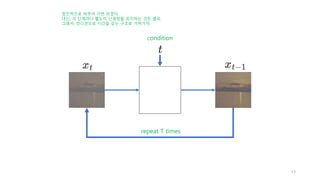
repeat T times
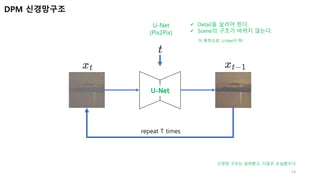
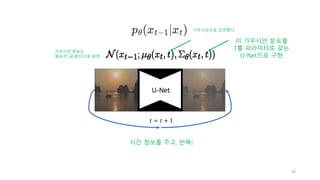
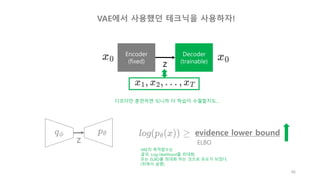
U-Net
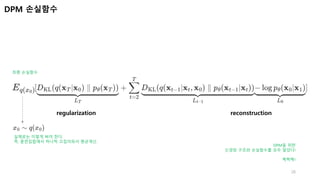
DPM신경망구조
14
U-Net
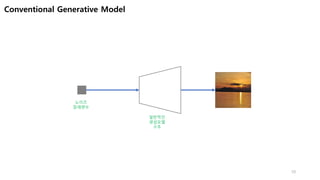
(Pix2Pix)
✓ Detail을 살려야 한다.
✓ Scene의 구조가 바뀌지 않는다.
이 목적으로, U-Net이 딱!
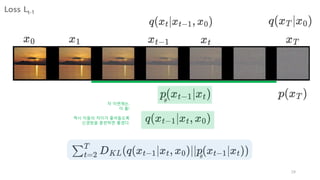
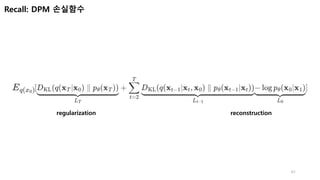
신경망 구조는 살펴봤고, 다음은 손실함수다.
15.
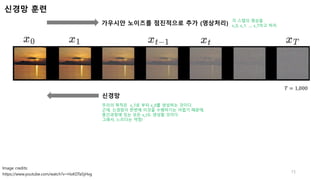
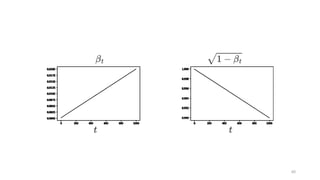
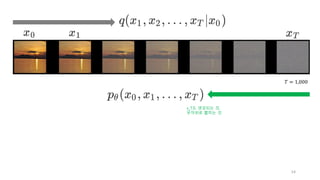
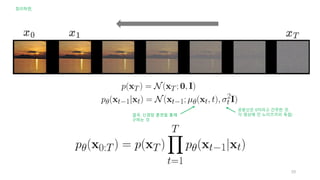
𝑇 = 1,000
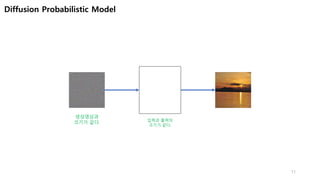
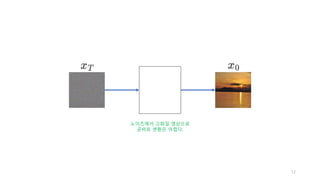
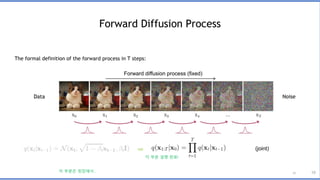
가우시안노이즈를 점진적으로 추가 (영상처리)
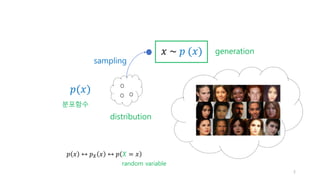
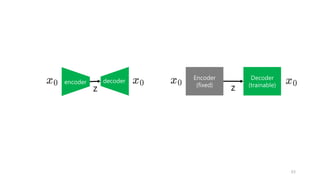
신경망
신경망 훈련
15
https://www.youtube.com/watch?v=HoKDTa5jHvg
Image credits:
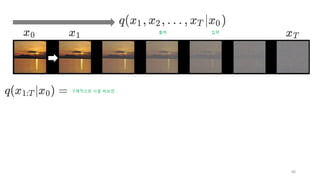
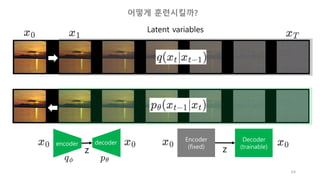
