Downloaded 126 times



















![© 2016 MapR Technologies 20
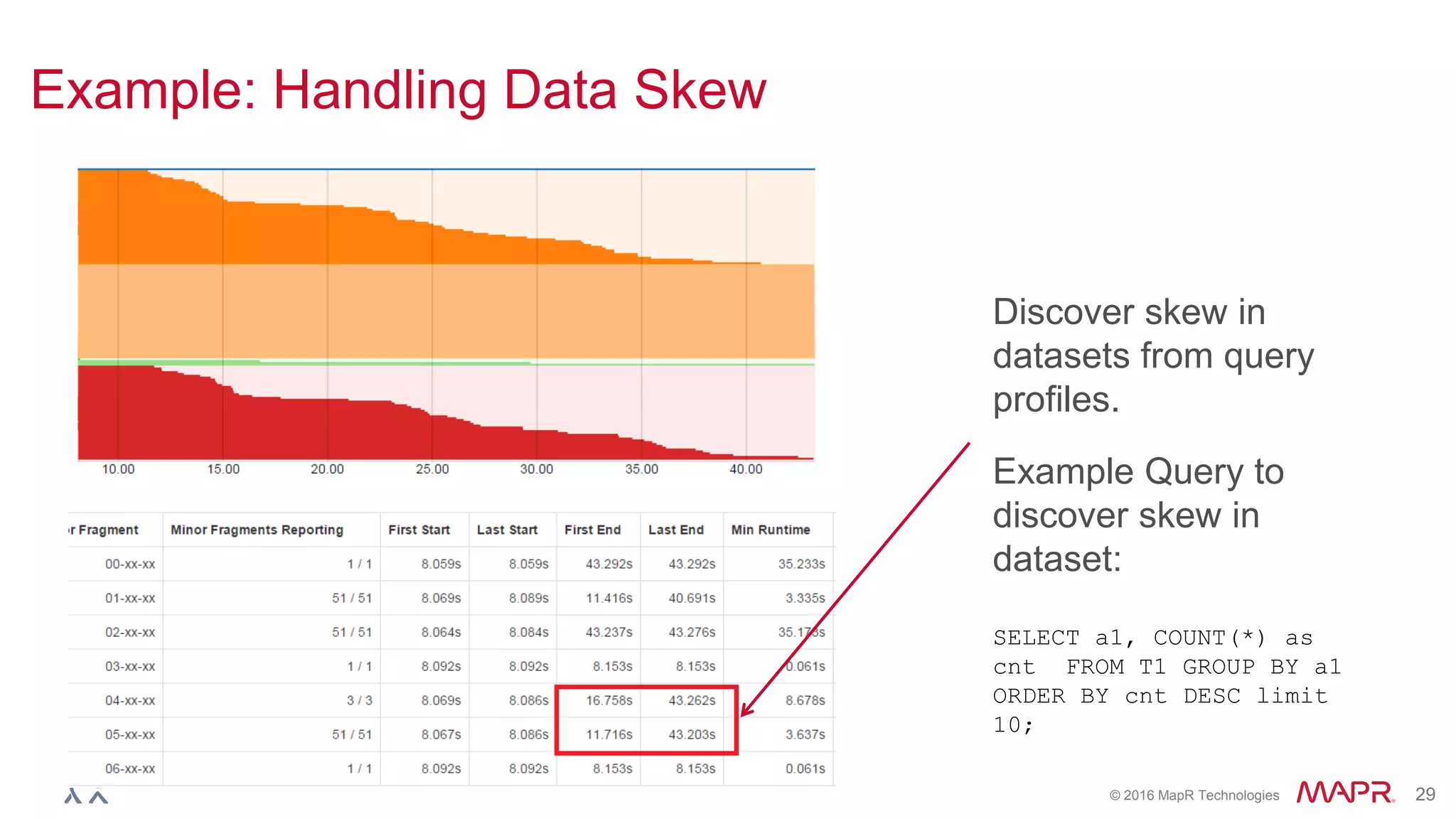
Run EXPLAIN PLAN to check if Partition Pruning is Applied
00-00 Screen : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0, cumulative cost = {40.5 rows,
145.5 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1005
00-01 Project(name=[$0], city=[$1], stars=[$2]) : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount
= 5.0, cumulative cost = {40.0 rows, 145.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1004
00-02 SelectionVectorRemover : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0,
cumulative cost = {40.0 rows, 145.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1003
00-03 Limit(fetch=[5]) : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0, cumulative
cost = {35.0 rows, 140.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1002
00-04 Project(name=[$3], city=[$1], stars=[$2]) : rowType = RecordType(ANY name, ANY city, ANY stars):
rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1001
00-05 Project(state=[$1], city=[$2], stars=[$3], name=[$0]) : rowType = RecordType(ANY state, ANY city,
ANY stars, ANY name): rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id
= 1000
00-06 Scan(groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath
[path=/tmp/businessparquet/0_0_114.parquet]], selectionRoot=file:/tmp/businessparquet, numFiles=1,
usedMetadataFile=false, columns=[`state`, `city`, `stars`, `name`]]]) : rowType = RecordType(ANY name, ANY state,
ANY city, ANY stars): rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id
= 999
Scan(groupscan=[ParquetGroupScan
[entries=[ReadEntryWithPath
[path=/tmp/businessparquet/0_0_114.parquet]],
