





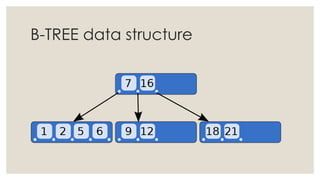
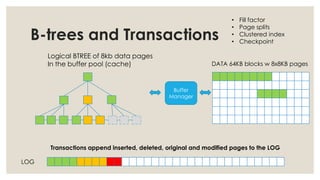
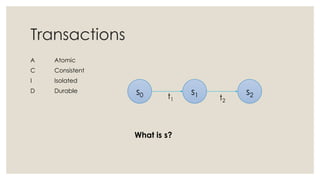


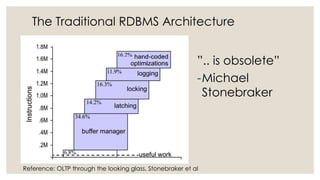
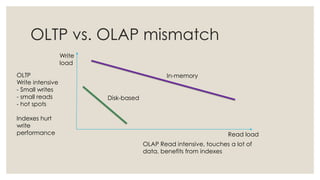

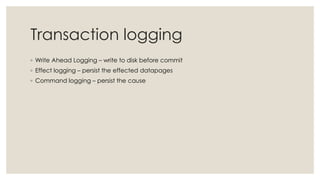




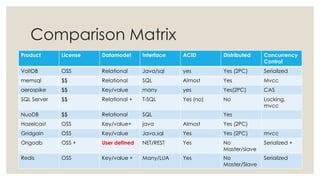








The document discusses in-memory computing and the evolution of database technology, highlighting the limitations of traditional RDBMS in modern applications and the advantages of in-memory databases. It reviews various in-memory products, including origodb and redis, emphasizing their use cases, performance benefits, and architectural differences. The presentation advocates for polyglot persistence and selecting the appropriate data model based on application needs and available resources.



























![[DockerCon 2019] Hardening Docker daemon with Rootless mode](https://cdn.slidesharecdn.com/ss_thumbnails/hardeningdockerdaemonwithrootlessmode-190501210234-thumbnail.jpg?width=640&height=640&fit=bounds)







































