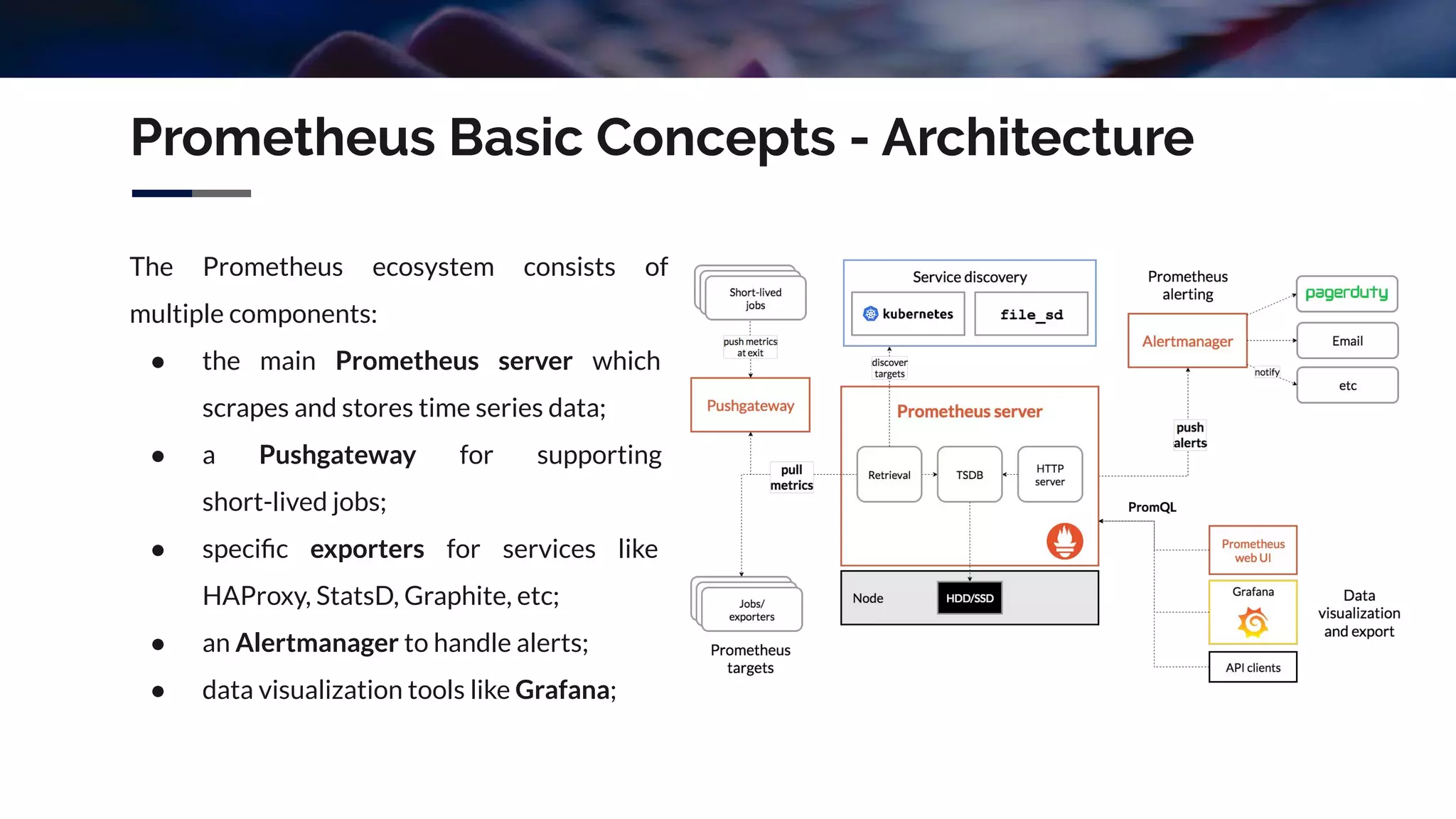
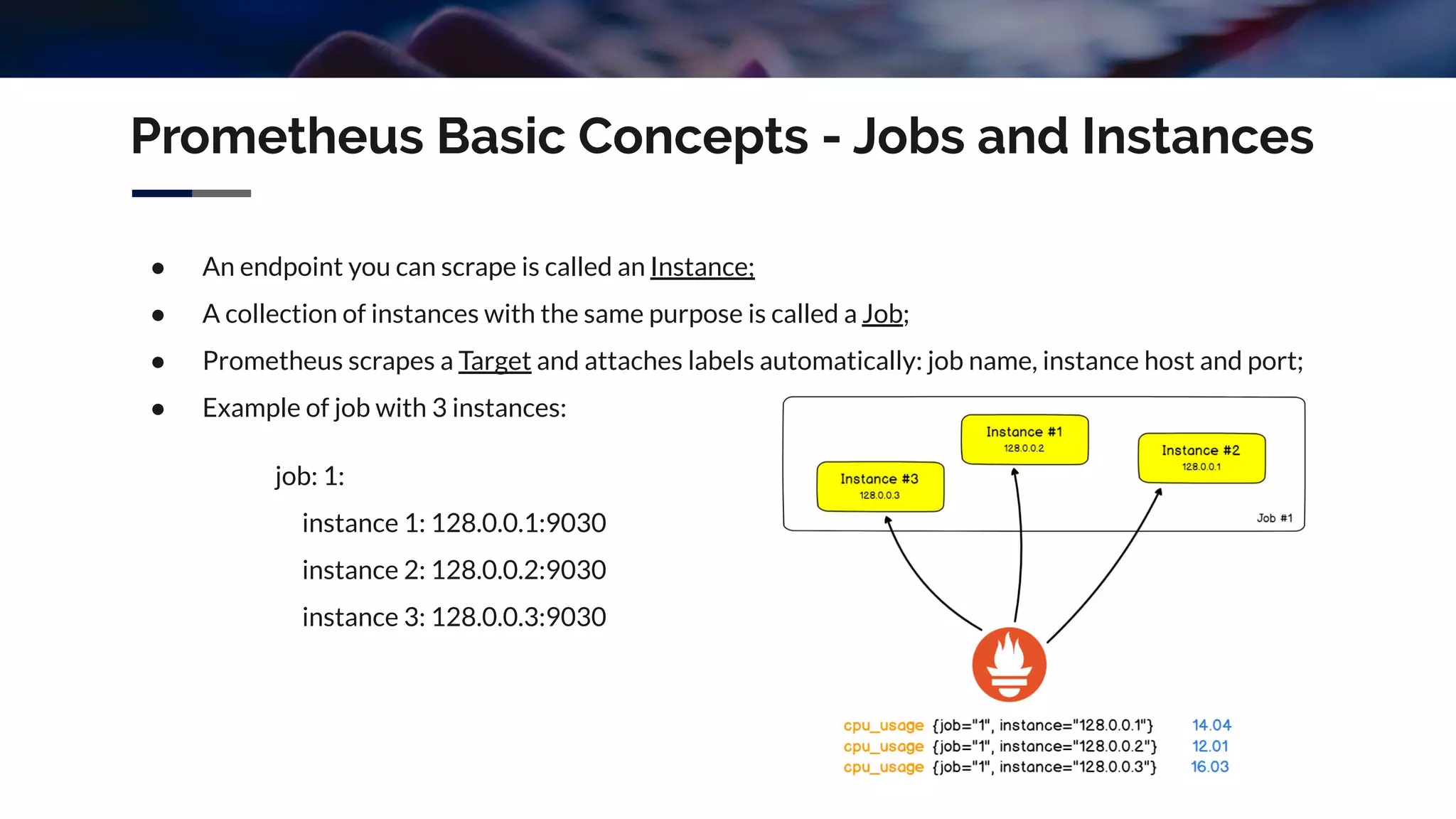
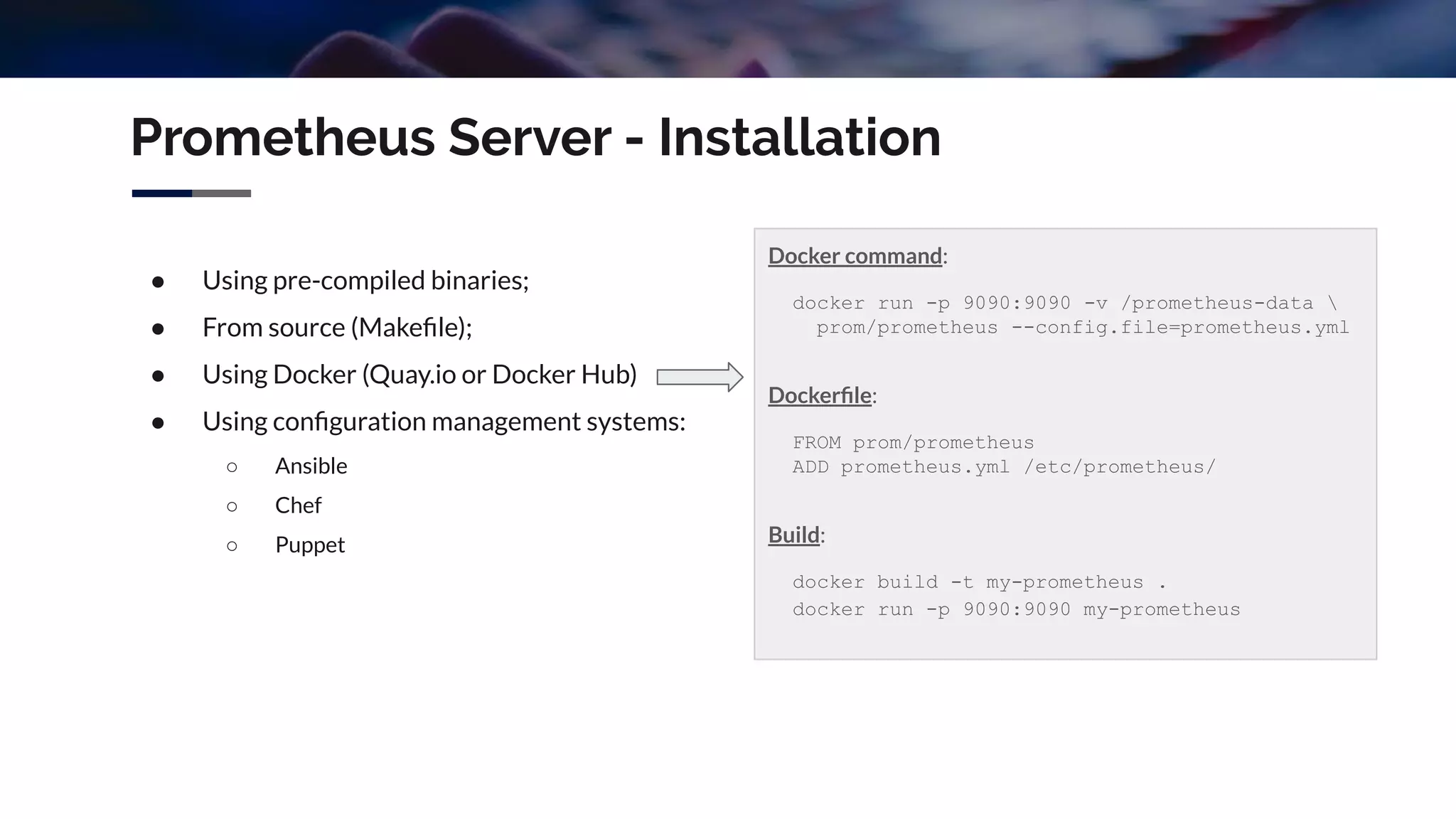
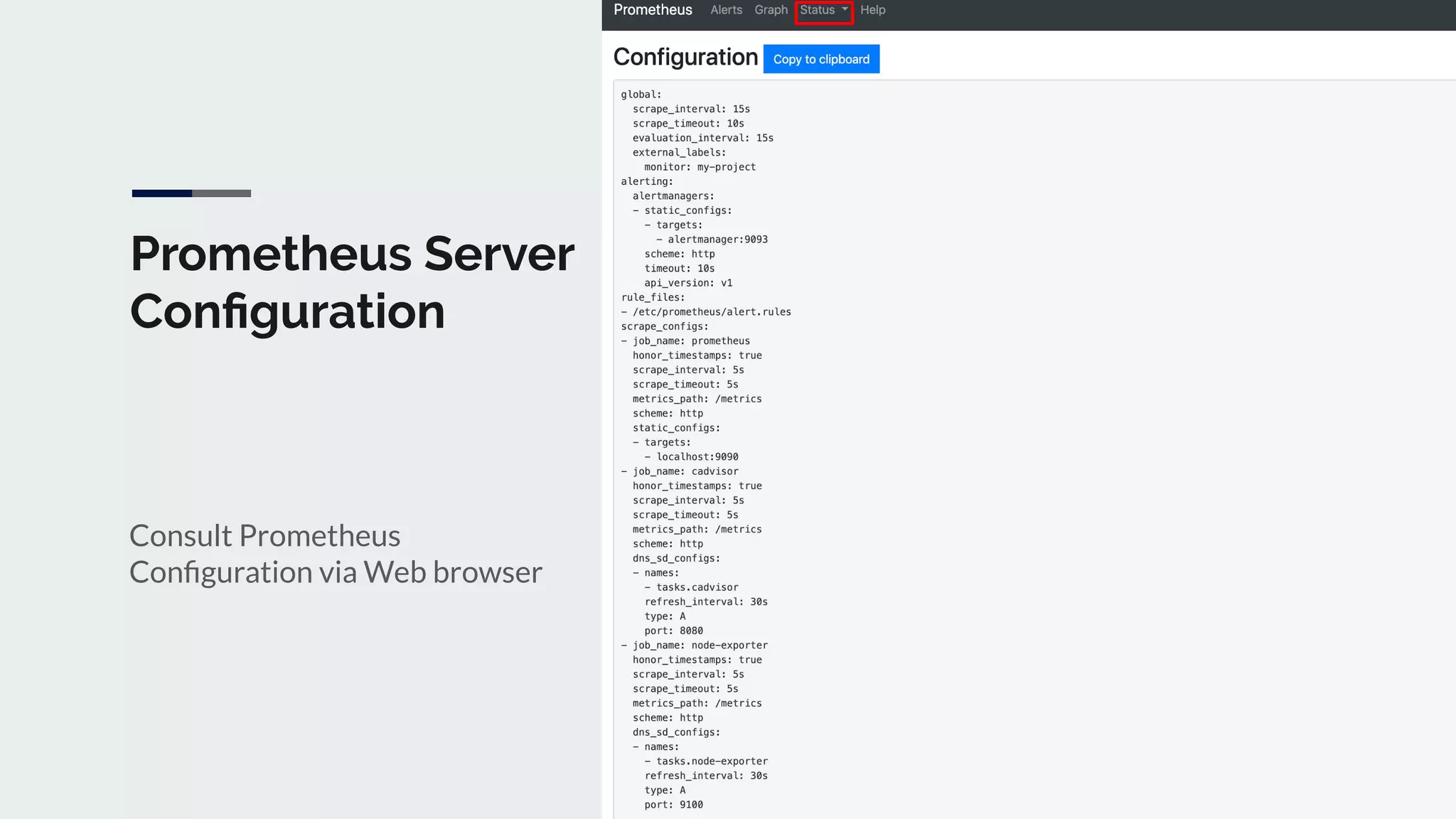
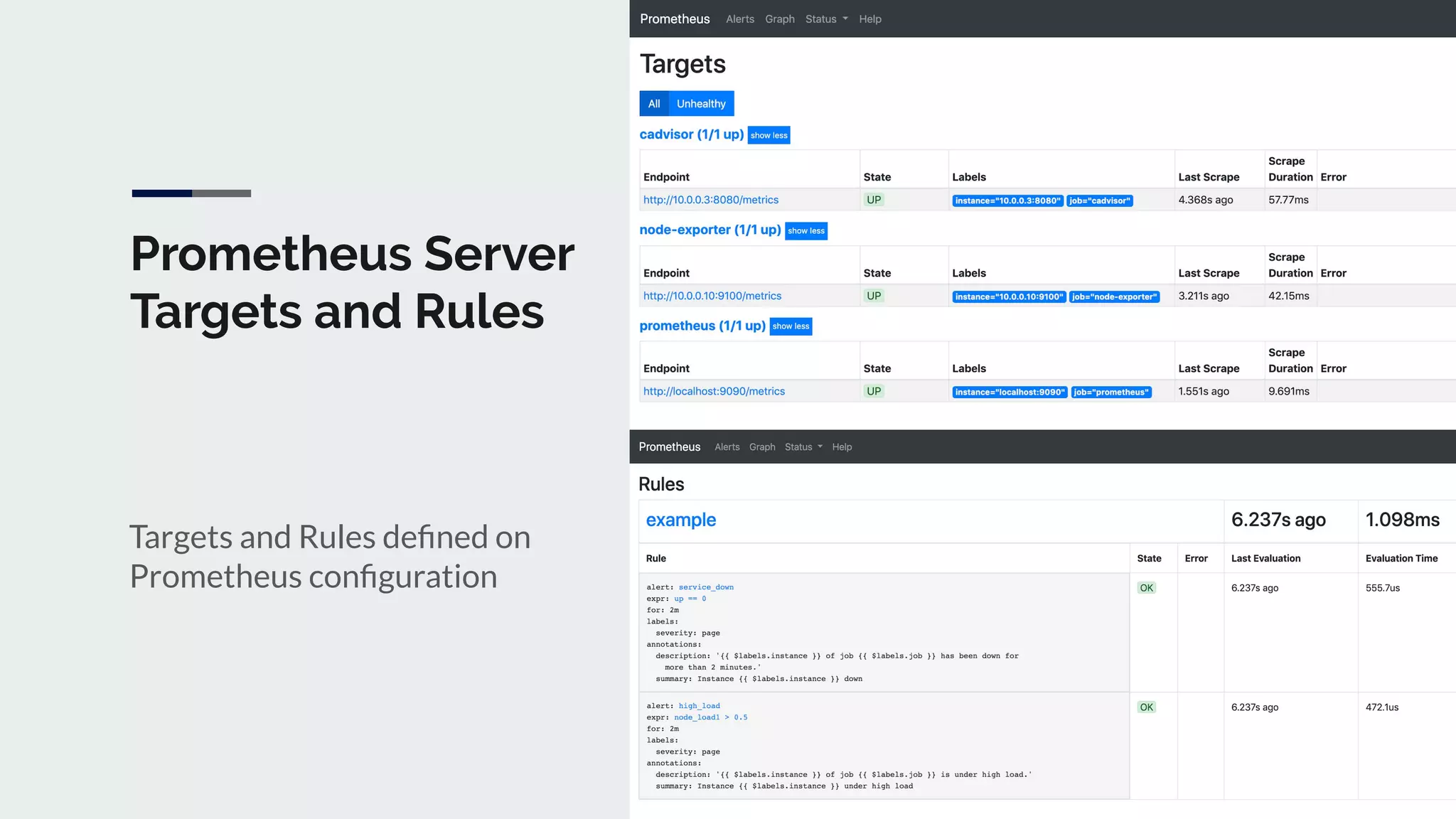
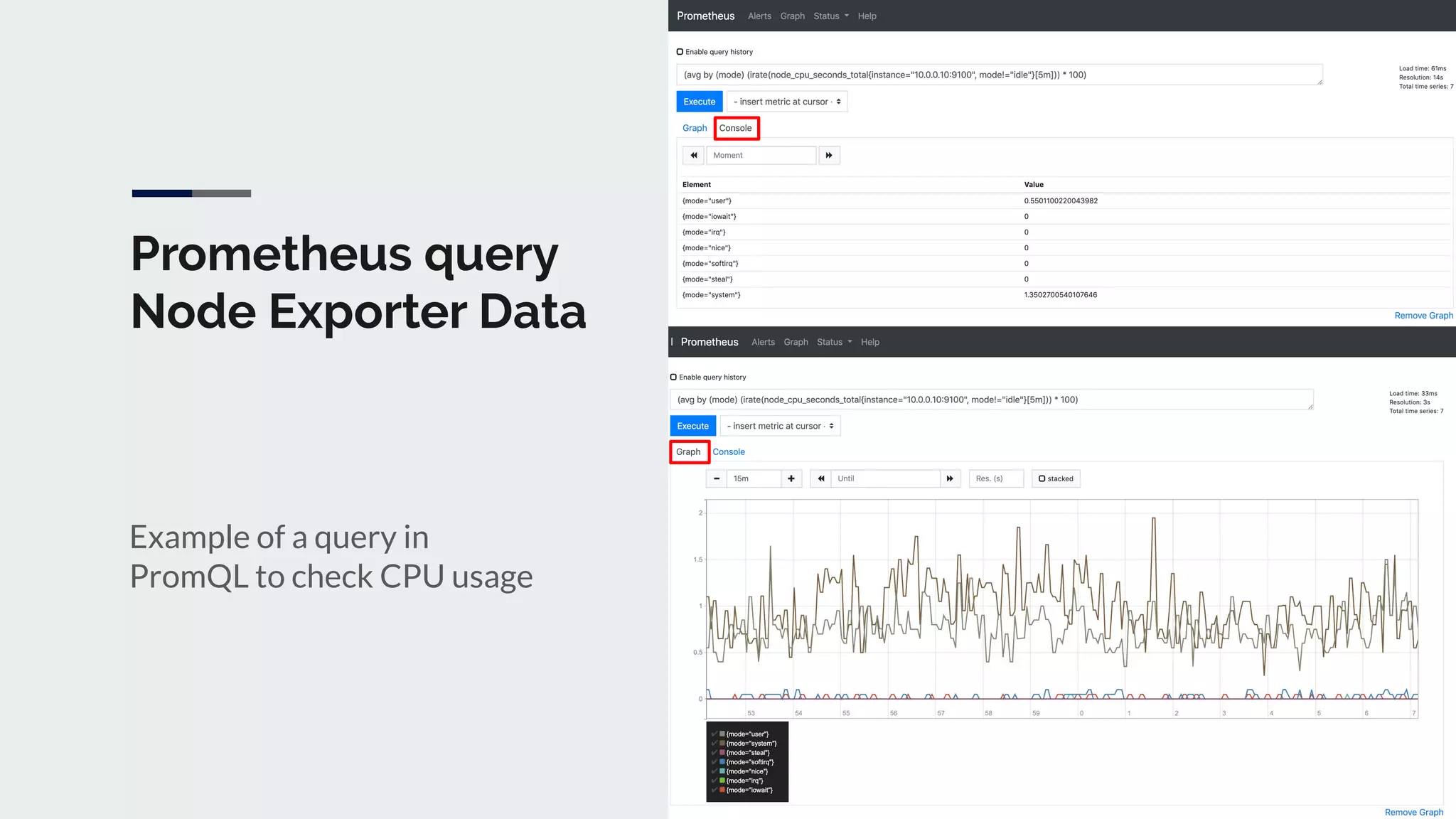
The document discusses integrating Icinga and Prometheus for system monitoring. It describes the key features and concepts of Prometheus including its data model, metric types, jobs and instances. The