Download as PDF, PPTX













![20BIO-REFRESHER
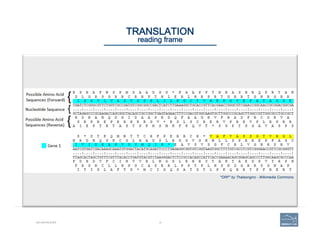
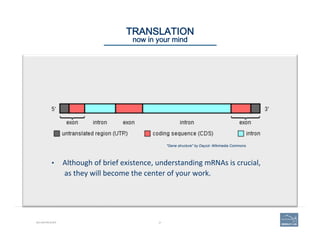
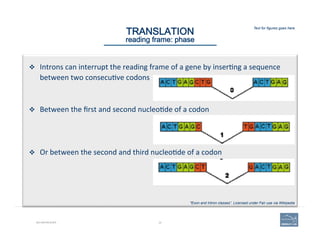
TRANSLATION
reading frame: splice sites
v The
spliceosome
catalyzes
the
removal
of
introns
and
the
liga(on
of
flanking
exons.
• introns:
spaces
inside
the
gene,
not
part
of
the
coding
sequence
• exons:
expression
units
(of
the
coding
sequence)
v Splicing
“signals”
(from
the
point
of
view
of
an
intron):
• There
is
a
5’
end
splice
“signal”
(site):
usually
GT
(less
common:
GC)
• And
a
3’
end
splice
site:
usually
AG
• …]5’-‐GT/AG-‐3’[…
v It
is
possible
to
produce
more
than
one
protein
(polypep(de)
sequence
from
the
same
genic
region,
by
alterna(vely
bringing
exons
together=
alterna=ve
splicing.
For
example,
the
gene
Dscam
(Drosophila)
has
38,000
alterna(vely
spliced
mRNAs
=
isoforms](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-20-320.jpg)







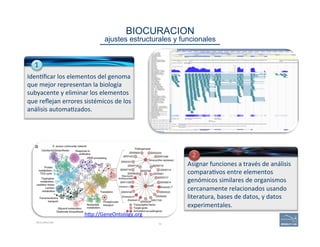








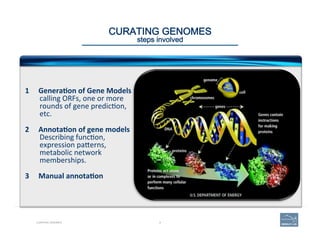
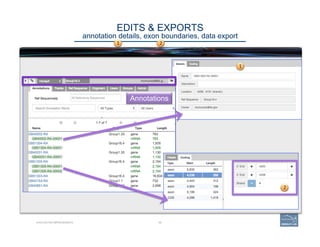
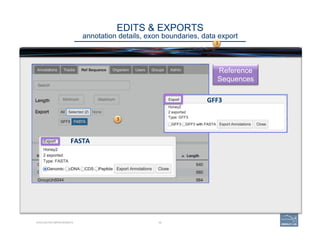
![46CURATING GENOMES
WHAT ANNOTATORS SHOULD LOOK FOR
annotators: that’s you!
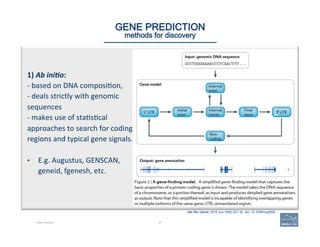
v Annota=ng
a
simple
case:
WHEN
“The
official
predic(on
is
correct,
or
nearly
correct,
assuming
that
no
aligned
data
extends
beyond
the
gene
model
and
if
so,
it
is
not
likely
to
be
coding
sequence,
and/or
the
gene
predic(on
matches
what
you
know
about
the
gene”:
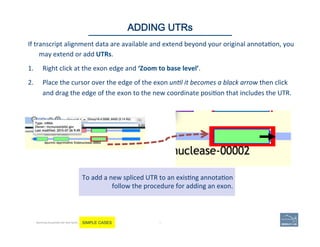
a. Can
you
add
UTRs?
b. Check
exon
structures.
c. Check
splice
sites:
…]5’-‐GT/AG-‐3’[…
d. Check
‘start’
and
‘stop’
sites.
e. Check
the
predicted
protein
product(s).
f. If
the
protein
product
s(ll
does
not
look
correct,
go
on
to
“Annota(ng
more
complex
cases”.](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-46-320.jpg)









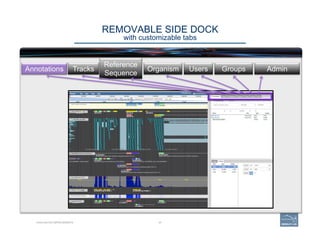
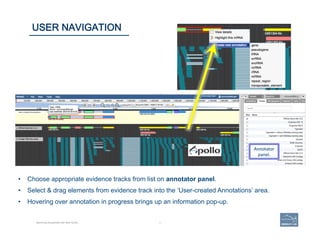




