社 平成26年11月期 決算説明会資料
by
TechnoAlphaIR
PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第8回 3.6節 Dirichlet分布のパラメータ推定
by
健児 青木
PDF
「トピックモデルによる統計的潜在意味解析」読書会 4章前半
by
koba cky
PDF
Private Wealth Management and Global Financial Business (Lecture)
by
Josai University
PDF
黒い画面入門 + パッケージ管理紹介 + Macの使い方とか
by
Tomohiko Himura
PDF
Word bench 制作効率を上げるツール
by
Takashi Ishihara
PDF
20100930 DevLOVE Enagilized Work!
by
一法 山崎
PDF
第5回札幌SoftLayer勉強会資料_20150311
by
潤 川岡
PDF
20120915 TOCfE Boot Camp at XP祭り2012
by
一法 山崎
PDF
Ftma15 04 all
by
Yoichi Ochiai
PDF
xPlus で実現するモビリティの最大化
by
インフラジスティックス・ジャパン株式会社
KEY
SNS 「github」で遊ぼう
by
Tomohiko Himura
PDF
ソーシャルメディア大百科川井パート(ファンドレイジングセミナー2012より)
by
himanainu inc.
PPT
111127.lsj143.田川 japanese conjugation and dm
by
Takumi Tagawa
PDF
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
by
健児 青木
PDF
坂井直樹と考える、デザインの歴史とこれから 先生:坂井直樹
by
schoowebcampus
PDF
俺の仕事がこんなに楽しいわけが無い・公開版(初出:2010/12/20 株式会社ECナビ会社説明会@IAMAS)
by
bash0C7
PDF
GCS2013 itowponde 0622
by
英明 伊藤
PDF
日本社会薬学会 20140914
by
遠矢 純一郎
PDF
社内SNSと巻き込み力
by
八木橋 パチ
テクノアルファ株式会社 平成26年11月期 決算説明会資料
by
TechnoAlphaIR
読書会 「トピックモデルによる統計的潜在意味解析」 第8回 3.6節 Dirichlet分布のパラメータ推定
by
健児 青木
「トピックモデルによる統計的潜在意味解析」読書会 4章前半
by
koba cky
Private Wealth Management and Global Financial Business (Lecture)
by
Josai University
黒い画面入門 + パッケージ管理紹介 + Macの使い方とか
by
Tomohiko Himura
Word bench 制作効率を上げるツール
by
Takashi Ishihara
20100930 DevLOVE Enagilized Work!
by
一法 山崎
第5回札幌SoftLayer勉強会資料_20150311
by
潤 川岡
20120915 TOCfE Boot Camp at XP祭り2012
by
一法 山崎
Ftma15 04 all
by
Yoichi Ochiai
xPlus で実現するモビリティの最大化
by
インフラジスティックス・ジャパン株式会社
SNS 「github」で遊ぼう
by
Tomohiko Himura
ソーシャルメディア大百科川井パート(ファンドレイジングセミナー2012より)
by
himanainu inc.
111127.lsj143.田川 japanese conjugation and dm
by
Takumi Tagawa
読書会 「トピックモデルによる統計的潜在意味解析」 第2回 3.2節 サンプリング近似法
by
健児 青木
坂井直樹と考える、デザインの歴史とこれから 先生:坂井直樹
by
schoowebcampus
俺の仕事がこんなに楽しいわけが無い・公開版(初出:2010/12/20 株式会社ECナビ会社説明会@IAMAS)
by
bash0C7
GCS2013 itowponde 0622
by
英明 伊藤
日本社会薬学会 20140914
by
遠矢 純一郎
社内SNSと巻き込み力
by
八木橋 パチ
Similar to 読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節 潜在意味空間における分類問題
PDF
PRML輪読#4
by
matsuolab
PPTX
【学会発表】LDAにおけるベイズ汎化誤差の厳密な漸近形【IBIS2020】
by
Naoki Hayashi
PDF
PRML勉強会@長岡 第4章線形識別モデル
by
Shohei Okada
PPTX
20150730 トピ本第4回 3.4節
by
MOTOGRILL
PDF
わかりやすいパターン認識 4章
by
Motokawa Tetsuya
