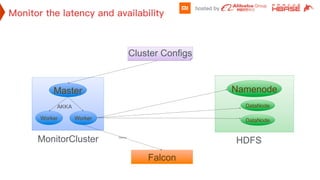
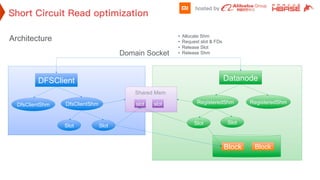
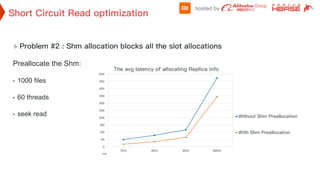
This document discusses optimizations made to HDFS for Hbase at XiaoMi. It addresses issues like shared memory allocation causing full GC in datanodes, listen drops on SSD clusters causing delays, peer cache bucket adjustment, and connection timeouts. Changes like preallocating shared memory, increasing socket backlog, reducing client and datanode timeouts, and adjusting the datanode dead node detection help improve performance and availability. The overall goal is to maintain local data, return fast responses from HDFS to Hbase, and reduce GC overhead from both systems.









![² Listen drop on SSD cluster causes 3s delay
15:56:14.506610 IP x.x.x.x.62393 > y.y.y.y.29402: Flags [S], seq 167786998, win 14600, options [mss 1460,sackOK,TS val
1590620938 ecr 0,nop,wscale 7], length 0<<<--------timeout on first try
15:56:17.506172 IP x.x.x.x.62393 > y.y.y.y.29402: Flags [S], seq 167786998, win 14600, options [mss 1460,sackOK,TS val
1590623938 ecr 0,nop,wscale 7], length 0<<<--------retry
15:56:17.506211 IP y.y.y.y.29402 > x.x.x.x.62393: Flags [S.], seq 4109047318, ack 167786999, win 14480, options [mss
1460,sackOK,TS val 1589839920 ecr 1590623938,nop,wscale 7], length 0
² HDFS-9669
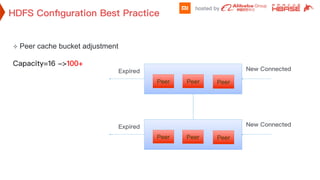
² After change backlog 128, 3s delays reduced to ~1/10 on Hbase SSD cluster
Somaxconn=128 Default Datanode backlog=50](https://image.slidesharecdn.com/track1-7hdfsoptimizationforhbaseatxiaomi-180830022108/85/HBaseConAsia2018-Track1-7-HDFS-optimizations-for-HBase-at-Xiaomi-13-320.jpg)
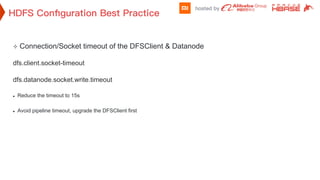

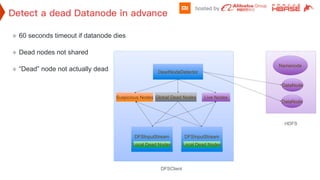
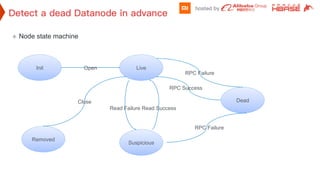








































































![How Big Brands are Taking Your Traffic in Alberta [Data Inside].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/howbigbrandsaretakingyourtrafficinalbertadatainside-260123180142-42d276f3-thumbnail.jpg?width=640&height=640&fit=bounds)