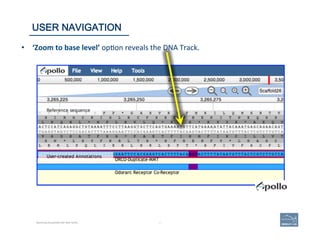
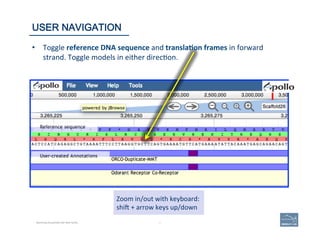




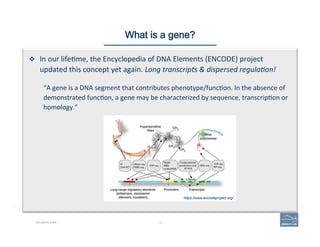
![1. Zoom
in
to
clearly
resolve
each
exon
as
a
dis(nct
rectangle.
2. Two
exons
from
different
tracks
sharing
the
same
start
and/or
end
coordinates
will
display
a
red
bar
to
indicate
matching
edges.
3. Selec(ng
the
whole
annota(on
or
one
exon
at
a
(me,
use
this
‘edge-‐
matching’
func(on
and
scroll
along
the
length
of
the
annota(on,
verifying
exon
boundaries
against
available
data.
Use
square
[
]
brackets
to
scroll
from
exon
to
exon.
4. Check
if
cDNA
/
RNAseq
reads
lack
one
or
more
of
the
annotated
exons
or
include
addi(onal
exons.
73 | 73
CHECK EXON INTEGRITY
Becoming Acquainted with Web Apollo. SIMPLE CASES](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-73-320.jpg)

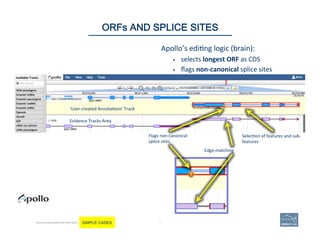
![76 |
Exon/intron
junc(on
possible
error
Original
model
Curated
model
Non-‐canonical
splices
are
indicated
by
an
orange
circle
with
a
white
exclama(on
point
inside,
placed
over
the
edge
of
the
offending
exon.
Canonical
splice
sites:
3’-‐…exon]GA
/
TG[exon…-‐5’
5’-‐…exon]GT
/
AG[exon…-‐3’
reverse
strand,
not
reverse-‐complemented:
forward
strand
76
SPLICE SITES
Becoming Acquainted with Web Apollo. SIMPLE CASES
Zoom
to
review
non-‐canonical
splice
site
warnings.
Although
these
may
not
always
have
to
be
corrected
(e.g
GC
donor),
they
should
be
flagged
with
the
appropriate
comment.](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-76-320.jpg)






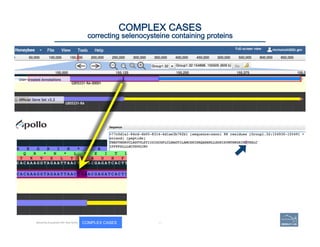



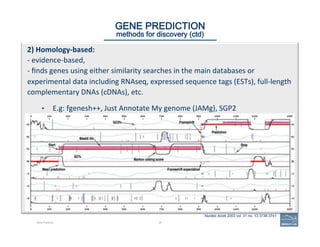
![1. Can
you
add
UTRs
(e.g.:
via
RNA-‐Seq)?
2. Check
exon
structures
3. Check
splice
sites:
most
splice
sites
display
these
residues
…]5’-‐GT/AG-‐3’[…
4. Check
‘Start’
and
‘Stop’
sites
5. Check
the
predicted
protein
product(s)
– Align
it
against
relevant
genes/gene
family.
– blastp
against
NCBI’s
RefSeq
or
nr
6. If
the
protein
product
s(ll
does
not
look
correct
then
check:
– Are
there
gaps
in
the
genome?
– Merge
of
2
gene
predic(ons
on
the
same
scaffold
– Merge
of
2
gene
predic(ons
from
different
scaffolds
– Split
a
gene
predic(on
– FrameshiYs
– error
in
the
genome
assembly?
– Selenocysteines,
single-‐base
errors,
etc
87 | 87
7. Finalize
annota(on
by
adding:
– Important
project
informa(on
in
the
form
of
comments
– IDs
from
public
databases
e.g.
GenBank
(via
DBXRef),
gene
symbol(s),
common
name(s),
synonyms,
top
BLAST
hits,
orthologs
with
species
names,
and
everything
else
you
can
think
of,
because
you
are
the
expert.
– Whether
your
model
replaces
one
or
more
models
from
the
official
gene
set
(so
it
can
be
deleted).
– The
kinds
of
changes
you
made
to
the
gene
model
of
interest,
if
any.
– Any
appropriate
func(onal
assignments
of
interest
to
the
community
(e.g.
via
BLAST,
RNA-‐Seq
data,
literature
searches,
etc.)
THE CHECKLIST
for accuracy and integrity
MANUAL ANNOTATION CHECKLIST](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-87-320.jpg)









