再利用?新規生成?
• 再利用
• 新規生成
–テンプレート
主語+動詞の文を生成しよう
– 非テンプレート
A small gray dog
on a leash.
A black dog
standing in
grassy area.
A small white dog
wearing a flannel
warmer.
入力 データセット
16.
再利用?新規生成?
• 再利用
– Asmall gray dog on a leash.
• 新規生成
– テンプレート
主語+動詞の文を生成しよう
– 非テンプレート
A small gray dog
on a leash.
A black dog
standing in
grassy area.
A small white dog
wearing a flannel
warmer.
入力 データセット
17.
再利用?新規生成?
• 再利用
– Asmall gray dog on a leash.
• 新規生成
– テンプレート
dog+stand ⇒ A dog stands.
– 非テンプレート
A small gray dog
on a leash.
A black dog
standing in
grassy area.
A small white dog
wearing a flannel
warmer.
入力 データセット
18.
再利用?新規生成?
• 再利用
– Asmall gray dog on a leash.
• 新規生成
– テンプレート
dog+stand ⇒ A dog stands.
– 非テンプレート
A small white dog standing on a leash.
A small gray dog
on a leash.
A black dog
standing in
grassy area.
A small white dog
wearing a flannel
warmer.
入力 データセット
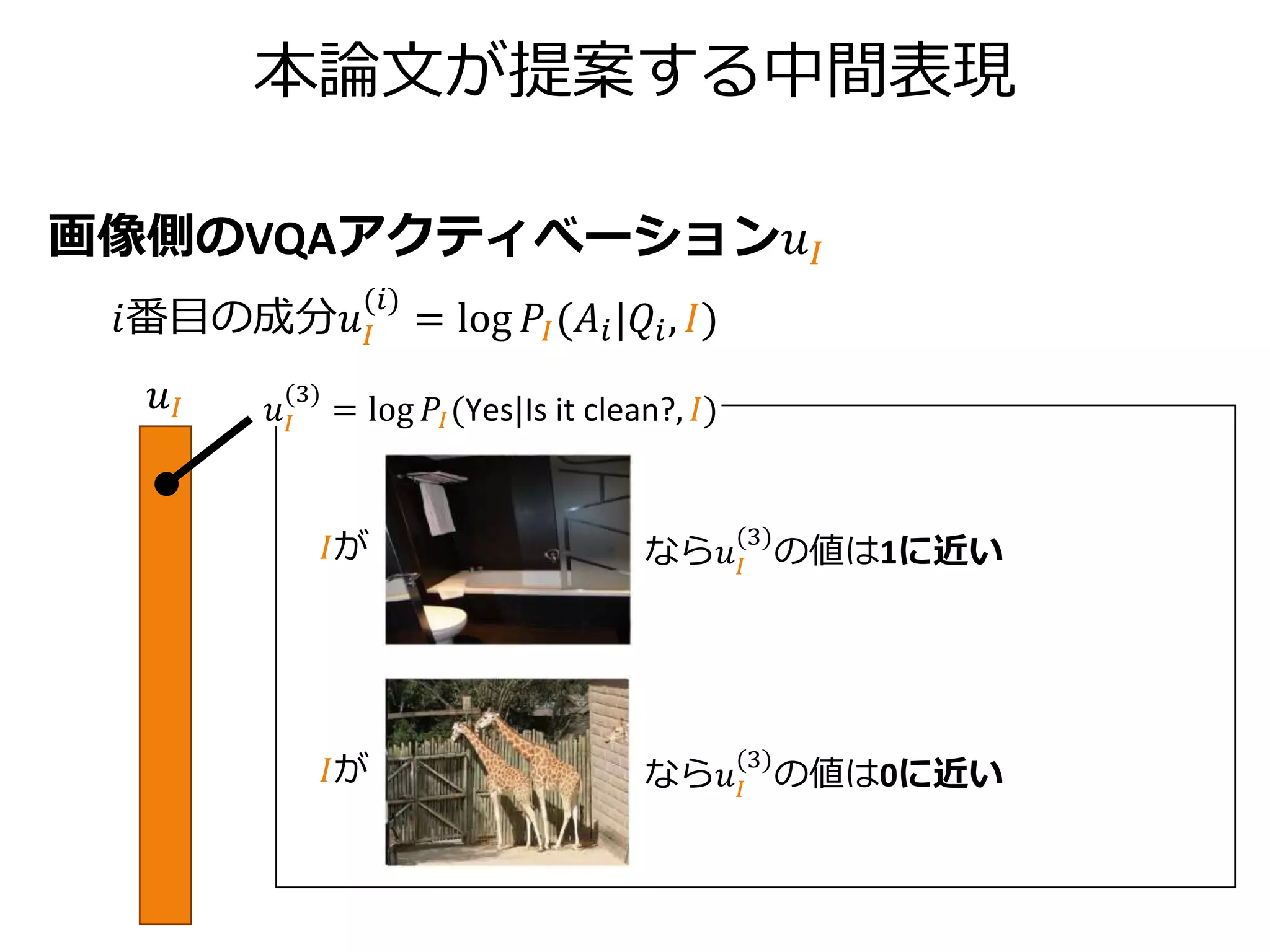