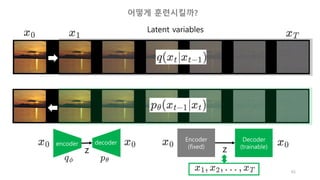
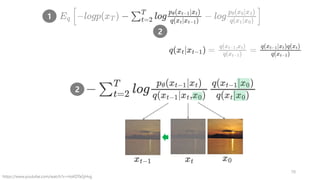
각 스텝의 영상을
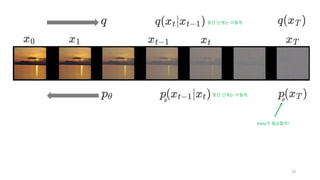
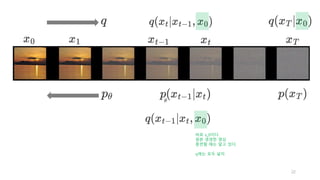
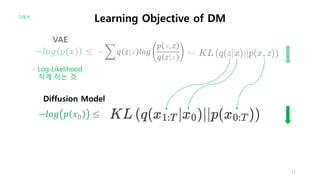
x_0, x_1, …, x_T라고 하자.
우리의 목적은 x_T로 부터 x_0를 생성하는 것이다.
근데, 신경망이 한번에 이것을 수행하기는 어렵기 때문에,
중간과정에 있는 모든 x_t도 생성할 것이다.
그래서, 느리다는 약점!
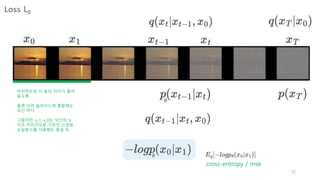
16.
16
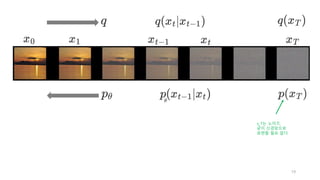
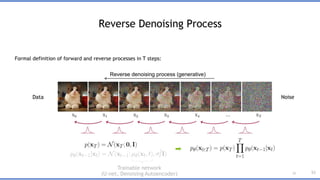
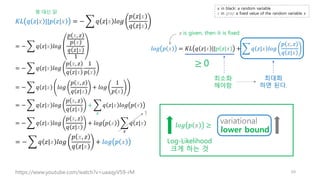
분포함수로 표현
이 방향은q로 나타내자.
이 방향은 p로 나타내자.
신경망을 사용할 예정이므로,
파라미터 theta 함께 표시
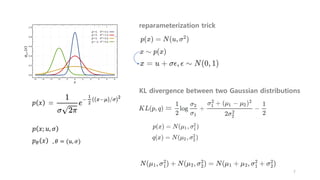
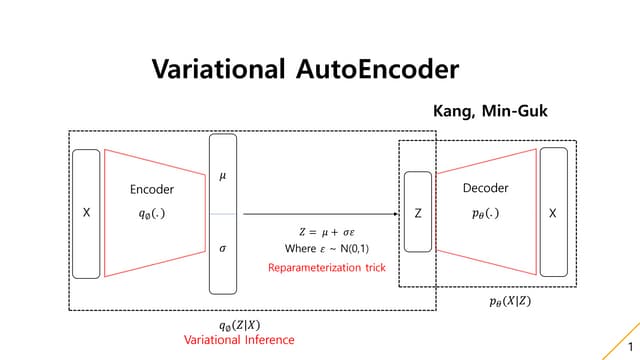
Variational Inference
𝑝 𝑧|𝑥
𝑞𝑧|𝑥
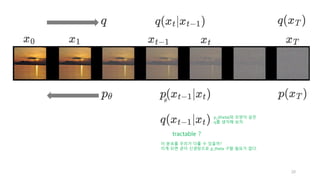
구하기 어렵다.
꿩 대신 닭
변이
우리가 알고 있는 쉬운 분포; 정규분포로 대치하자.
𝑝 𝑧|𝑥 ≈ 𝑞 𝑧|𝑥
조건:
KL 최소화
min KL 𝑞 𝑧|𝑥 ||𝑝 𝑧|𝑥
67
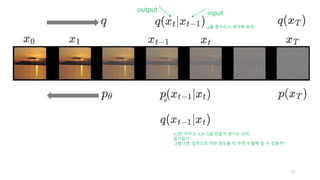
Posterior 구하기
대체(변이) 사후확률 구함
𝑞 𝑧|𝑥
Reverse KL을 선호
VI : biased, low variance
MC: unbiased, high variance