PDF
EMNLP 2011 reading
by
正志 坪坂
PPTX
SVMについて
by
mknh1122
PDF
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
PDF
3.4
by
show you
PDF
PRML Chapter 14
by
Masahito Ohue
PDF
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
PDF
サポートベクトルマシン入門
by
Wakamatz
PDF
双対性
by
Yoichi Iwata
PPTX
PRML4.3
by
hiroki yamaoka
PDF
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
PDF
データマイニング勉強会3
by
Yohei Sato
PDF
PRML 第14章
by
Akira Miyazawa
PPTX
機械学習
by
ssusere8ae711
PDF
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
PPTX
パターン認識モデル初歩の初歩
by
t_ichioka_sg
PRML輪読#4
by
matsuolab
【学会発表】LDAにおけるベイズ汎化誤差の厳密な漸近形【IBIS2020】
by
Naoki Hayashi
PRML勉強会@長岡 第4章線形識別モデル
by
Shohei Okada
20150730 トピ本第4回 3.4節
by
MOTOGRILL
わかりやすいパターン認識 4章
by
Motokawa Tetsuya
EMNLP 2011 reading
by
正志 坪坂
SVMについて
by
mknh1122
サポートベクターマシン(SVM)の数学をみんなに説明したいだけの会
by
Kenyu Uehara
3.4
by
show you
PRML Chapter 14
by
Masahito Ohue
Casual learning machine learning with_excel_no4
by
KazuhiroSato8
サポートベクトルマシン入門
by
Wakamatz
双対性
by
Yoichi Iwata
PRML4.3
by
hiroki yamaoka
PRML上巻勉強会 at 東京大学 資料 第4章4.3.1 〜 4.5.2
by
Hiroyuki Kato
データマイニング勉強会3
by
Yohei Sato
PRML 第14章
by
Akira Miyazawa
機械学習
by
ssusere8ae711
[DL輪読会]Control as Inferenceと発展
by
Deep Learning JP
パターン認識モデル初歩の初歩
by
t_ichioka_sg
読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節 潜在意味空間における分類問題
1.
1 読書会 「トピックモデルによる統計的潜在意味解析」 第6回 4.3節 潜在意味空間における分類問題 日時:
2015/09/17 19:30~ 場所: 株式会社 ALBERT 発表者: @aoki_kenji
2.
目次 2 • 4.3.1節 LDA+ロジスティック回帰モデル •
4.3.2節 LDA+多クラスロジスティック回帰モデル • 4.3.3節 LDA+SVM • 4.3.4節 LDA+SVMの学習アルゴリズム
3.
目次 3 • 4.3.1節 LDA+ロジスティック回帰モデル •
4.3.2節 LDA+多クラスロジスティック回帰モデル →時間の都合上まとめて定式化 • 4.3.3節 LDA+SVM • 4.3.4節 LDA+SVMの学習アルゴリズム
4.
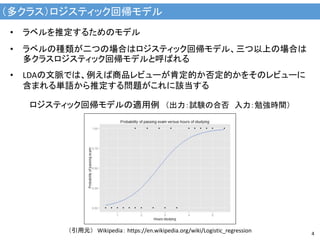
(多クラス)ロジスティック回帰モデル 4 • ラベルを推定するためのモデル • ラベルの種類が二つの場合はロジスティック回帰モデル、三つ以上の場合は 多クラスロジスティック回帰モデルと呼ばれる •
LDAの文脈では、例えば商品レビューが肯定的か否定的かをそのレビューに 含まれる単語から推定する問題がこれに該当する ロジスティック回帰モデルの適用例 (出力:試験の合否 入力:勉強時間) (引用元) Wikipedia: https://en.wikipedia.org/wiki/Logistic_regression
5.
(多クラス)ロジスティック回帰モデルの定式化 5 • 出力を𝑦、入力を𝒙とすると 𝐶
+ 1 クラスロジスティック回帰モデルは以下の式 で表わされる ※𝜼1:𝐶 = 𝜼1, ⋯ , 𝜼 𝐶 はパラメータ 𝑝 𝑦 𝒙, 𝜼1:𝐶 = exp 𝜼 𝑦 𝑇 𝒙 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒙 4.40 , 4.53 • 一般化線形モデルの式で書くと 𝑝 𝑦 𝒙, 𝜼1:𝐶 = exp 𝜼 𝑦 𝑇 𝒙 − log 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒙 (4.41)
6.
