Download to read offline



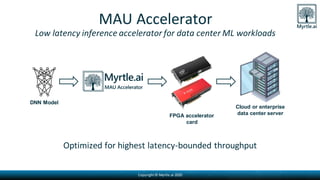




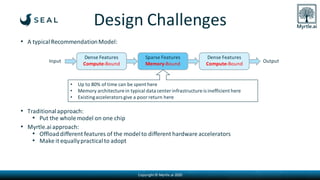

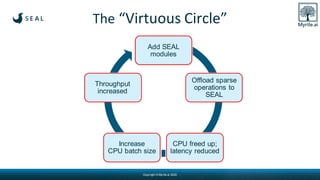


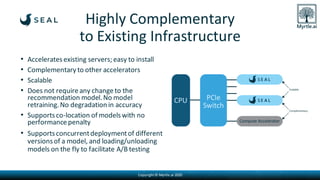



Myrtle.ai presents a low-latency accelerator optimized for recommendation models in data centers, significantly improving throughput and minimizing energy consumption while maintaining model accuracy. The accelerator targets various applications such as speech transcription, natural language processing, and anomaly detection across multiple sectors including finance and telecommunications. By offloading memory-bound operations, it offers rapid increases in performance with notable cost savings and environmental benefits, requiring no model retraining.























































































