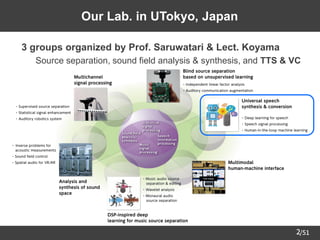
This document provides an overview of a research talk on human-in-the-loop speech synthesis technology given by Yuki Saito from the University of Tokyo. The talk was organized in two parts, with the first part presented by Saito covering human-in-the-loop deep speaker representation learning and speaker adaptation for multi-speaker text-to-speech. Saito's research group at the University of Tokyo works on text-to-speech and voice conversion using deep learning techniques. Their recent work focuses on incorporating human listeners into the training process to learn speaker representations that better capture perceptual speaker similarity.




![/51
➢ Speech synthesis
– Technology for synthesizing speech using a computer
➢ Applications
– Speech communication assistance (e.g., speech translation)
– Entertainments (e.g., singing voice synthesis/conversion)
➢ DNN-based speech synthesis [Zen+13][Oord+16]
– Using a DNN for learning statistical relation betw. input-to-speech
6
Research Field: Speech Synthesis
Text-To-Speech (TTS)
Text Speech
Voice Conversion (VC)
Output
speech
Input
speech
Hello Hello
[Sagisaka+88]
[Stylianou+88]
DNN: Deep Neural Network](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-7-320.jpg)
![/51
➢ SOTA DNN-based speech synthesis methods
– Quality of synthetic speech: as natural as human speech
– Adversarial training betw. two DNNs (i.e., GANs [Goodfellow+14])
• Ours [Saito+18], MelGAN [Kumar+19], Parallel WaveGAN [Yamamoto+20],
HiFi-GAN [Kong+20], VITS [Kim+21], JETS [Lim+22], etc...
7
Discriminator
1: natural
Adversarial
loss
𝒙
Input
feats.
Acoustic model
(generator)
ෝ
𝒚 Synthetic
speech
Natural
speech
𝒚
General Background
Reconstruction
loss
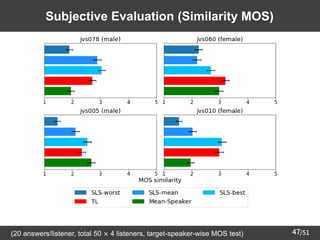
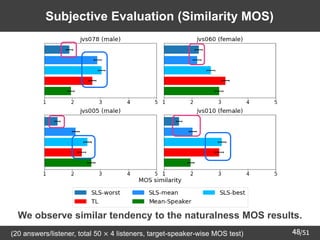
GAN: Generative Adversarial Network](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-8-320.jpg)
![/51
➢ SOTA DNN-based speech synthesis methods
– Quality of synthetic speech: as natural as human speech
– Adversarial training betw. two DNNs (i.e., GANs [Goodfellow+14])
• Ours [Saito+18], MelGAN [Kumar+19], Parallel WaveGAN [Yamamoto+20],
HiFi-GAN [Kong+20], VITS [Kim+21], JETS [Lim+22], etc...
8
Human listener
Human
perception
𝒙
Input
feats.
Acoustic model
(generator)
ෝ
𝒚 Synthetic
speech
Natural
speech
𝒚
General Background
Reconstruction
loss
GAN: Generative Adversarial Network
Can we replace the GAN discriminator with a human listener?](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-9-320.jpg)
![/51
9
Motivation of Human-In-The-Loop
Speech Synthesis Technologies
➢ Speech communication: intrinsically imperfect
– Humans often make mistakes, but we can communicate!
• Mispronunciations, wrong accents, unnatural pausing, etc...
– Mistakes can be corrected thru interaction betw. speaker & listener.
• c.f., Machine speech chain (speech synth. & recog.) [Tjandra+20]
– Intervention of human listeners will cultivate advanced research field!
➢
Possible applications
– Human-machine interaction
• e.g., spoken dialogue systems
– Media creation
• e.g., singing voice synthesis & dubbing
The image was automatically generated by craiyon](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-10-320.jpg)