selectionRoot=file:/tmp/businessparquet, numFiles=1,](https://image.slidesharecdn.com/drillwebinarjuly2016-presented-160728181655/75/Putting-Apache-Drill-into-Production-20-2048.jpg)

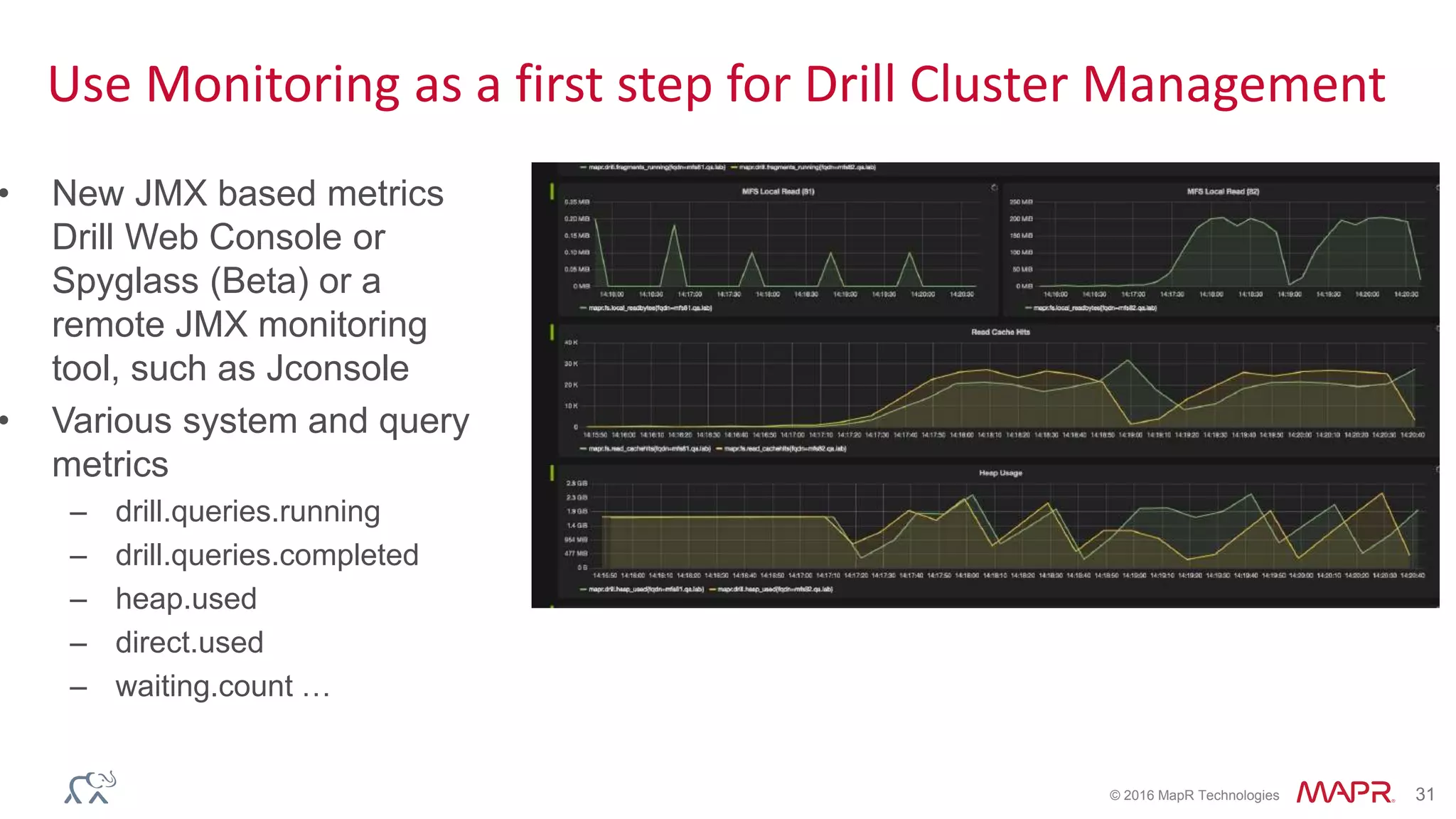
![© 2016 MapR Technologies 22
Run Explain Plan to Check if Metadata Cache is Used
00-00 Screen : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0, cumulative cost = {40.5
rows, 145.5 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1279
00-01 Project(name=[$0], city=[$1], stars=[$2]) : rowType = RecordType(ANY name, ANY city, ANY stars):
rowcount = 5.0, cumulative cost = {40.0 rows, 145.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1278
00-02 SelectionVectorRemover : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0,
cumulative cost = {40.0 rows, 145.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1277
00-03 Limit(fetch=[5]) : rowType = RecordType(ANY name, ANY city, ANY stars): rowcount = 5.0, cumulative
cost = {35.0 rows, 140.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1276
00-04 Project(name=[$3], city=[$1], stars=[$2]) : rowType = RecordType(ANY name, ANY city, ANY stars):
rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0 memory}, id = 1275
00-05 Project(state=[$1], city=[$2], stars=[$3], name=[$0]) : rowType = RecordType(ANY state, ANY
city, ANY stars, ANY name): rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0
memory}, id = 1274
00-06 Scan(groupscan=[ParquetGroupScan [entries=[ReadEntryWithPath
[path=/tmp/BusinessParquet/0_0_114.parquet]], selectionRoot=/tmp/BusinessParquet, numFiles=1,
usedMetadataFile=true, columns=[`state`, `city`, `stars`, `name`]]]) : rowType = RecordType(ANY name, ANY state,