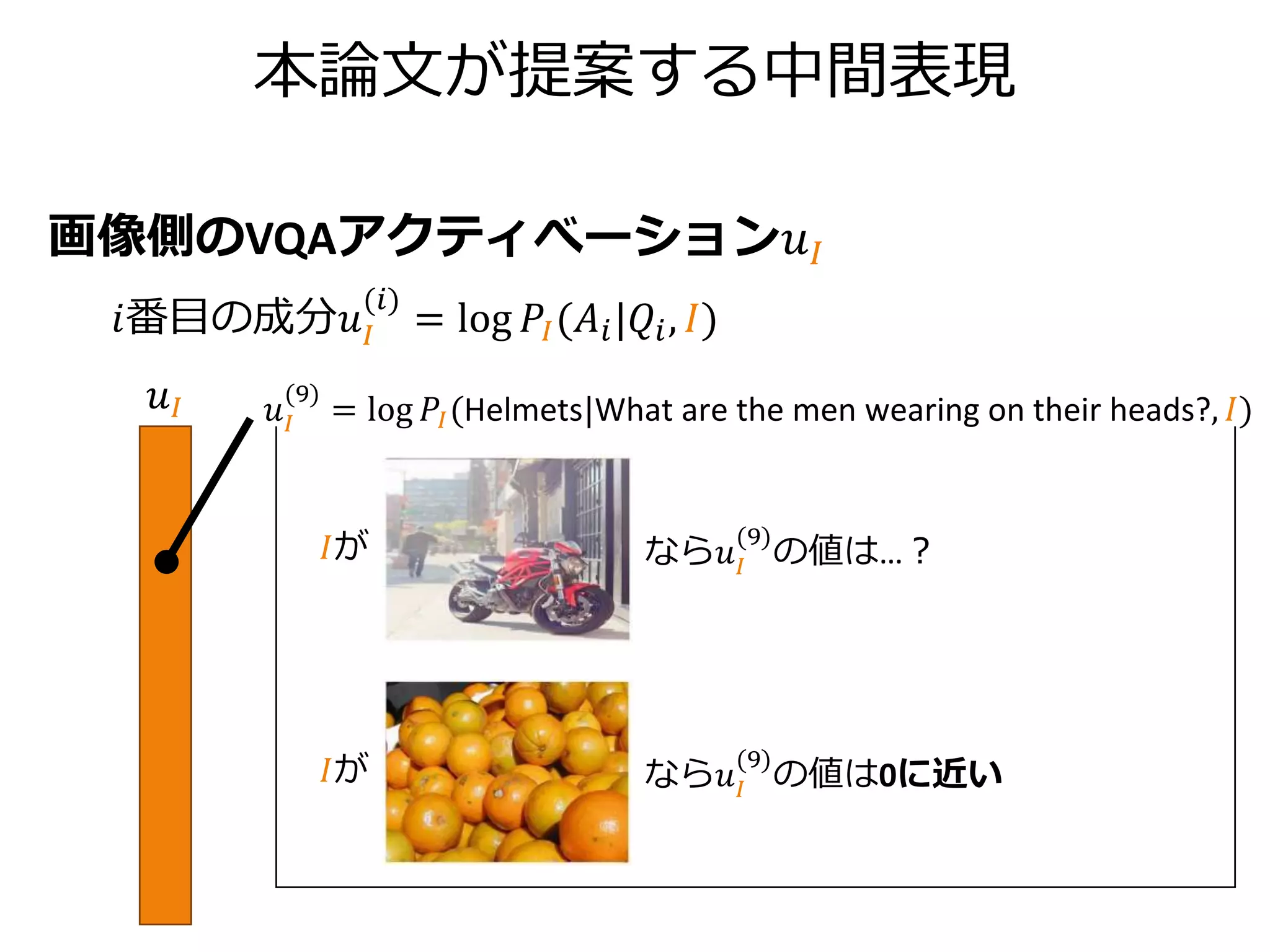
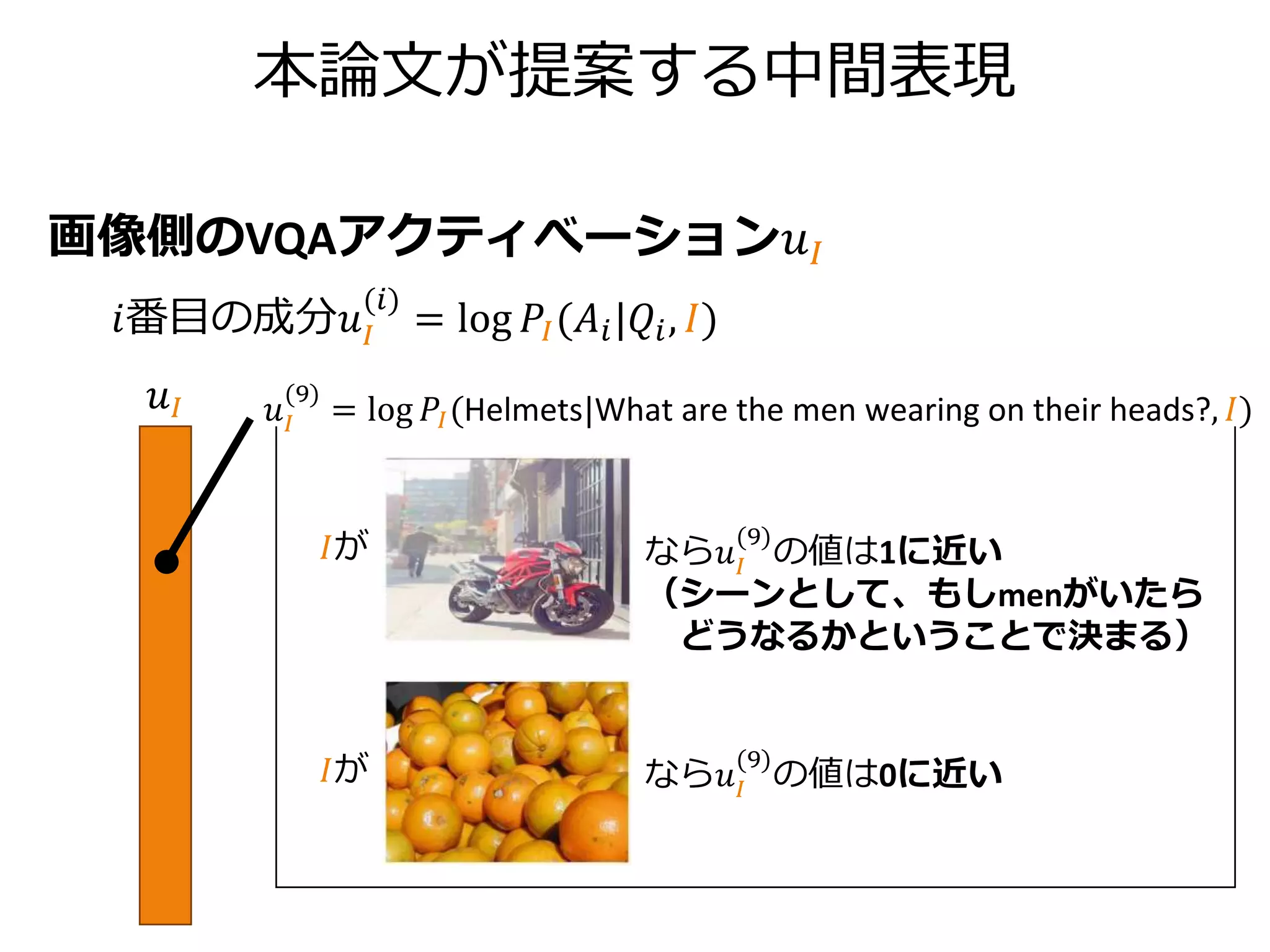
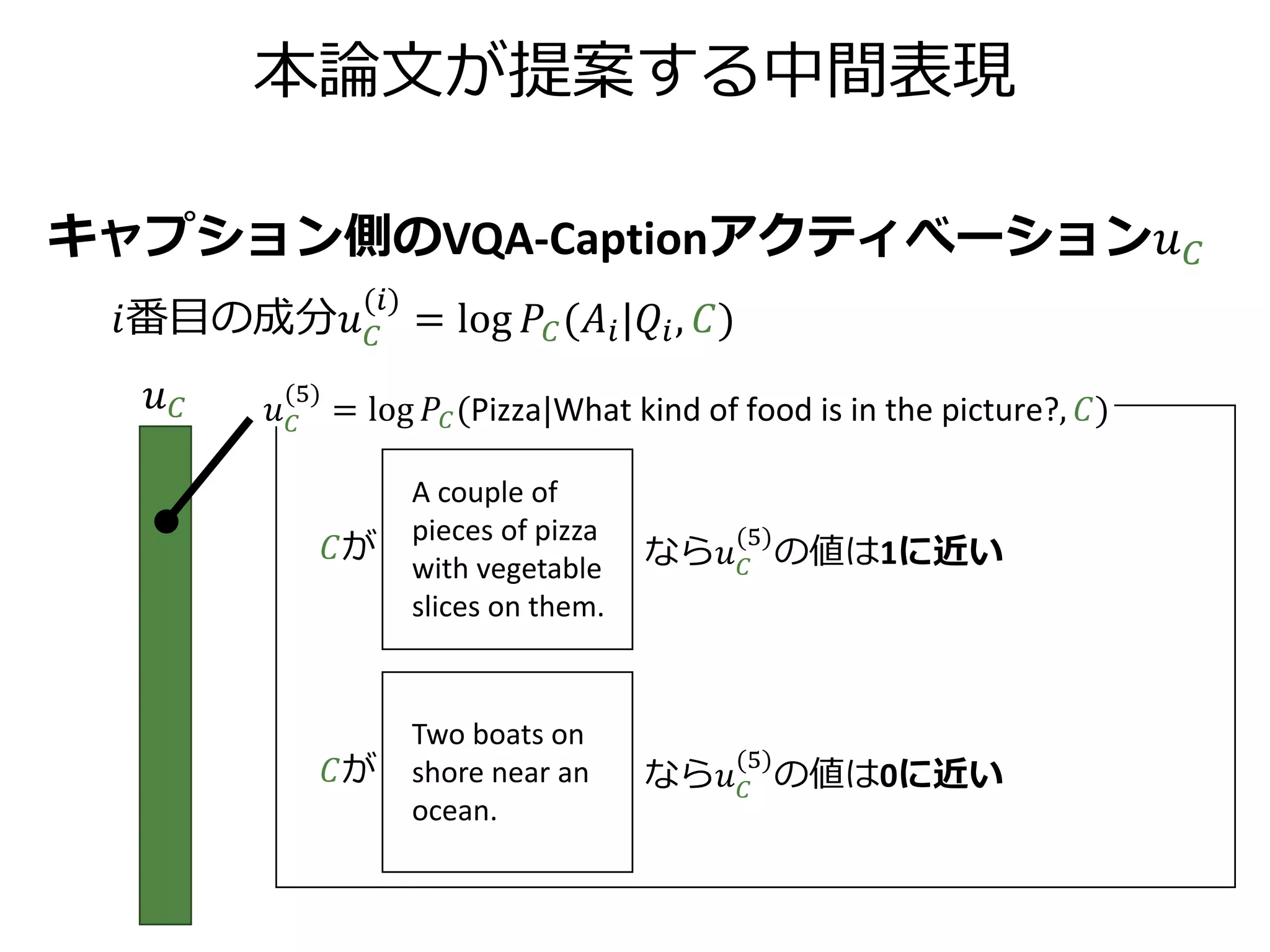
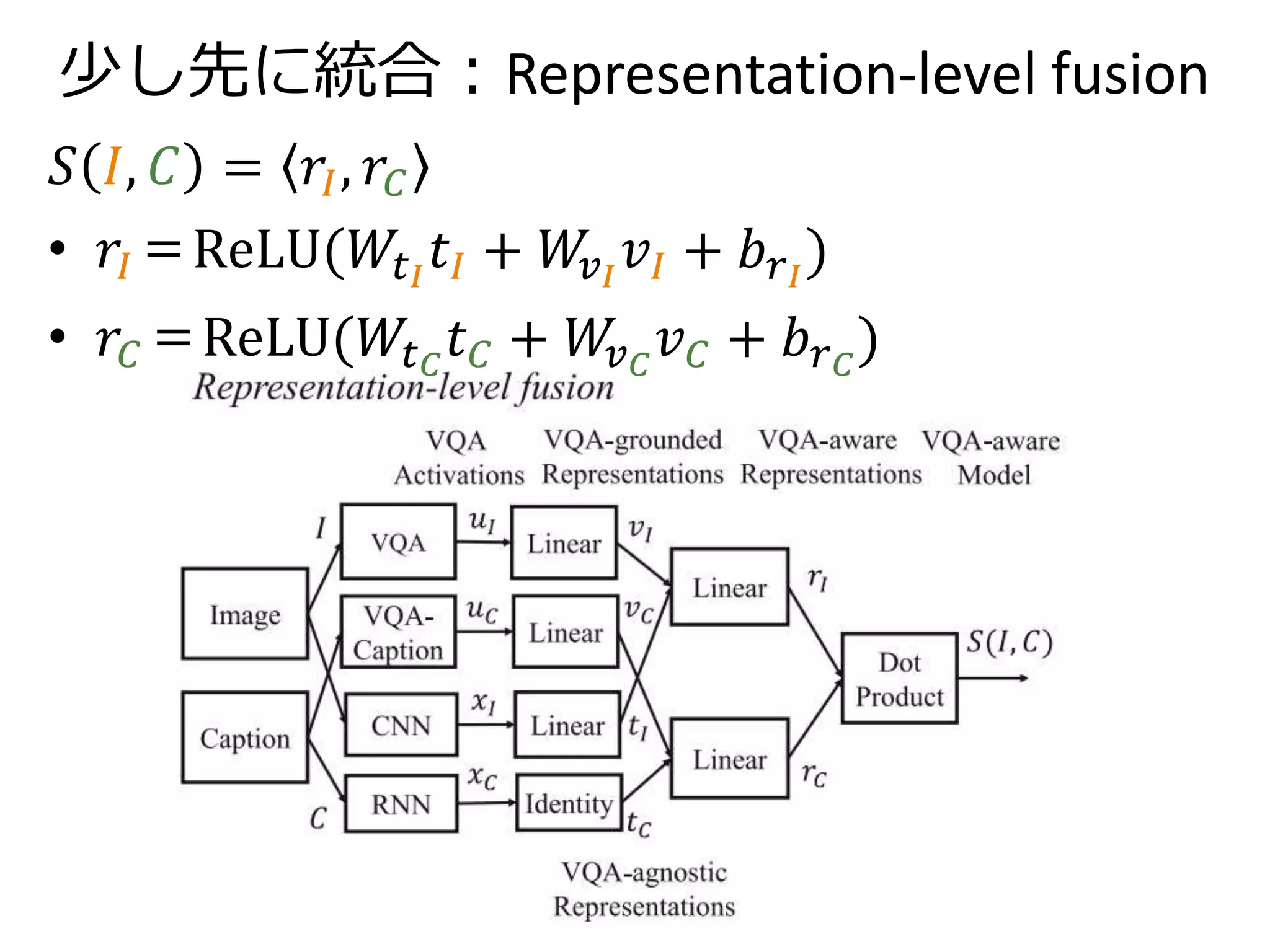
本論文が提案する中間表現
キャプション側のVQA-Captionアクティべーション𝑢 𝐶
𝑖番目の成分𝑢 𝐶
(𝑖)
=log 𝑃𝐶(𝐴𝑖|𝑄𝑖, 𝐶)
𝑢 𝐶
𝐶が なら𝑢 𝐶
(5)
の値は0に近い
𝐶が なら𝑢 𝐶
(5)
の値は負の値
𝑢 𝐶
(5)
= log 𝑃𝐶(Pizza|What kind of food is in the picture?, 𝐶)
A couple of
pieces of pizza
with vegetable
slices on them.
Two boats on
shore near an
ocean.