![/51
11
Overview: Deep Speaker Representation Learning
➢ Deep Speaker Representation Learning (DSRL)
– DNN-based technology for learning Speaker Embeddings (SEs)
• Feature extraction for discriminative tasks (e.g., [Variani+14])
• Control of speaker ID in generative tasks (e.g., [Jia+18])
➢ This talk: method to learn SEs suitable for generative tasks
– Purpose: improving quality & controllability of synthetic speech
– Core idea: introducing human listeners for learning SEs that are highly
correlated with perceptual similarity among speakers
DNN
NG
ASV
DNN
TTS
Discriminative task
(e.g., automatic speaker verification: ASV)
Generative task
(e.g., TTS and VC)
DNN: Deep Neural Network](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-12-320.jpg)
![/51
12
Conventional Method:
Speaker-Classification-Based DSRL
➢ Learning to predict speaker ID from input speech parameters
– SEs suitable for speaker classification → also suitable for TTS/VC?
– One reason: low interpretability of SEs
Minimizing
cross-entropy
Speech
params.
d-vectors
[Variani+14]
Spkr.
classification
Spkr.
encoder
Spkr.
IDs
Distance metric in SE space
≠
Perceptual metric
(i.e., speaker similarity)
SE
space](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-13-320.jpg)
![/51
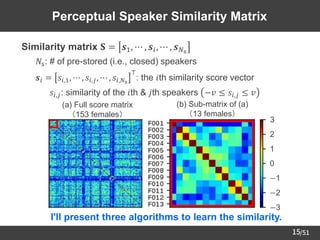
14
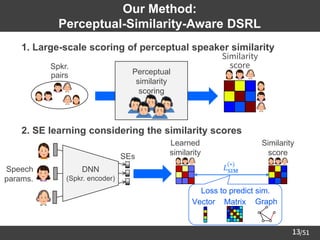
Large Scale Scoring of
Perceptual Speaker Similarity
➢ Crowdsourcing of perceptual speaker similarity scores
– Dataset we used: 153 females in JNAS corpus [Itou+99]
– 4,000↑ listeners scored the similarity of two speakers' voices.
➢ Histogram of the collected scores
Instruction of the scoring
To what degree do these two speakers'
voices sound similar?
(−3: dissimilar ~ +3: similar)
( , ) → +2
( , ) → −3
( , ) → −2](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-15-320.jpg)
![/51
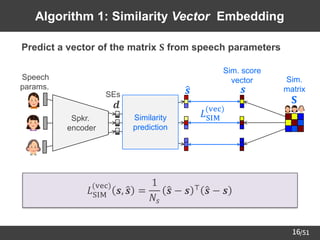
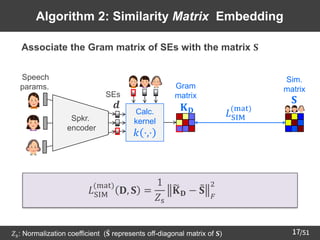
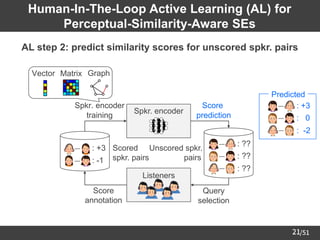
18
Algorithm 3: Similarity Graph Embedding
➢ Learn the structure of speaker similarity graph from SE pairs
𝐿SIM
graph
𝒅𝑖, 𝒅𝑗 = −𝑎𝑖,𝑗 log 𝑝𝑖,𝑗 − 1 − 𝑎𝑖,𝑗 log 1 − 𝑝𝑖,𝑗
Spkr. sim.
graph
Edge
prediction 0: no edge
1: exist edge
𝐿SIM
(graph)
𝑝𝑖,𝑗 = exp − 𝒅𝑖 − 𝒅𝑗 2
2
: edge probability (referring to [Li+18])
Spkr.
encoder
𝐒
Sim.
matrix
Speech
params.
𝒅
𝑎𝑖,𝑗
SEs](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-19-320.jpg)
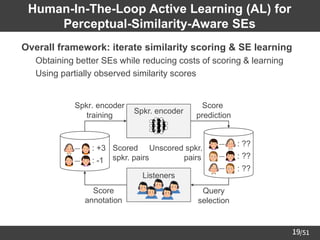

