Downloaded 176 times




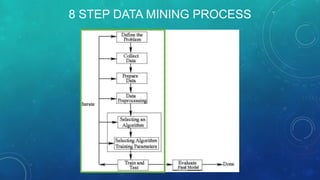











The document describes the 8 step data mining process: 1) Defining the problem, 2) Collecting data, 3) Preparing data, 4) Pre-processing, 5) Selecting an algorithm and parameters, 6) Training and testing, 7) Iterating models, 8) Evaluating the final model. It discusses issues like defining classification vs estimation problems, selecting appropriate inputs and outputs, and determining when sufficient data has been collected for modeling.



































