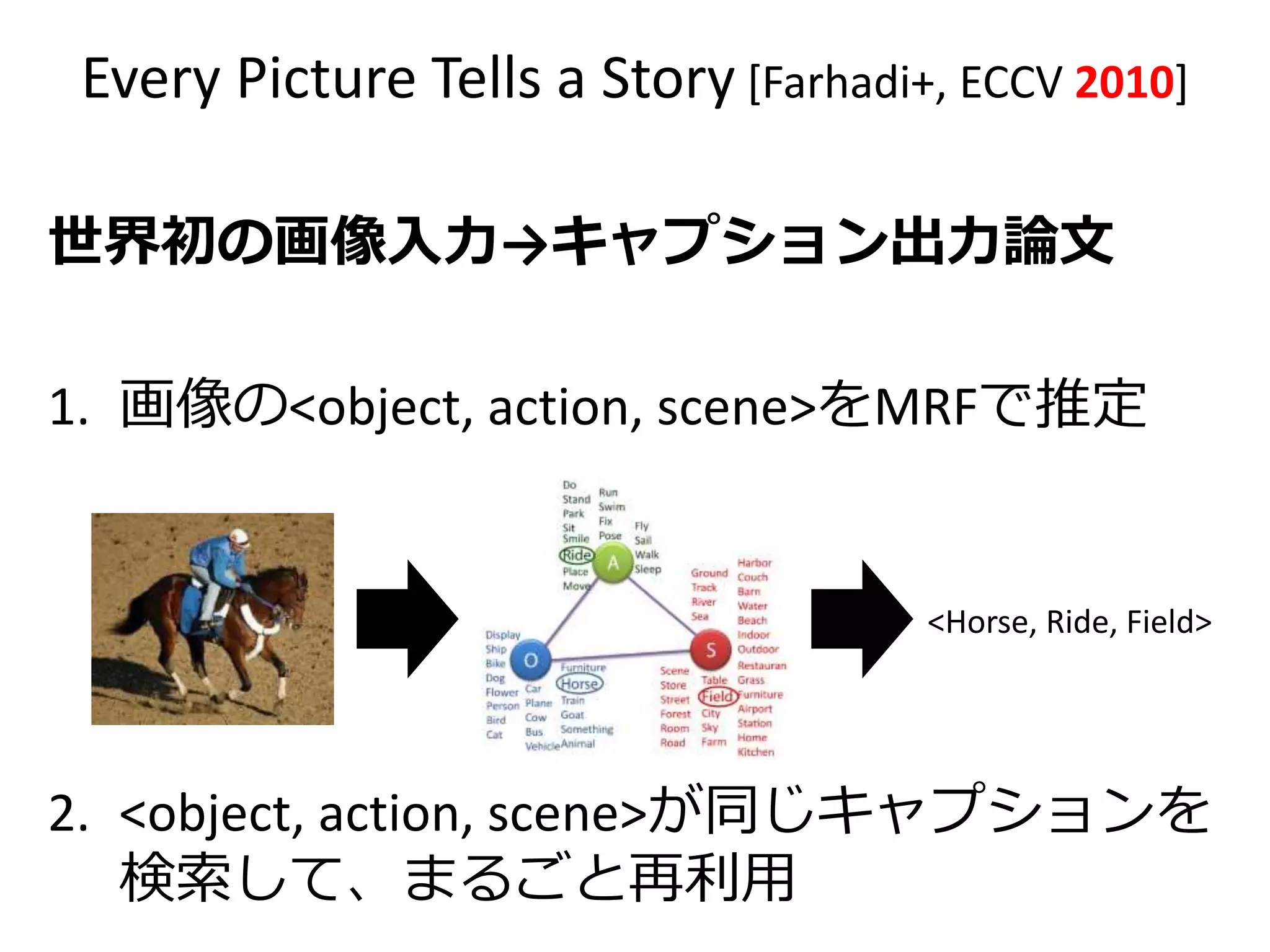
![Every Picture Tells a Story [Farhadi+, ECCV 2010]
世界初の画像入力→キャプション出力論文
1. 画像の<object, action, scene>をMRFで推定
2. <object, action, scene>が同じキャプションを
検索して、まるごと再利用
<Horse, Ride, Field>](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-13-2048.jpg)
![Every Picture Tells a Story [Farhadi+, ECCV 2010]](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-14-2048.jpg)



![cf. 非テンプレート型新規キャプション生成
画像の内容を表す少数の単語列(フレーズ)の推定
+単語列を文法モデルによって連結
[Ushiku+, ACM MM 2012]
最近の Neural Image Captioningとの比較
[Wu+, CVPR 2016][You+, CVPR 2016]
1. 単語/単語列を推定する部分
FV+SVM か CNN かの違い
2. 文法モデルを含めて連結する部分
対数線形モデルか RNN かの違い](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-19-2048.jpg)