LDA+(多クラス)ロジスティック回帰モデルの定式化 6 • モデル全体は以下の式となる 𝑝 𝒚,
𝒘, 𝒛, 𝝓, 𝜽 𝜶, 𝜷, 𝜼1:𝐶 = 𝑝 𝒚 𝒛, 𝜼1:𝐶 𝑝 𝒘 𝒛, 𝝓 𝑝 𝒛 𝜽 𝑝 𝝓 𝜷 𝑝 𝜽 𝜶 • ロジスティック回帰モデルの部分は4.2節と同様に入力を 𝒛 𝑑とする 𝑝 𝒚 𝒛, 𝜼1:𝐶 = 𝑑=1 𝑀 𝑝 𝑦 𝑑 𝒛 𝑑, 𝜼1:𝐶 𝑝 𝑦 𝑑 𝒛 𝑑, 𝜼1:𝐶 = exp 𝜼 𝑦 𝑇 𝒛 𝑑 − log 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 4.42 新たに追加された部分
7.
LDA+(多クラス)ロジスティック回帰モデルの学習その1 7 • 4.2節と同様に変分ベイズ法によって学習する • 𝐹LDAをLDAの変分下限とするとLDA+(多クラス)ロジスティック回帰モデルの 変分下限は以下の式で表わされる log
𝑝 𝒚, 𝒘 𝜶, 𝜷, 𝜼1:𝐶 ≥ 𝒛 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒚, 𝒘, 𝒛, 𝝓, 𝜽 𝜶, 𝜷, 𝜼1:𝐶 𝑞 𝒛, 𝜽, 𝝓 𝑑𝜽𝑑𝝓 = 𝒛 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒚 𝒛, 𝜼1:𝐶 𝑝 𝒘 𝒛, 𝝓 𝑝 𝒛 𝜽 𝑝 𝝓 𝜷 𝑝 𝜽 𝜶 𝑞 𝒛, 𝜽, 𝝓 𝑑𝜽𝑑𝝓 = 𝐹LDA + 𝒛 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒚 𝒛, 𝜼1:𝐶 = 𝐹LDA + 𝐸 𝑞 𝒛 log 𝑝 𝒚 𝒛, 𝜼1:𝐶 4.43 • したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ • 次ページ以降で𝑞 𝒛 , 𝜼1:𝐶の更新式を導出する 新たに追加された部分
8.
LDA+(多クラス)ロジスティック回帰モデルの学習その2 8 𝐸 𝑞 𝒛
𝑑 log 𝑝 𝑦 𝑑 𝒛 𝑑, 𝜼1:𝐶 = 𝜼 𝑦 𝑑 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 𝐸 𝑞 𝒛 𝑑 log 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 4.45 , 4.54 • 上記第2項は解析的に計算できないため log 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 ≤ 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 𝜉 𝑑 + log 𝜉 𝑑 − 1 (4.44) を利用して目的関数の下限を最大化する(変分下限の下限を最大化する) • (4.43)と(4.44)から 𝐹LDA + 𝑑=1 𝑀 𝜼 𝑦 𝑑 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 1 𝜉 𝑑 𝐸 𝑞 𝒛 𝑑 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 − log 𝜉 𝑑 + 1 = 𝐹LDA + 𝐿m−logistic が新たな目的関数となる(ちなみに右辺第2項は 4.33 式から計算可能)
9.
LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その1 9 ◎𝜼 𝑐の推定 𝜕𝐿m−logistic 𝜕𝜼 𝑐 = 𝑑
𝑦 𝑑 = 𝑐 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 1 𝜉 𝑑 𝜕 𝜕𝜼 𝑐 𝐸 𝑞 𝒛 𝑑 1 + exp 𝜼 𝑐 𝑇 𝒛 𝑑 4.57 から 𝜕𝐿m−logistic 𝜕𝜼 𝑐 = 0を求めたいが解析的に解けないため共役勾配法(付録A.4)を 用いて求める(ちなみに右辺第2項は 4.35 式から計算可能)
10.
LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その2 10 ◎𝝃 𝑑の推定 𝜕𝐿m−logistic 𝜕𝝃 𝑑 = 1 𝜉
𝑑 2 𝐸 𝑞 𝒛 𝑑 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 − 1 𝜉 𝑑 = 0 4.58 から 𝜉 𝑑 = 𝐸 𝑞 𝒛 𝑑 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 4.59
11.