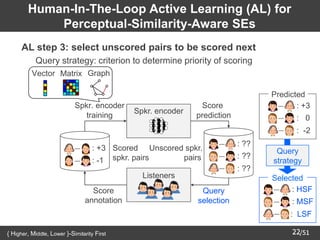
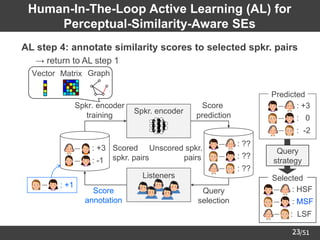

![/51
25
Experimental Conditions
Dataset
(16 kHz sampling)
JNAS [Itou+99] 153 female speakers
5 utterances per speaker for scoring
About 130 / 15 utterances for DSRL & evaluation
(F001 ~ F013: unseen speakers for evaluation)
Similarity score
-3 (dissimilar) ~ +3 (similar)
(Normalized to [-1, +1] or [0, 1] in DSRL)
Speech parameters
40-dimensional mel-cepstra, F0, aperiodicity
(extracted by STRAIGHT analysis [Kawahara+99])
DNNs Fully-connected (for details, please see our paper)
Dimensionality of SEs 8
AL setting
Pool-based simulation
(Using binary masking for excluding unobserved scores)
DSRL methods
Conventional: d-vectors [Variani+14]
Ours: Prop. (vec), Prop. (mat), or Prop. (graph)](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-26-320.jpg)
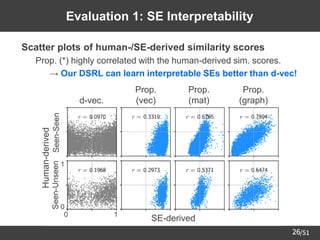
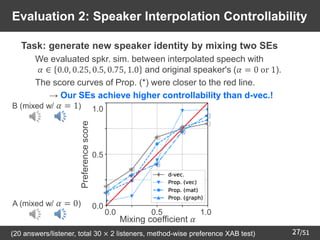
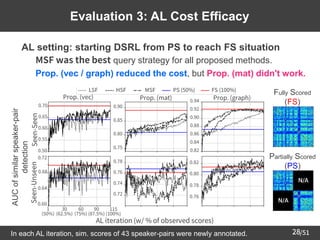


![/51
31
Overview: Speaker Adaptation for
Multi-Speaker TTS
➢ Text-To-Speech (TTS) [Sagisaka+88]
– Technology to artificially synthesize speech from given text
➢
DNN-based multi-speaker TTS [Fan+15][Hojo+18]
– Single DNN to generate multiple speakers' voices
• SE: conditional input to control speaker ID of synthetic speech
➢
Speaker adaptation for multi-speaker TTS (e.g., [Jia+18])
– TTS of unseen speaker's voice with small amount of data
Text-To-Speech (TTS)
Text Speech
SE
Multi-speaker
TTS model](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-32-320.jpg)
![/51
32
Conventional Speaker Adaptation Method
➢ Transfer Learning (TL) from speaker verification [Jia+18]
– Speaker encoder for extracting SE from reference speech
• Pretrained on speaker verification (e.g., GE2E loss [Wan+18])
– Multi-speaker TTS model for synthesizing speech from (text, SE) pairs
• Training: generate voices of seen speakers (∈ training data)
• Inference: extract SE of unseen speaker & input to TTS model
– Issue: cannot be used w/o the reference speech
• e.g., deceased person w/o any speech recordings
Multi-speaker
TTS model
Speaker
encoder
Ref.
speech
FROZEN
Can we find the target speaker's SE w/o using ref. speech?](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-33-320.jpg)
![/51
33
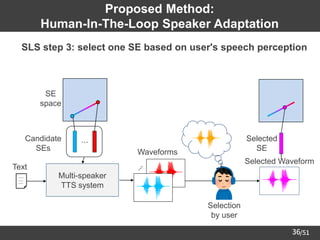
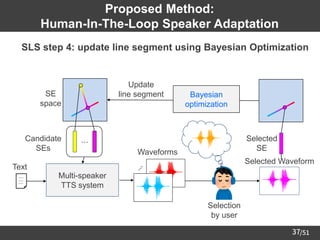
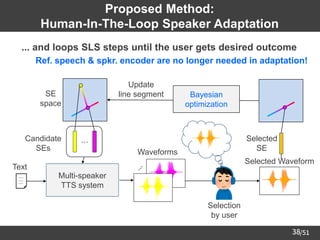
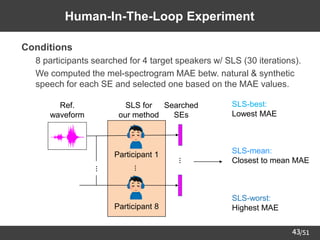
Proposed Method:
Human-In-The-Loop Speaker Adaptation
➢ Core algorithm: Sequential Line Search (SLS) [Koyama+17] on SE space
Multi-speaker
TTS system
Text ⋰
Waveforms
Candidates
SEs
⋯
SE
space
Bayesian
optimization
Update
line segment
SE selection
by user
Selected
SE
Selected Waveform](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-34-320.jpg)
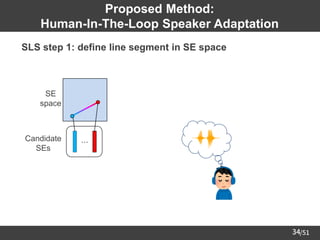
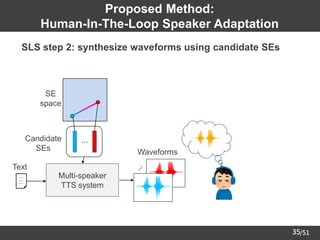


