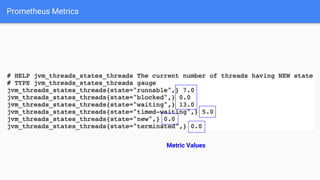
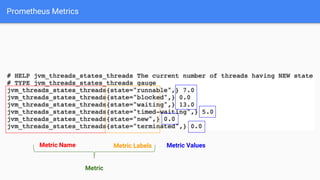
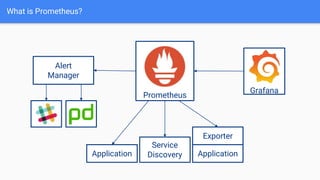
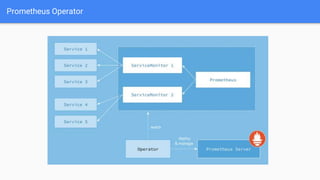
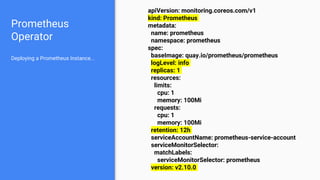
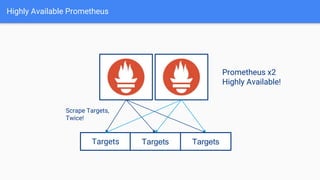
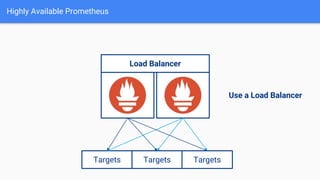
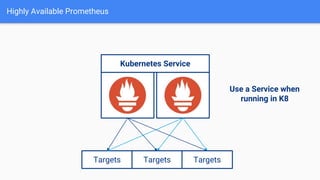
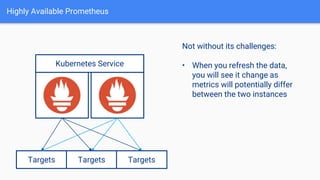
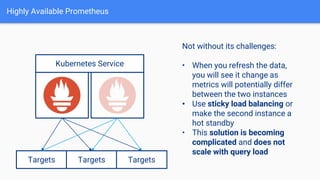
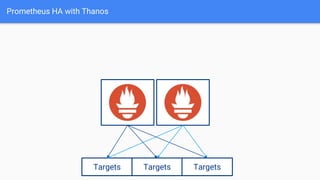
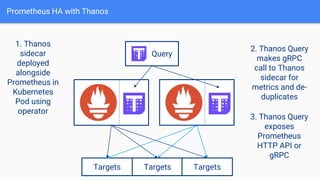
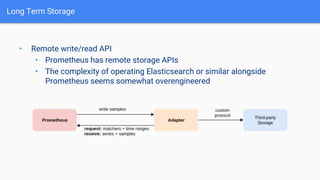
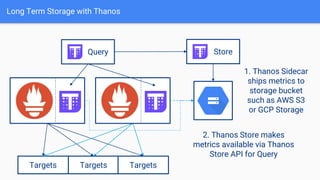
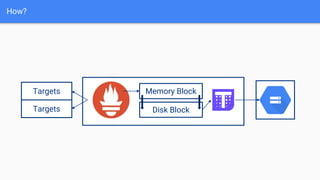
The document discusses the implementation of Prometheus for monitoring Kubernetes, highlighting its high availability (HA) capabilities when used alongside Thanos, which provides unlimited storage and deduplication of metrics. It outlines the challenges and complexities of maintaining Prometheus instances in a Kubernetes environment, as well as potential solutions using Kubernetes services and load balancers. The conclusion emphasizes the benefits of using the Prometheus operator and Thanos for improved resilience and scalability in monitoring applications.