LDA+(多クラス)ロジスティック回帰モデルのパラメータ推定その3 11 ◎𝑞 𝑧 𝑑,𝑖
= 𝑘 の推定 𝜕𝐿m−logistic 𝜕𝑞 𝑧 𝑑,𝑖 = 𝑘 = 𝜂 𝑦 𝑑,𝑘 𝑛 𝑑 − 1 𝜉 𝑑 𝜕 𝜕𝑞 𝑧 𝑑,𝑖 = 𝑘 𝐸 𝑞 𝒛 𝑑 1 + 𝑐=1 𝐶 exp 𝜼 𝑐 𝑇 𝒛 𝑑 4.61 で、右辺第2項は 4.60 から計算可能 したがって 3.98 と合わせると 𝑞 𝑧 𝑑,𝑖 = 𝑘 ∝ exp 𝐸 𝑞 𝝓 𝑘 log 𝜙 𝑘,𝑤 𝑑,𝑖 exp 𝐸 𝑞 𝜽 𝑑 log 𝜃 𝑑,𝑘 exp 𝜕𝐿m−logistic 𝜕𝑞 𝑧 𝑑,𝑖 = 𝑘 4.62
12.
目次 12 • 4.3.1節 LDA+ロジスティック回帰モデル •
4.3.2節 LDA+多クラスロジスティック回帰モデル • 4.3.3節 LDA+SVM • 4.3.4節 LDA+SVMの学習アルゴリズム
13.
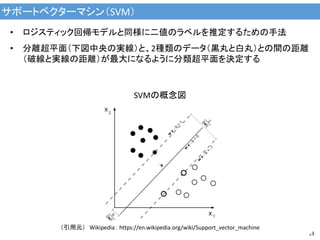
サポートベクターマシン(SVM) 13 • ロジスティック回帰モデルと同様に二値のラベルを推定するための手法 • 分離超平面(下図中央の実線)と、2種類のデータ(黒丸と白丸)との間の距離 (破線と実線の距離)が最大になるように分類超平面を決定する SVMの概念図 (引用元)
Wikipedia: https://en.wikipedia.org/wiki/Support_vector_machine
14.
ソフトマージンのサポートベクターマシン(SVM)の定式化 14 • 𝒙𝑖を前ページ図中の黒丸および白丸の座標、 𝑦𝑖を黒か白かを表わすラベル、 𝜼を分離超平面の傾きおよび切片とするとソフトマージンのSVMの最適化問題 は以下で定式化される min 𝜼,𝝃 1 2 𝜼
𝑇 𝜼 + 𝐶 𝑖=1 𝑛 𝜉𝑖 , s.t. ∀𝑖 1 − 𝑦𝑖 𝜼 𝑇 𝒙𝑖 − 𝜉𝑖 ≤ 0, 𝜉𝑖 ≥ 0 4.63 • 𝜉𝑖があるため、必ずしも1 − 𝑦𝑖 𝜼 𝑇 𝒙𝑖 ≤ 0が満たされなくてもよい • ただし𝜉𝑖は目的関数に含まれるため、𝜼と同時に小さくすることが望まれる • SVMはロジスティック回帰とは異なり確率モデルによる定式化ではないため、 LDAと組み合わせるには異なる枠組みが必要
15.
制約付きベイズ学習による枠組みその1 15 • 事後分布導出を以下の最適化問題によって定式化する min 𝑞 𝜽 𝐾𝐿
𝑞 𝜽 𝑝 𝜽 − 𝑞 𝜽 log 𝑝 𝑥1:𝑛 𝜽 𝑑𝜽 , s.t. 𝑞 𝜽 ∈ 𝑃 4.65 ここで制約条件は 𝑞 𝜽 𝑑𝜽 = 1 を表わす • 上記の解は変分法によって 𝑞 𝜽 = 𝑝 𝜽 𝑥1:𝑛 と求まる
16.
制約付きベイズ学習による枠組みその2 16 • 前ページをもう少し一般化すると min 𝑞 𝜽 𝐾𝐿
𝑞 𝜽 𝑝 𝜽 − 𝑞 𝜽 log 𝑝 𝑥1:𝑛 𝜽 𝑑𝜽 + 𝑈 𝝃 , s.t. 𝑞 𝜽 ∈ 𝑃 𝑐 𝝃 4.66 𝝃はここで制約緩和のためのスラック変数、𝑈 𝝃 は制約を破ったときの罰則金 を意味する
17.