ANY city, ANY stars): rowcount = 30.0, cumulative cost = {30.0 rows, 120.0 cpu, 0.0 io, 0.0 network, 0.0 memory},
id = 1273Scan(groupscan=[ParquetGroupScan
[entries=[ReadEntryWithPath
[path=/tmp/businessparquet/0_0_114.parquet]],
selectionRoot=file:/tmp/businessparquet, numFiles=1, ,
usedMetadataFile=true](https://image.slidesharecdn.com/drillwebinarjuly2016-presented-160728181655/75/Putting-Apache-Drill-into-Production-22-2048.jpg)
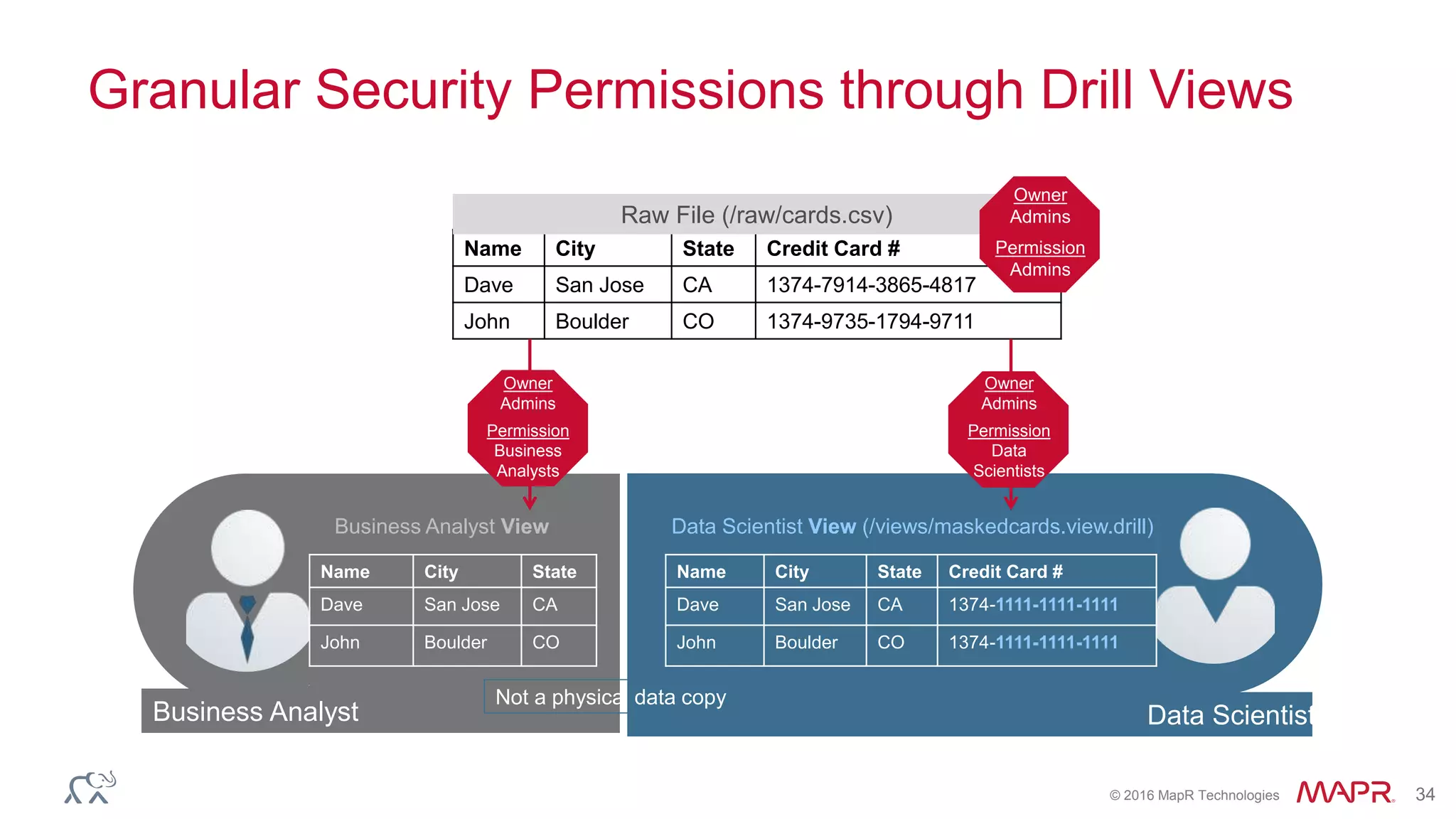
![© 2016 MapR Technologies 23
Create Data Sources & Schemas for Fast Metadata Queries by BI
Tools
• Metadata queries are very commonly
used by BI/Visualization tools
– INFORMATION_SCHEMA (Show Schemas,
Show tables..)
– Limit 0/1 queries
• Drill is a schema-less system , so
metadata queries at scale might need
careful consideration
• Drill provides optimized query paths to
provide fast schema returns wherever
possible
• User level Guidelines
– Disable unused Drill storage plugins
– Restrict schemas via IncludeSchemas &
ExcludeSchemas flags from ODBC/JDBC
connections
– Give Drill explicit schema information via views
– Enable metadata caching
CREATE or REPLACE VIEW
dfs.views.stock_quotes AS
SELECT CAST(columns[0] as VARCHAR(6))
as symbol,
CAST(columns[1] as VARCHAR(20)) as
`name`,
CAST((to_date(columns[2],
'MM/dd/yyyy')) as date) as `date`,
CAST(columns[3] as FLOAT) as
trade_price,
CAST(columns[4] as INT) as
trade_volume
from dfs.csv.`/stock_quotes`;
Sample view definition
with schemas](https://image.slidesharecdn.com/drillwebinarjuly2016-presented-160728181655/75/Putting-Apache-Drill-into-Production-23-2048.jpg)









