/214
DNNを音響モデルとして用いたTTSの枠組み
𝒙
⋯
𝒀
Acoustic models
⋯
⋯
𝒙1
𝒙 𝑇
𝒀1
𝒀𝑇
Spectrum
Continuous F0
Voiced / unvoiced
Band
aperiodicity
Linguistic
feats.
Static-dynamic
mean vectors
(generated speech feats.)
[Zen et al., 2013.]
⋯⋯
0
0
1
1
a
i
u
1
2
3
Phoneme
Accent
Mora
position
Frame
position
etc.
0

![/21
音声合成:
– 入力情報から音声を人工的に合成する技術
統計的パラメトリック音声合成:
– 音声特徴量を統計モデルによりモデル化 & 生成
• Deep Neural Network (DNN) 音声合成 [Zen et al., 2013.]
– 利点: 高い汎用性 & 容易な応用
• アミューズメント応用 [Doi et al., 2013.] や 言語教育 [高道 他, 2015.] など
– 欠点: 合成音声の音質劣化
• 生成される特徴量系列の過剰な平滑化が一因
1
研究分野: 統計的パラメトリック音声合成
テキスト音声合成:
Text-To-Speech (TTS)
Text Speech](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-2-320.jpg)
![/21
改善策: 自然 / 合成音声特徴量の分布の違いを補償
– 分布の2次モーメント (系列内変動など) [Toda et al., 2007.]
– ヒストグラム [Ohtani et al., 2012.]
本発表: Anti-spoofing に敵対するDNNテキスト音声合成
– 声のなりすましを防ぐ anti-spoofing を詐称するように学習
– 自然 / 合成音声特徴量の分布の違いを敵対的学習で補償
• 従来の補償手法の拡張に相当 [Goodfellow et al., 2014.]
結果:
– 従来のDNN音響モデル学習と比較して音質が改善
– 提案手法におけるハイパーパラメータ設定の頑健性を確認
2
本発表の概要](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-3-320.jpg)

![/214
DNNを音響モデルとして用いたTTSの枠組み
𝒙
⋯
𝒀
Acoustic models
⋯
⋯
𝒙1
𝒙 𝑇
𝒀1
𝒀 𝑇
Spectrum
Continuous F0
Voiced / unvoiced
Band
aperiodicity
Linguistic
feats.
Static-dynamic
mean vectors
(generated speech feats.)
[Zen et al., 2013.]
⋯⋯
0
0
1
1
a
i
u
1
2
3
Phoneme
Accent
Mora
position
Frame
position
etc.
0](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-5-320.jpg)
![/21
従来のDNN音響モデル学習:
Minimum Generation Error (MGE) 学習
5
Generation
error
𝐿G 𝒚, ෝ𝒚
Linguistic
feats.
[Wu et al., 2016.]
Natural
speech
feats.
𝐿G 𝒚, ෝ𝒚 =
1
𝑇
ෝ𝒚 − 𝒚 ⊤ ෝ𝒚 − 𝒚 → Minimize
𝒚
ML-based
parameter
generation
Generated
speech
feats.
ෝ𝒚
Acoustic models
𝒙
⋯
𝒀
⋯
⋯
𝒙1
𝒙 𝑇](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-6-320.jpg)
![/216
MGE学習の問題点: 自然音声と異なる特徴量の分布
Natural MGE
21st mel-cepstral coefficient
23rdmel-cepstral
coefficient
自然音声と比較して特徴量の分布が縮小...
(系列内変動[Toda et al., 2007.] は分布の2次モーメントを明示的に補償)](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-7-320.jpg)

![/21
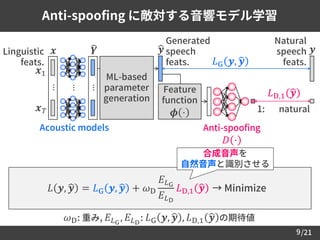
Anti-spoofing:
合成音声による声のなりすましを防ぐ識別器
8
[Wu et al., 2016.] [Chen et al., 2015.]
𝐿D,1 𝒚 𝐿D,0 ෝ𝒚
𝐿D 𝒚, ෝ𝒚 = → Minimize−
1
𝑇
𝑡=1
𝑇
log 𝐷 𝒚 𝑡 −
1
𝑇
𝑡=1
𝑇
log 1 − 𝐷 ෝ𝒚 𝑡
合成音声を
合成音声と識別させる
自然音声を
自然音声と識別させる
ෝ𝒚
Cross entropy
𝐿D 𝒚, ෝ𝒚
1: natural
0: generated
Generated
speech feats.
𝒚Natural
speech feats.
Feature
function
𝝓 ⋅
本発表では
𝝓 𝒚 𝑡 = 𝒚 𝑡
Anti-spoofing
𝐷 ⋅
or](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-9-320.jpg)
![/21
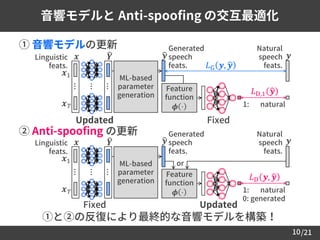
音響モデル学習の損失関数:
– 敵対的学習 [Goodfellow et al., 2014.] と生成誤差最小化の組合せ
• 所望の入出力間対応関係を持った敵対的学習 [Reed et al., 2016.]
– 敵対的学習 = 真のデータ分布と生成分布間の距離最小化
• 分布間の距離 = Jensen-Shannon ダイバージェンス
• 自然 / 合成音声特徴量の分布の違いを補償
11
提案手法に関する考察: 敵対的学習に基づく分布補償
⋯
𝒚
𝒙
𝒚 の分布𝐷 𝒚
ෝ𝒚 の分布
学習の進行](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-12-320.jpg)