presentation covers configuring Prometheus servers, scraping metrics using exporters and the Pushgateway, and implementing custom metrics using the Node Exporter. Combining Icinga and Prometheus allows leveraging Icinga for configuration, alerting and notifications while using Prometheus for collection and querying of metrics.












![Prometheus Basic Concepts - PromQL
Expression language data types:
● Instant vector - a set of time series containing a single sample for each time series;
○ Example: http_requests_total{environment=~"staging|development",method!="GET"}
● Range vector - a set of time series containing a range of data points for each time series;
○ Example: http_requests_total{job="prometheus"}[5m]
● Scalar - a simple numeric floating point value;
○ Example: -2.43
● String - a simple string value;
○ Example: 'these are unescaped: n t'](https://image.slidesharecdn.com/agentlessmonitoringwithicingaandprometheus-191105104757/75/DevOps-Braga-15-Agentless-monitoring-with-icinga-and-prometheus-15-2048.jpg)








![How to integrate Icinga with Prometheus?
● Icinga can be integrated with Prometheus via Nagitheus (Claranet);
● Nagitheus is a Nagios plugin for querying Prometheus, written in Go;
● Nagitheus process vector or scalar results and return an exit code, according with warning/critical
values and comparison method (ge, gt, le, lt);
● Allows basic authentication on Prometheus with username and password (-u and -pw options);
● Example:
/usr/lib64/nagios/plugins/nagitheus -H http://localhost:9090 -i 10.0.0.10 -p 9100 -l 'Check CPU' -d yes -q
'(avg by (mode) (irate(node_cpu_seconds_total{instance="", mode!="idle"}[5m])) * 100)' -m ge -w 70 -c 80](https://image.slidesharecdn.com/agentlessmonitoringwithicingaandprometheus-191105104757/75/DevOps-Braga-15-Agentless-monitoring-with-icinga-and-prometheus-28-2048.jpg)





















![[EN]DSS23_tspann_Integrating LLM with Streaming Data Pipelines](https://cdn.slidesharecdn.com/ss_thumbnails/endss23tspannintegratingllmwithstreamingdatapipelines-231115161007-49510320-thumbnail.jpg?width=640&height=640&fit=bounds)








































![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)