制約付きベイズ学習による枠組みその3 17 • LDAの変分下限は −𝐹𝐿𝐷𝐴 =
− 𝒛 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒘, 𝒛, 𝝓, 𝜽 𝜶, 𝜷 𝑞 𝒛, 𝜽, 𝝓 𝑑𝜽𝑑𝝓 = − 𝒛 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒛, 𝝓, 𝜽 𝜶, 𝜷 𝑝 𝒘 𝒛, 𝝓, 𝜽 𝑞 𝒛, 𝜽, 𝝓 𝑑𝜽𝑑𝝓 = 𝐾𝐿 𝑞 𝒛, 𝜽, 𝝓 𝑝 𝒛, 𝝓, 𝜽 𝜶, 𝜷 − 𝑞 𝒛, 𝜽, 𝝓 log 𝑝 𝒘 𝒛, 𝝓, 𝜽 𝑑𝜽𝑑𝝓 なので、制約付きベイズ学習の枠組みで最適化問題として定式化すると min 𝑞 𝒛,𝝓,𝜽 −𝐹𝐿𝐷𝐴 , s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄 4.69 𝑄は因子化仮定を表わす
18.
制約付きベイズ学習による枠組みその4 18 • 一方で、SVMの定式化 4.63
を以下のように解釈する min 𝜼,𝝃 − log 𝑝 𝜼 + 𝐶 𝑖=1 𝑛 𝜉𝑖 , s.t. ∀𝑖 1 − 𝑦𝑖 𝜼 𝑇 𝒙𝑖 − 𝜉𝑖 ≤ 0, 𝜉𝑖 ≥ 0 4.67 ここで、 𝑝 𝜼 = 1 2𝜋 𝐷 exp − 1 2 𝜼 𝑇 𝜼 を𝜼の事前分布と仮定し、𝜼を点推定することを考える
19.
制約付きベイズ学習による枠組みその4 19 • したがって、 4.69
と 4.67 を組み合わせて、LDA+SVMを以下の式で定式化 する min 𝑞 𝒛,𝝓,𝜽 ,𝜼,𝝃 −𝐹𝐿𝐷𝐴 − log 𝑝 𝜼 + 𝐶 𝑑=1 𝑀 𝜉 𝑑 , s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄, ∀𝑑 1 − 𝑦 𝑑 𝜼 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 𝜉 𝑑 ≤ 0, 𝜉 𝑑 ≥ 0 4.70 新たに追加された部分
20.
目次 20 • 4.3.1節 LDA+ロジスティック回帰モデル •
4.3.2節 LDA+多クラスロジスティック回帰モデル • 4.3.3節 LDA+SVM • 4.3.4節 LDA+SVMの学習アルゴリズム
21.
LDA+SVMの学習その1 21 • 制約付き最適化問題 4.70
のラグランジュ関数は、𝜆 𝑑, 𝛾 𝑑をラグランジュ乗数 とすると、以下の式で表わされる 𝐿 𝑞 𝒛 , 𝑞 𝜽 , 𝑞 𝝓 , 𝜼, 𝝀, 𝜸 = −𝐹𝐿𝐷𝐴 + 1 2 𝜼 𝑇 𝜼 + 𝐶 𝑑=1 𝑀 𝜉 𝑑 + 𝑑=1 𝑀 𝜆 𝑑 1 − 𝑦 𝑑 𝜼 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 𝜉 𝑑 + 𝑑=1 𝑀 𝛾 𝑑 𝜉 𝑑 4.71 • したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ • 𝜼, 𝝀, 𝜸の更新は𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 が与えられたもとでSVMの学習アルゴリズムをその まま適用することができる • 次ページ以降で𝑞 𝒛 の更新式を導出する
22.
LDA+SVMのパラメータ推定その1 22 ◎𝑞 𝑧 𝑑,𝑖
= 𝑘 の推定 𝜕 𝜕𝑞 𝑧 𝑑,𝑖 = 𝑘 𝜼 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 = 𝜂 𝑘 𝑛 𝑑 4.73 , 4.74 より、 3.98 と合わせると 𝑞 𝑧 𝑑,𝑖 = 𝑘 ∝ exp 𝐸 𝑞 𝝓 𝑘 log 𝜙 𝑘,𝑤 𝑑,𝑖 exp 𝐸 𝑞 𝜽 𝑑 log 𝜃 𝑑,𝑘 exp 𝜆 𝑑 𝑦 𝑑 𝜂 𝑘 𝑛 𝑑 4.75 したがって、大きい𝜆 𝑑に対応する文書(サポートベクター)ほど、SVMの学習結果 𝜼の影響を強く受ける
23.
