Download as PDF, PPTX












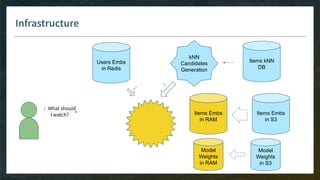
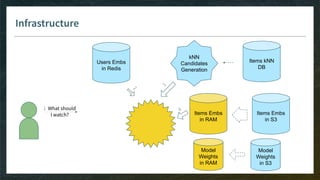
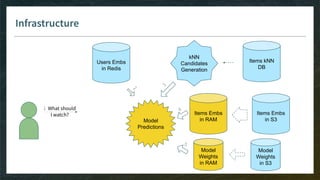
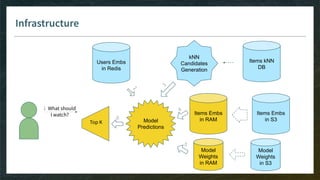
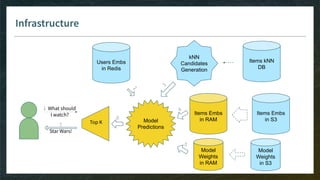
![Items Candidate Generation
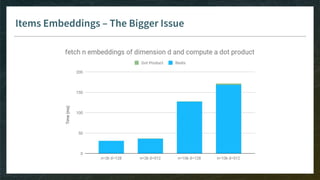
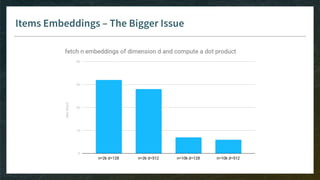
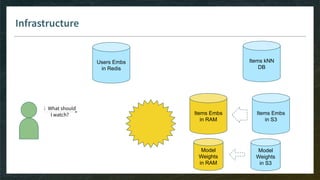
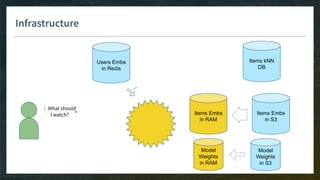
Goal: pre-select thousand(s) of items for your model, without need to see all embeddings
Model-Free
E.g. kNN item-item with pre-computed kNN tables
Easy with ML-ready DB like Spark
Do-able in ElasticSearch or even SQL
Model-Based
E.g. linear matrix factorization, then smart implementation of Top-K
Model has to be monotonic (w.r.t. items dimensions) otherwise you can’t rely on pre-computed index
Ref: ElasticSearch with word2vec embeddings http://bit.ly/2Wciike (WIP without efficient Top-K [issue#42326])](https://image.slidesharecdn.com/4-realtimedeployment-191030181611/85/Recommender-Systems-from-A-to-Z-Real-Time-Deployment-32-320.jpg)


