The document provides an overview of Apache Drill, a schema-free SQL engine designed for flexibility and performance in data exploration and analytics. It discusses deployment considerations, best practices, and product evolution, emphasizing areas such as storage format selection, query performance optimization, and security. Additionally, it outlines various use cases and customer examples, showcasing Drill's ability to handle diverse data types and improve insights through agile development.




































































![[DSC Europe 25] Miodrag Pesovic & Vladislav Radonjic - Federated Data Archite...](https://cdn.slidesharecdn.com/ss_thumbnails/gsbe3y5it5uhndi4e08e-1-251212103249-f1008e0c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Jovan Bogicevic - Legacy to AI-Driven Defense: Transforming D...](https://cdn.slidesharecdn.com/ss_thumbnails/rsarluadt563hntyfc8q-3-251211083849-3e7bc4c0-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Kaja Kandare - LLM as a judge.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/arxyccaxsdsd1ba99wjw-7-251212104007-2b4e3f64-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dunja Adzic Jovanovic - AI and Cybersecurity: Defending Data ...](https://cdn.slidesharecdn.com/ss_thumbnails/o1zylpbhrtwnixxq2xj8-7-251211083048-185086f6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Branko Urosevic -Rethinking Financial Talent: Integrating Cod...](https://cdn.slidesharecdn.com/ss_thumbnails/8jjrus8ttko6qj64f58f-3-251212103250-642c6374-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dusan Nesic - Securing Tomorrow’s Infrastructure: Why Cyber-P...](https://cdn.slidesharecdn.com/ss_thumbnails/qikbszfftyowjm2q6duw-1-251211083848-8f2ead6b-thumbnail.jpg?width=640&height=640&fit=bounds)