![今日紹介する論文では…
Multimodal Neural Language Models [Kiros+, TACL 2015] を採用
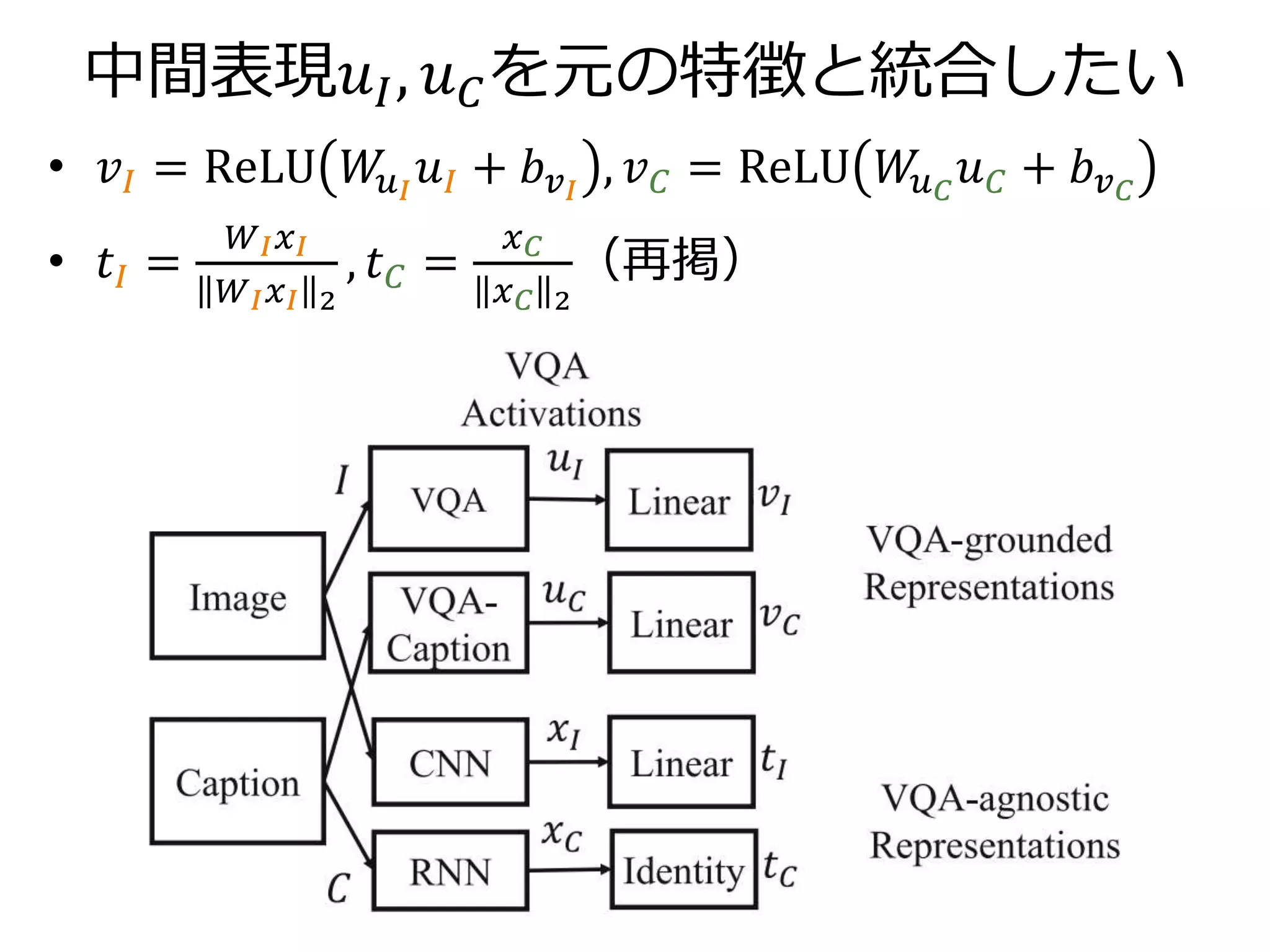
𝑆𝑡 𝐼, 𝐶 = 𝑡𝐼, 𝑡 𝐶
𝑡𝐼 =
𝑊𝐼 𝑥𝐼
𝑊𝐼 𝑥𝐼 2
, 𝑡 𝐶 =
𝑥 𝐶
𝑥 𝐶 2
𝑥𝐼:画像特徴量
19層VGGNetの出力 4096次元
𝑥 𝐶:キャプション特徴量
隠れ層1024次元のGRUによるRNNの出力 1024次元
𝑊𝐼:学習する線形変換
画像特徴からキャプション特徴への変換に相当](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-21-2048.jpg)

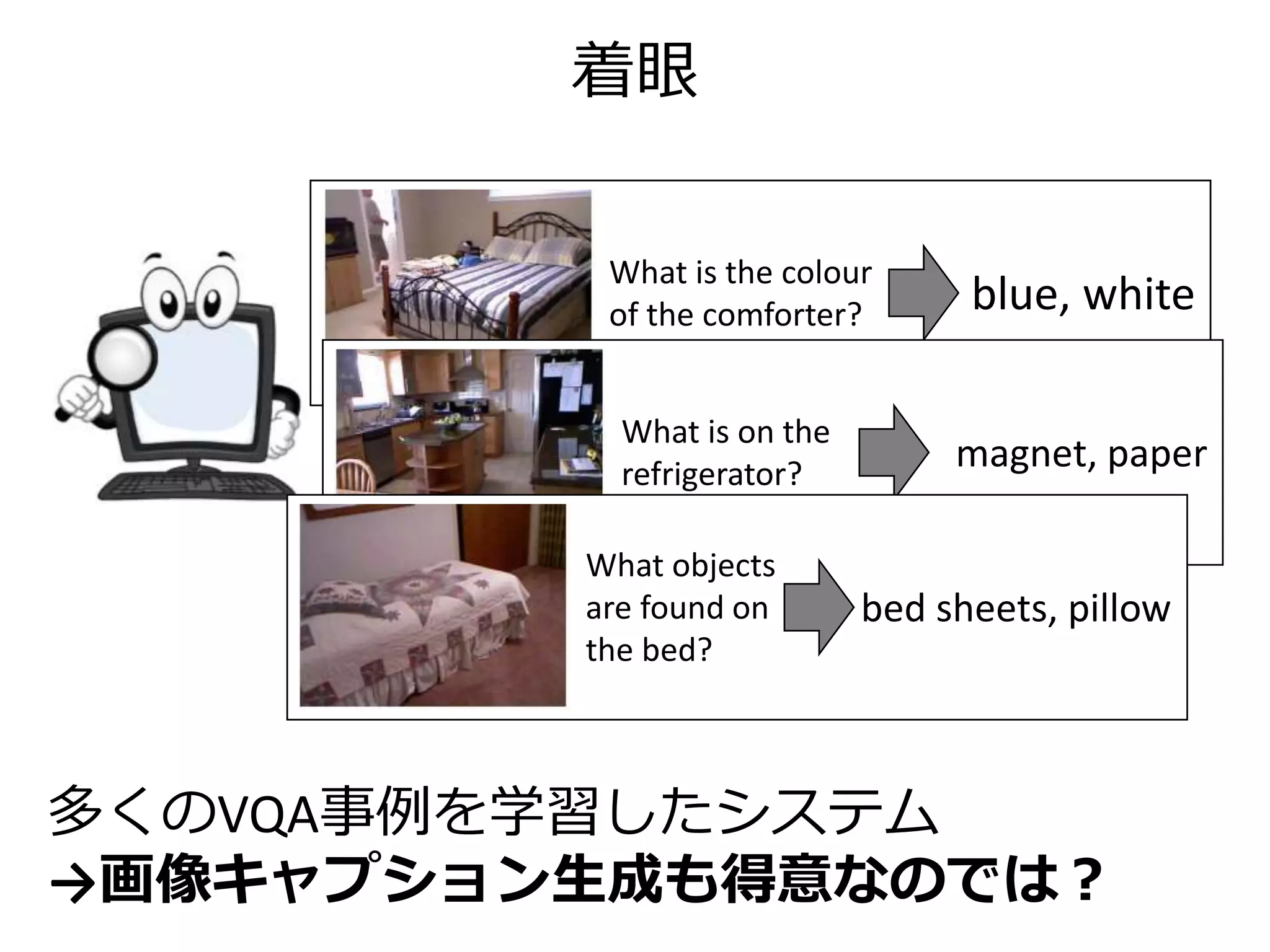
![Visual Question Answering (VQA)
画像に関する質問に答えるQAシステム
• Visual Turing Challenge [MalinowskiL+Fritz, 2014]
• VQA Challenge
CVPR 2016 併設のコンペティション
(弊研究室:Abstract Image 部門で世界1位)
[Malinowski+,
ICCV 2015]](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-23-2048.jpg)

![今日紹介する論文では…
VQA 原著論文のモデル [Antol+, ICCV 2015]を採用