LDA+SVMのパラメータ推定その2 23 • 次に𝜼の点推定でなく事後分布を求める場合を考える(𝜼に関しても変分近似 を仮定する) • 4.70
は以下のように書き換えられる min 𝑞 𝒛,𝝓,𝜽,𝜼 ,𝝃 −𝐹𝐿𝐷𝐴 + 𝐾𝐿 𝑞 𝜼 𝑝 𝜼 + 𝐶 𝑑=1 𝑀 𝜉 𝑑 , s.t. 𝑞 𝒛, 𝝓, 𝜽, 𝜼 ∈ 𝑄, ∀𝑑 1 − 𝑦 𝑑 𝐸 𝑞 𝒛 𝑑,𝜼 𝜼 𝑇 𝒛 𝑑 − 𝜉 𝑑 ≤ 0, 𝜉 𝑑 ≥ 0 4.76 • 実は𝑞 𝜼 として𝑁 𝝁, 𝑰 を仮定しても同じ最適化問題となる(証明は162ページ を参照)ので上記の最適化問題は以下のように書き換えられる min 𝑞 𝒛,𝝓,𝜽 ,𝝁,𝝃 −𝐹𝐿𝐷𝐴 + 1 2 𝝁 𝑇 𝝁 + 𝐾 + 𝐶 𝑑=1 𝑀 𝜉 𝑑 , s.t. 𝑞 𝒛, 𝝓, 𝜽 ∈ 𝑄, ∀𝑑 1 − 𝑦 𝑑 𝝁 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 𝜉 𝑑 ≤ 0, 𝜉 𝑑 ≥ 0 4.76 変更があった部分
24.
LDA+SVMのパラメータ推定その3 24 • 制約付き最適化問題 4.76
のラグランジュ関数は、𝜆 𝑑, 𝛾 𝑑をラグランジュ乗数 とすると、以下の式で表わされる 𝐿 𝑞 𝒛 , 𝑞 𝜽 , 𝑞 𝝓 , 𝑞 𝜼 , 𝝀, 𝜸 = −𝐹𝐿𝐷𝐴 + 1 2 𝝁 𝑇 𝝁 + 𝐾 + 𝐶 𝑑=1 𝑀 𝜉 𝑑 + 𝑑=1 𝑀 𝜆 𝑑 1 − 𝑦 𝑑 𝝁 𝑇 𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 − 𝜉 𝑑 + 𝑑=1 𝑀 𝛾 𝑑 𝜉 𝑑 4.83 • したがって𝑞 𝜽 , 𝑞 𝝓 の更新式はLDAと同じ • 𝝁, 𝝀, 𝜸の更新は𝐸 𝑞 𝒛 𝑑 𝒛 𝑑 が与えられたもとでSVMの学習アルゴリズムをその まま適用することができる • 𝑞 𝒛 の更新式 4.75 も𝜼が𝝁に変わっただけ
Download






















![[DL輪読会]深層強化学習はなぜ難しいのか?Why Deep RL fails? A brief survey of recent works.](https://cdn.slidesharecdn.com/ss_thumbnails/20210115dlohta-210115054939-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Conditional Neural Processes](https://cdn.slidesharecdn.com/ss_thumbnails/conditionalneuralprocesses-180727001730-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]“Spatial Attention Point Network for Deep-learning-based Robust Autono...](https://cdn.slidesharecdn.com/ss_thumbnails/20210729kokiyamane-210730035349-thumbnail.jpg?width=640&height=640&fit=bounds)










![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)






































![[DL輪読会]Control as Inferenceと発展](https://cdn.slidesharecdn.com/ss_thumbnails/20191004-191204055019-thumbnail.jpg?width=640&height=640&fit=bounds)