![/21
系列内変動 (global variance): [Toda et al., 2007.]
– 特徴量分布の2次モーメント = 分布の広がり
13
系列内変動の補償
明示的に使用していないにもかかわらず,
anti-spoofing が系列内変動を自動的に補償!
Feature index
0 5 10 15 20
10-3
10-1
101
Globalvariance
Proposed
Natural
MGE
10-2
100
10-4
大
小](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-14-320.jpg)
![/21
Maximal Information Coefficient (MIC): [Reshef et al., 2011.]
– 2変量間の非線形な相関を定量化する指標
– 自然音声の特徴量間の相関は弱まる傾向 [Ijima et al., 2016.]
14
提案手法による副次的効果: 不自然な相関の緩和
Natural MGE
0
6
12
18
24
0 6 12 18 24
0.0
0.2
0.4
0.6
0.8
1.0
強
弱
Proposed
特徴量の分布や系列内変動のみならず,
特徴量間の相関も補償!
0 6 12 18 24 0 6 12 18 24](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-15-320.jpg)

![/21
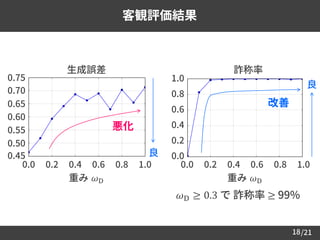
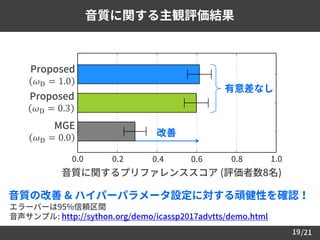
実験条件
データセット ATR 音素バランス503文 (16 kHz サンプリング)
学習 / 評価データ A-I セット 450文 / Jセット 53文
音声パラメータ 25次元のメルケプストラム, 𝐹0, 5帯域の非周期成分
コンテキストラベル 274次元 (音素, モーラ位置, アクセント型など)
前処理 Trajectory smoothing [Takamichi et al., 2015.]
予測パラメータ
メルケプストラム
(𝐹0, 非周期成分, 継続長は自然音声の特徴量を利用)
最適化アルゴリズム AdaGrad [Duchi et al., 2011.] (学習率 0.01)
音響モデル Feed-Forward 274 – 3x400 (ReLU) – 75 (linear)
Anti-spoofing Feed-Forward 25 – 2x200 (ReLU) – 1 (sigmoid)
16](https://image.slidesharecdn.com/slp201702-170217060732/85/Slp201702-17-320.jpg)























































![[DL輪読会]Discriminative Learning for Monaural Speech Separation Using Deep Embe...](https://cdn.slidesharecdn.com/ss_thumbnails/201912227dldiscriminativeleraningformanaouraspeechseparationusingdeepembeddingfeaturessumissionver2-191227001259-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Monaural Audio Source Separationusing Variational Autoencoders](https://cdn.slidesharecdn.com/ss_thumbnails/20190717dlmonauralaudiosourceseparationusingvariationalautoencodersver2-190719035345-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]音声言語病理学における機械学習とDNN](https://cdn.slidesharecdn.com/ss_thumbnails/201016dltext-to-speech-201016023355-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GANSynth: Adversarial Neural Audio Synthesis](https://cdn.slidesharecdn.com/ss_thumbnails/20180315gansynthmizuta-190315003922-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]An Iterative Framework for Self-supervised Deep Speaker Representatio...](https://cdn.slidesharecdn.com/ss_thumbnails/20220216dlaniterativeframeworkforself-superviseddeepspeakerrepresentationlearning-220218040109-thumbnail.jpg?width=640&height=640&fit=bounds)