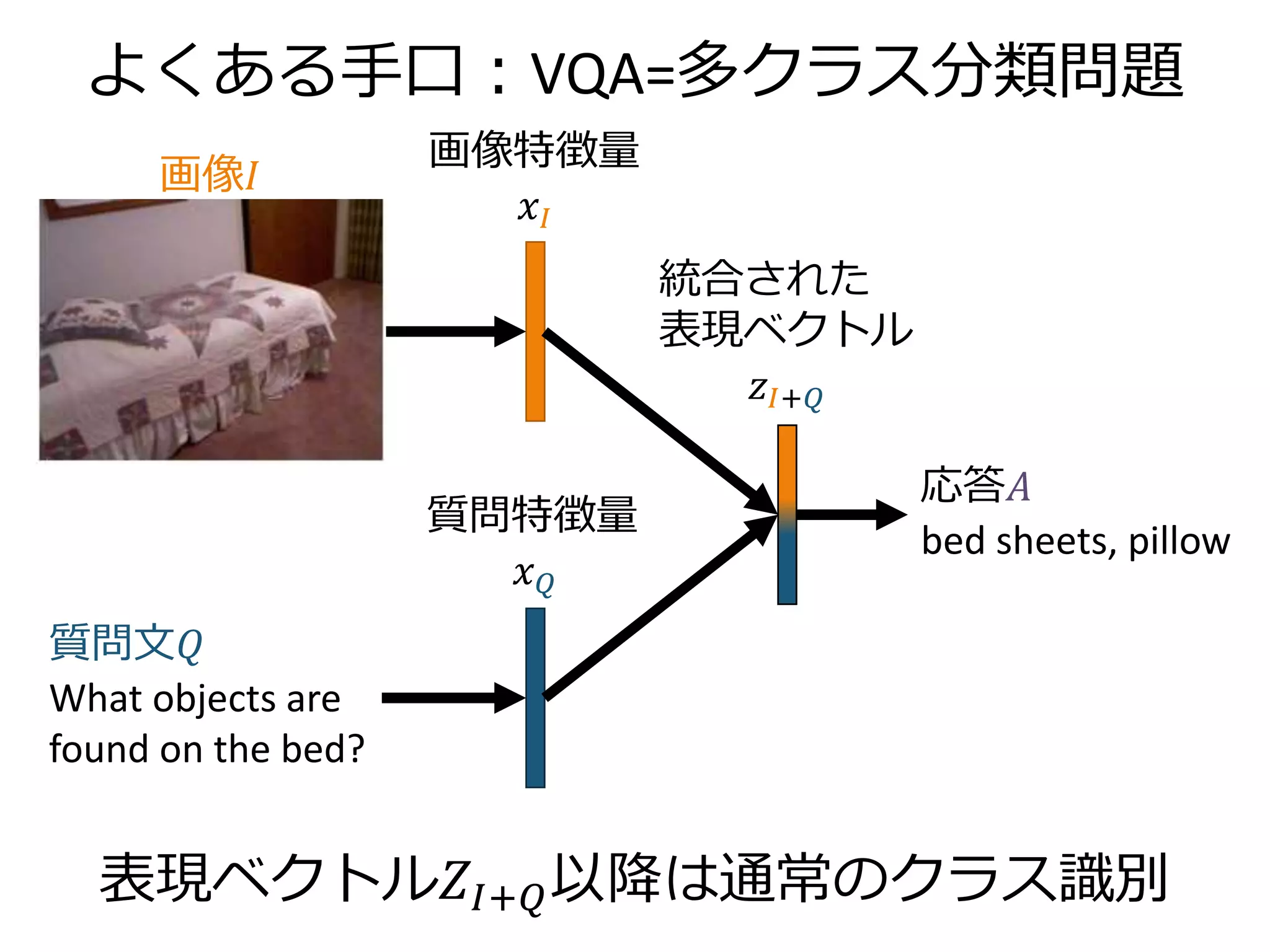
VQA モデル
𝑧𝐼 = tanh(𝑊𝐼 𝑥𝐼 + 𝑏𝐼) , 𝑧 𝑄 = tanh(𝑊𝑄 𝑥 𝑄 + 𝑏 𝑄)
𝑧𝐼+𝑄 = 𝑧𝐼⨀𝑧 𝑄 (⨀は要素積)
𝑠 𝐴 = 𝑊𝑆 𝑧𝐼+𝑄 + 𝑏𝑆
𝑥𝐼:19層VGGNetの出力 4096次元
𝑥 𝑄:隠れ層512次元のLSTMによるRNN2層の出力 2048次元
𝑧∗:表現ベクトル 1024次元
𝑊∗, 𝑏∗ :学習する線形変換とバイアス](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-25-2048.jpg)
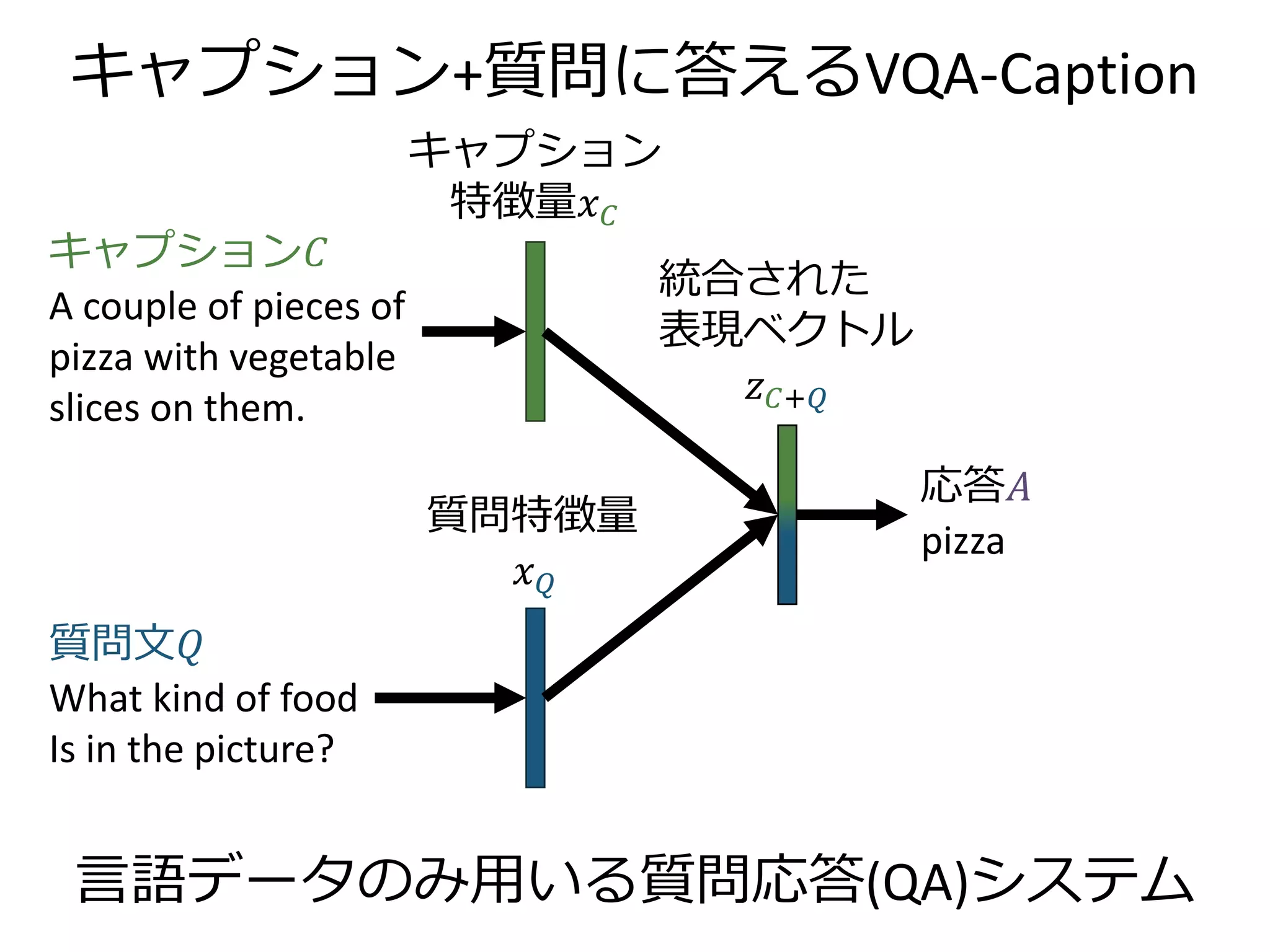
![今日紹介する論文では…
VQA 原著論文のモデル [Antol+, ICCV 2015]を採用
VQA-Caption モデル
𝑧 𝐶 = tanh(𝑊𝐶 𝑥 𝐶 + 𝑏 𝐶) , 𝑧 𝑄 = tanh(𝑊𝑄 𝑥 𝑄 + 𝑏 𝑄)
𝑧 𝐶+𝑄 = 𝑧 𝐶⨀𝑧 𝑄 (⨀は要素積)
𝑠 𝐴 = 𝑊𝑆 𝑧 𝐶+𝑄 + 𝑏𝑆
𝑥 𝐶:最頻1000単語によるbag-of-wordsモデル 1000次元
𝑥 𝑄:隠れ層512次元のLSTMによるRNN2層の出力 2048次元
𝑧∗:表現ベクトル 1024次元
𝑊∗, 𝑏∗ :学習する線形変換とバイアス](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-27-2048.jpg)


![関連研究:中間表現