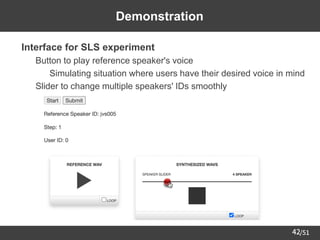
![/51
41
Experimental Conditions
Corpus for training
speaker encoder
Corpus of Spontaneous Japanese (CSJ) [Maekawa03]
(947 males and 470 females, 660h)
TTS model FastSpeech 2 [Ren+21]
Corpus for TTS
model
"parallel100" subset of Japanese Versatile Speech (JVS) corpus
[Takamichi+20]
(49 males and 51 females, 22h, 100 sentences / speaker)
Data
split
Train 90 speakers (44 males, 46 females)
Test 4 speakers (2 males, 2 females)
Validation 6 speakers (3 males, 3 females)
Vocoder
Pretrained "universal_v1" model of HiFi-GAN [Kong+20]
(published in ming024's GitHub repository)](https://image.slidesharecdn.com/saito22researchtalknuspublished-220918030601-acff1aeb/85/saito22research_talk_at_NUS-42-320.jpg)
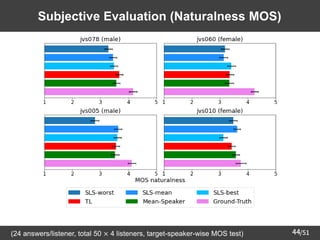
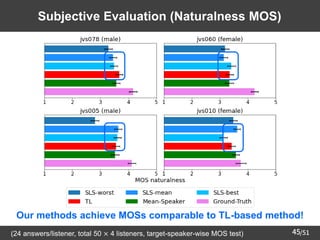
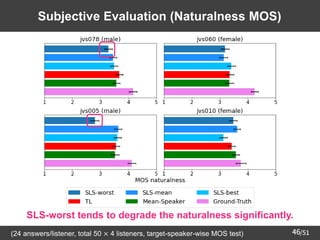

























![[GAN by Hung-yi Lee]Part 3: The recent research of my group](https://cdn.slidesharecdn.com/ss_thumbnails/part3v2-180809095433-thumbnail.jpg?width=640&height=640&fit=bounds)





























![ANIMAL_CELL_,_TISSUE_AND_ORGAN_CULTURE[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/animalcelltissueandorganculture1-260204172026-4462b440-thumbnail.jpg?width=640&height=640&fit=bounds)