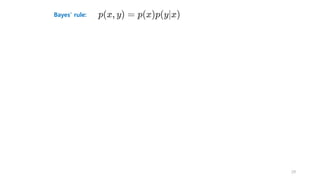
































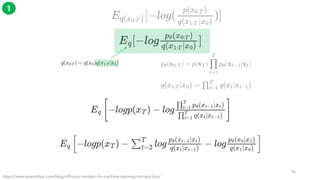







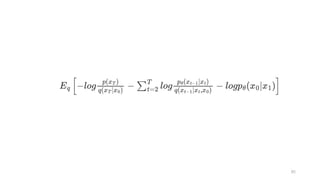




















![References
• [Paper] Jascha Sohl-Dickstein et al., "Deep Unsupervised Learning using Nonequilibrium
Thermodynamics", ICML, 2015.
• [Paper] Jonathan Ho et al., "Denoising diffusion probabilistic models", arXiv:2006.11239,
2020.
• [Tutorial] Karsten Kreis et al., "Denoising Diffusion-based Generative Modeling:
Foundations and Applications", June 19, CVPR 2022.
• [Tutorial] (한글) Injung Kim, "Diffusion Probabilistic Models", July 1, KCC 2022.
• [Tutorial] (한글) Jaepil Ko, "Tutorial on VAE", slideshare,
https://www.slideshare.net/jaepilko10/variational-autoencoder-vae-255270887
• [Blog] What are Diffusion Models, https://lilianweng.github.io/posts/2021-07-11-diffusion-
models/
• [Blog] Introduction to Diffusion Models for Machine Learning,
https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction/
• [Blog] (한글) https://developers-shack.tistory.com/8
• [YouTube] https://www.youtube.com/watch?v=HoKDTa5jHvg
106](https://image.slidesharecdn.com/dpm-ko-comments-230114042405-69f60c9b/85/CVPR-2022-Tutorial-Diffusion-Probabilistic-Model-106-320.jpg)

![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)



![[PR12] understanding deep learning requires rethinking generalization](https://cdn.slidesharecdn.com/ss_thumbnails/pr12understandingdeeplearningrequiresrethinkinggeneralization-180121135850-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)





![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)














![[신경망기초]오류역전파알고리즘구현](https://cdn.slidesharecdn.com/ss_thumbnails/nn-190319093725-thumbnail.jpg?width=640&height=640&fit=bounds)




![[확률통계]04모수추정](https://cdn.slidesharecdn.com/ss_thumbnails/statistics4-190131081748-thumbnail.jpg?width=640&height=640&fit=bounds)













![[신경망기초] 신경망학습](https://cdn.slidesharecdn.com/ss_thumbnails/3-180604140208-thumbnail.jpg?width=640&height=640&fit=bounds)