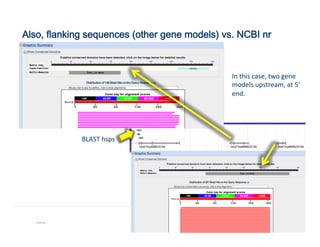

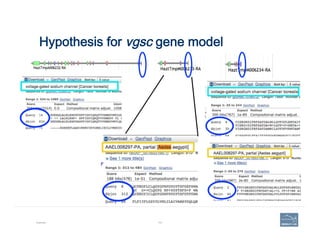




![Finished model
Example 108
Corroborate
integrity
and
accuracy
of
the
model:
-‐
Start
and
Stop
-‐
Exon
structure
and
splice
sites
…]5’-‐GT/AG-‐3’[…
-‐
Check
the
predicted
protein
product
vs.
NCBI
nr](https://image.slidesharecdn.com/riazvglkrx6rihgz2nlk-signature-ca551c7e3f3b04cd5b83963ad591c75c5d4284c4e320a4bdb0e64db92f8f4c23-poli-150921190618-lva1-app6891/85/Apolo-Taller-en-BIOS-108-320.jpg)











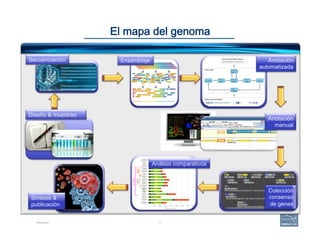
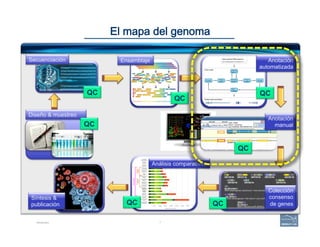
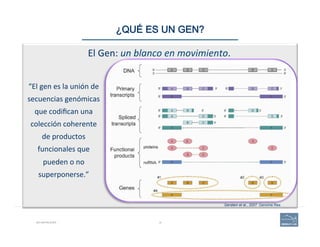
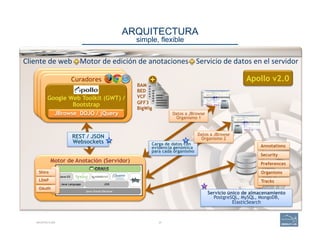
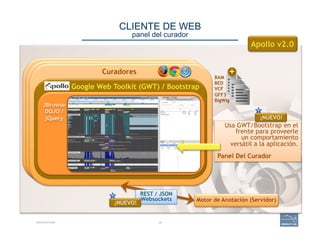
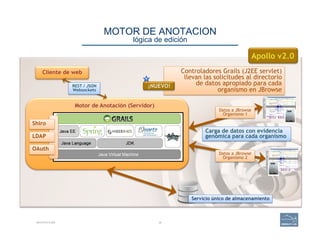
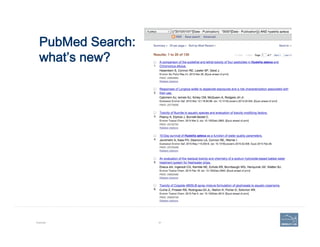
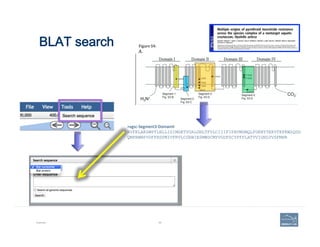
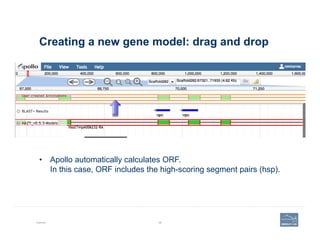
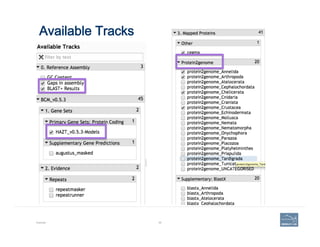
This document provides an overview of a talk on genome curation and manual annotation using the Apollo genome annotation tool. The talk aims to help scientists understand the genome curation process from assembled genome to automated and manual annotation. It will introduce Apollo and teach how to identify homologs of known genes, corroborate and modify automated gene models using evidence in Apollo. The talk will also refresh attendees on key biological concepts like the definition of a gene, central dogma, transcription, and translation to better understand manual annotation.





































































![Polymer [ बहुलक ] Chemistry Notes PDF - Irfanullah Mehar - JJ Sir Chemistry.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/polymerchemistrynotespdf-irfanullahmehar-jjsirchemistry-260210172118-3f9b37f7-thumbnail.jpg?width=640&height=640&fit=bounds)


