![Microservices and Kubernetes
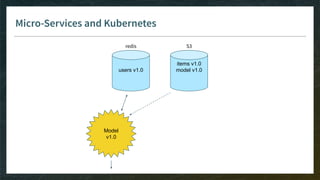
Microservices
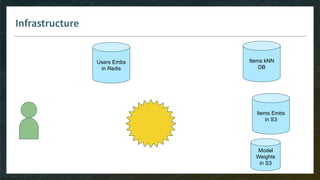
● All microservices must be safe to replicate/delete for scaling up/down to adjust for variable load
→ source of truth for data cannot be a microservice
→ has to be managed in the cloud
● Fine-tune liveness probes (and readiness probes) to allow slow init of containers
[new in Kubernetes 1.16: startup probes]](https://image.slidesharecdn.com/4-realtimedeployment-191030181611/85/Recommender-Systems-from-A-to-Z-Real-Time-Deployment-76-320.jpg)
![Microservices and Kubernetes
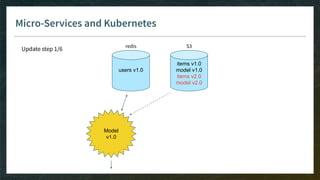
Microservices
● All microservices must be safe to replicate/delete for scaling up/down to adjust for variable load
→ source of truth for data cannot be a microservice
→ has to be managed in the cloud
● Fine-tune liveness probes (and readiness probes) to allow slow init of containers
[new in Kubernetes 1.16: startup probes]
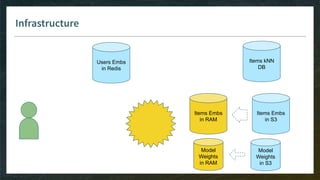
● Memory is expensive
→ split microservices in a way you can still share memory between workers and avoid duplication](https://image.slidesharecdn.com/4-realtimedeployment-191030181611/85/Recommender-Systems-from-A-to-Z-Real-Time-Deployment-77-320.jpg)
![Microservices and Kubernetes
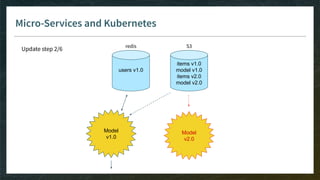
Microservices
● All microservices must be safe to replicate/delete for scaling up/down to adjust for variable load
→ source of truth for data cannot be a microservice
→ has to be managed in the cloud
● Fine-tune liveness probes (and readiness probes) to allow slow init of containers
[new in Kubernetes 1.16: startup probes]
● Memory is expensive
→ split microservices in a way you can still share memory between workers and avoid duplication
● Microservices for RecSys require lots of memory and compute
→ favor a few big nodes more than many small ones](https://image.slidesharecdn.com/4-realtimedeployment-191030181611/85/Recommender-Systems-from-A-to-Z-Real-Time-Deployment-78-320.jpg)

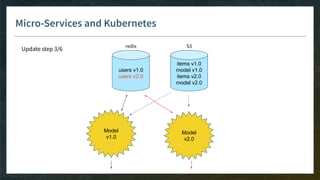
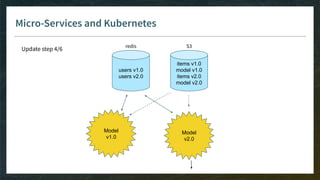
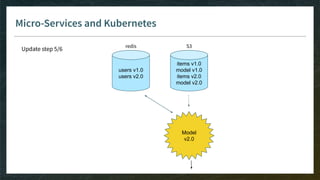
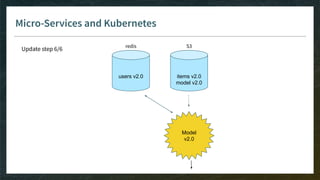






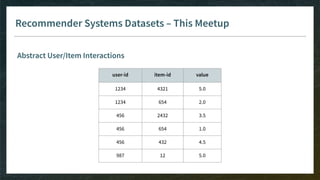
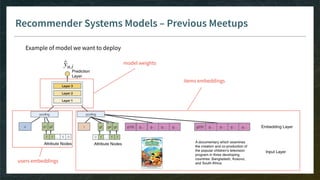
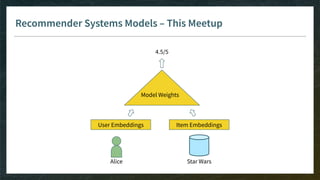
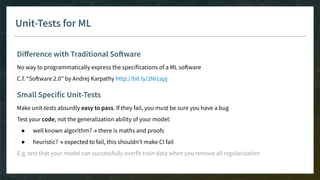
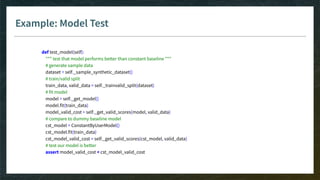
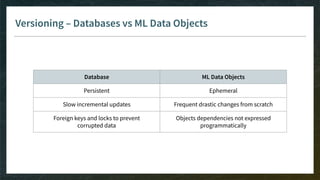
The document outlines the comprehensive process of developing recommender systems, covering dataset selection, model training, evaluation, and real-time deployment. It emphasizes the importance of cloud infrastructure for scalability and updates, while addressing technical challenges related to data management, user interactions, and model weights. Additionally, it discusses testing and CI/CD practices tailored for machine learning projects, alongside strategies for versioning and handling dependencies.



































