• Semantic Mid-Level Visual Representations
Attributes, Parts, Poselets, Objects, Actions, Contextual
information
• 中間表現を用いるメリット
– 既存タスクの高精度化
– Zero-shot learning (↓は[Elhoseiny+, ICCV 2013])](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-32-2048.jpg)



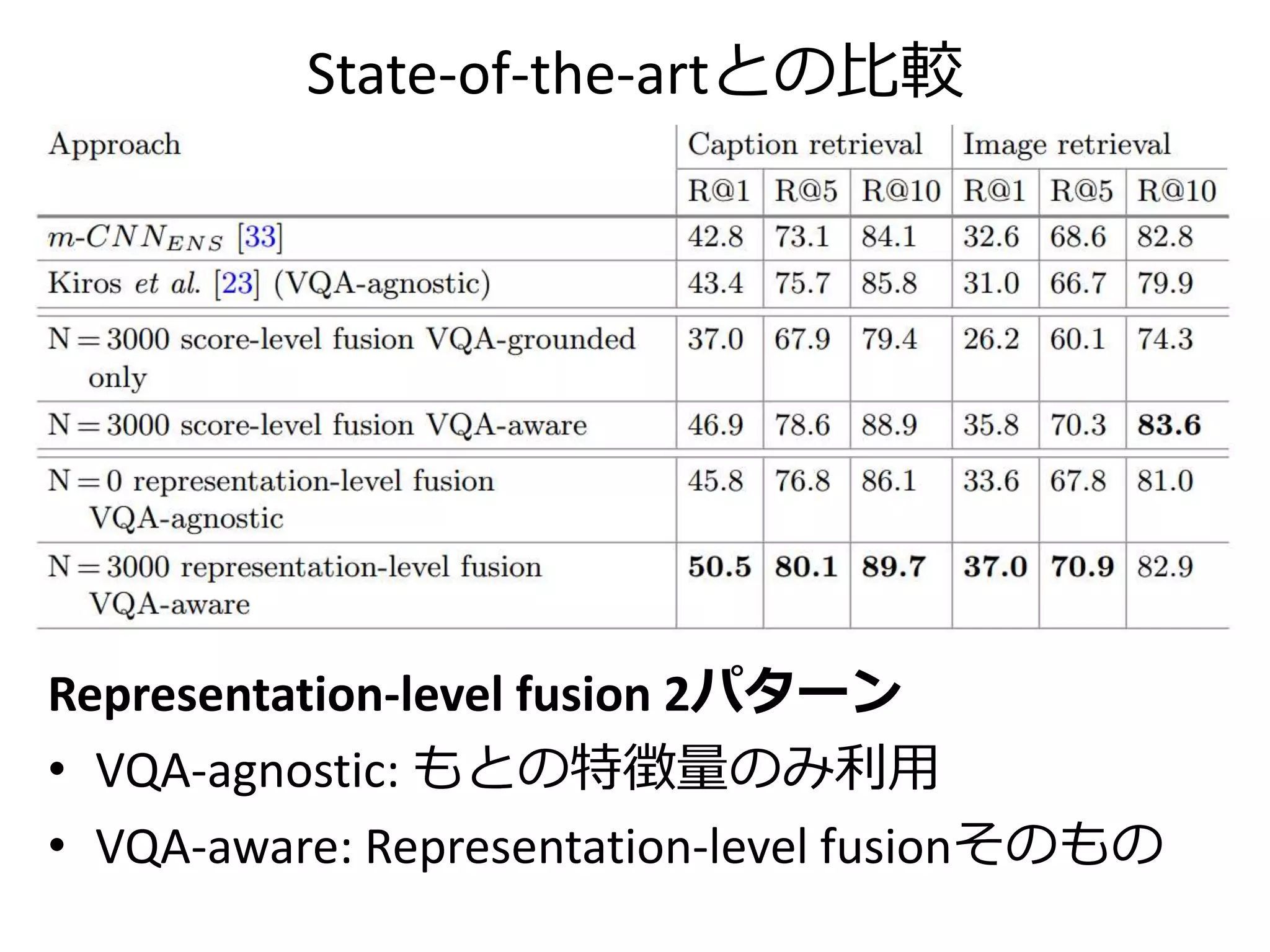
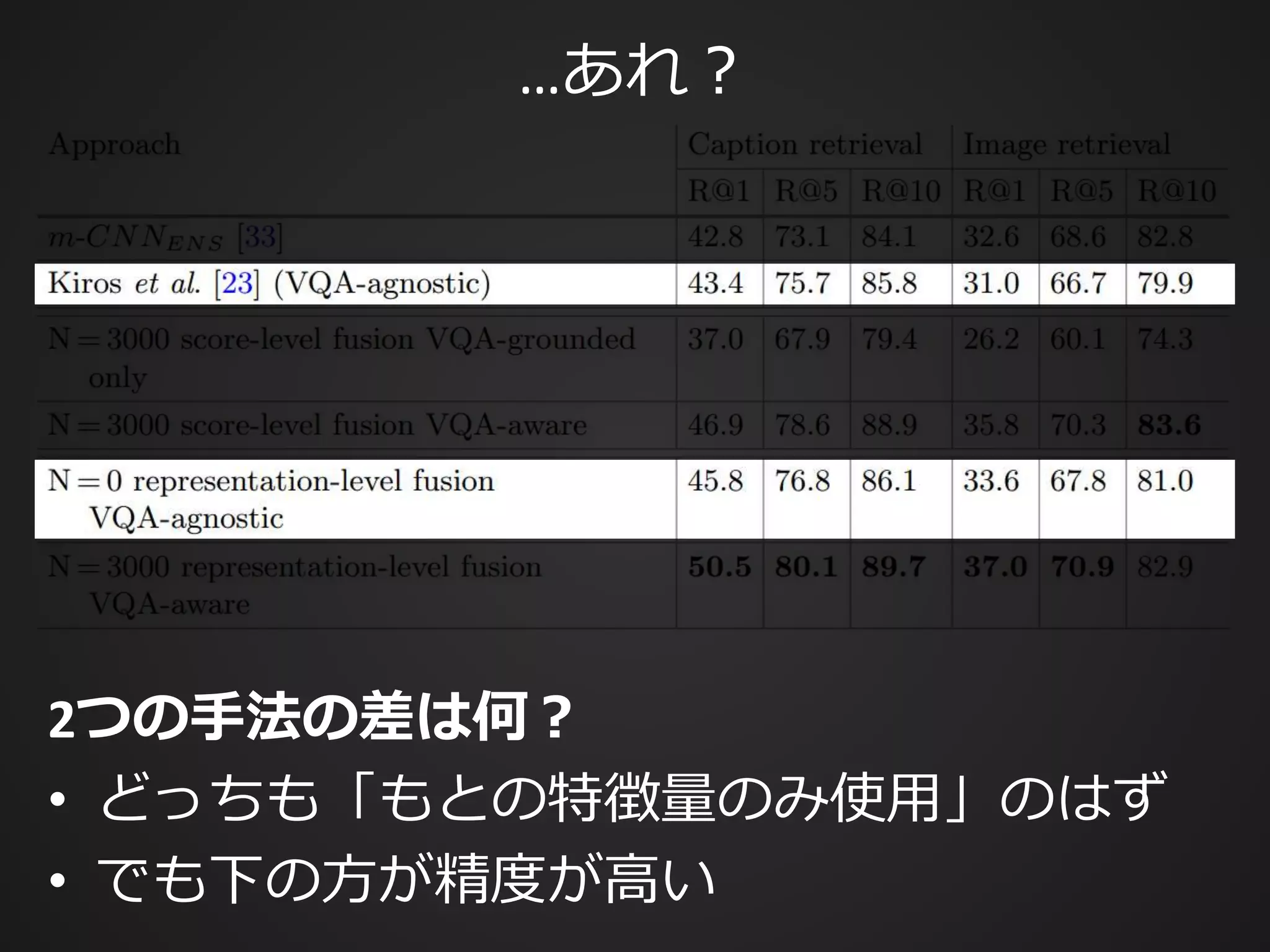
![State-of-the-art の成績一覧
本論文がBaselineとして採用している
Multimodal Neural Language Models [Kiros+, TACL 2015]](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-42-2048.jpg)


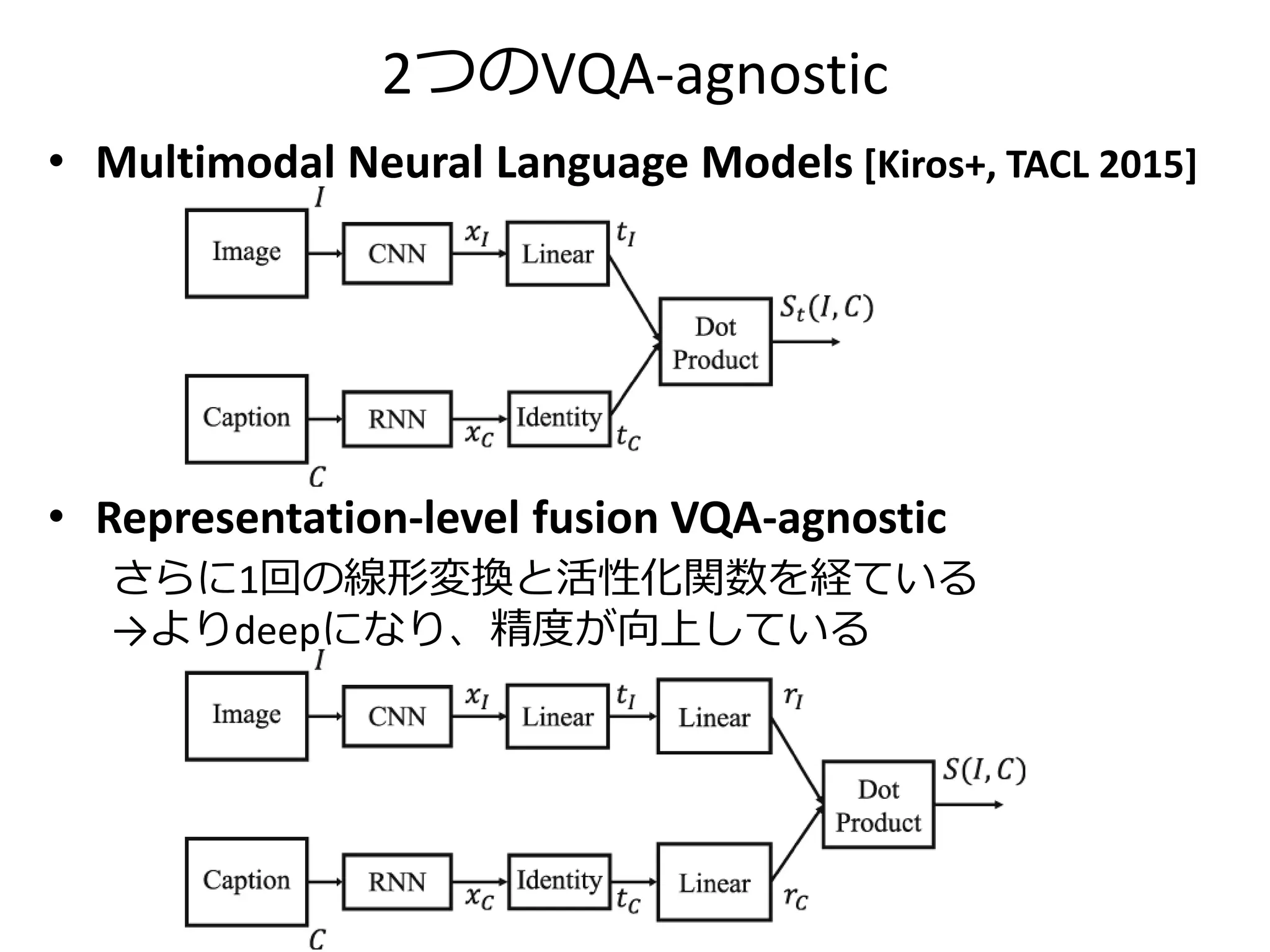
![2つのVQA-agnostic
• Multimodal Neural Language Models [Kiros+, TACL 2015]
• Representation-level fusion VQA-agnostic
さらに1回の線形変換と活性化関数を経ている
→よりdeepになり、精度が向上している](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-46-2048.jpg)


![まとめと所感
• VQAを中間表現(後述)に用いることを提案
• Image-Caption Ranking で用いる特徴量に追加
– 検索精度が向上した
– ほかのタスクにも有用である可能性はある
• 「我々の知る限り最高精度」by著者
– 画像検索は[Wang+, CVPR 2016]のほうが上
• 危惧は解消できたか
– 専門分野もってなさそうだし
– 論文に数式出てこないし](https://image.slidesharecdn.com/20161203kantocveccvforupload-161203040549/75/Leveraging-Visual-Question-Answering-for-Image-Caption-Ranking-CV-ECCV-2016-52-2048.jpg)



























![[DL輪読会]Semi supervised qa with generative domain-adaptive nets](https://cdn.slidesharecdn.com/ss_thumbnails/semi-supervisedqawithgenerativedomain-adaptivenets-170317041122-thumbnail.jpg?width=640&height=640&fit=bounds)














































