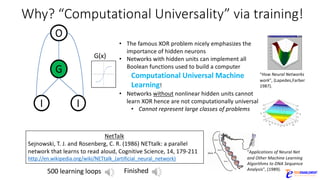
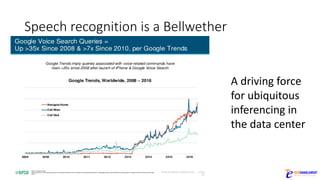
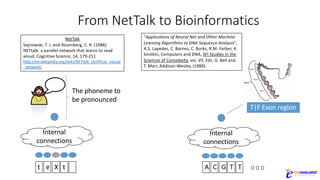
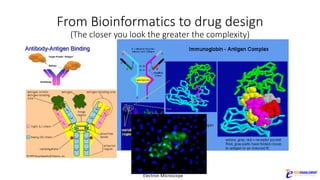
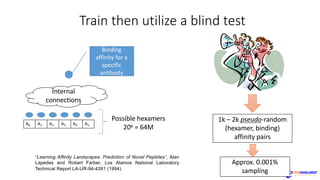
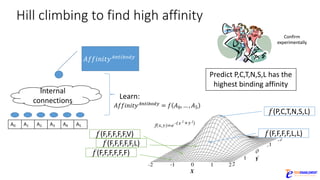
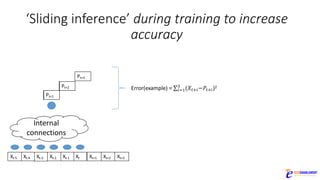
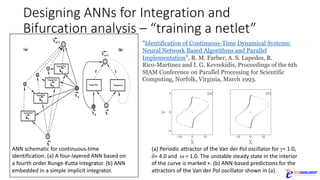
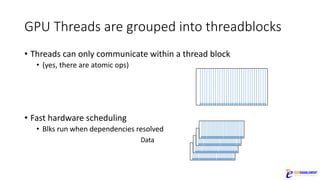
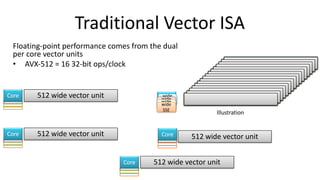
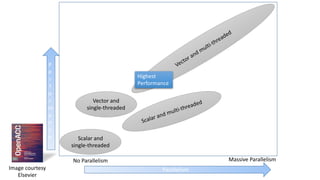
The document discusses the rapid evolution of AI technology, particularly focusing on its growing presence in server workloads by 2020, driven by advancements in machine learning and deep learning techniques. Key insights from industry leaders highlight the transformative potential of AI in various applications, such as speech recognition and robotics, predicting significant increases in data volume and corresponding economic value. It also examines the necessity for robust computational hardware and software frameworks to support the expansive adoption of AI technologies in data centers.




















![SPEC M3 Benchmark on 68 TB CAPI system
• Fastest mean response times and most consistent response times (lowest
standard deviation) ever reported, for all combinations of query type, data
volume, and concurrent users.
• Each mean response time was 5.5x to 212x the previous best result,
including:
• 21x to 212x the performance of the previous best published result for the market
snap benchmarks (10T.YR[n]-MKTSNAP.TIME) *
• 21x the performance of the previous best published result for year high bid in the
smallest year of the dataset (1T.OLDYRHIBID.TIME) *
• 8-10x the performance of the previous best published result for the 100-user
volume-weighted average bid benchmarks (100T.YR[n]VWAB-12D-HO.TIME) **
• 5-8x the performance of the previous best published result for the N-year high-bid
benchmarks (1T.[n]YRHIBID.TIME)](https://image.slidesharecdn.com/farber-keynote06-14-17-170614161824/85/Understanding-why-Artificial-Intelligence-will-become-the-most-prevalent-server-workload-by-2020-37-320.jpg)


![TrueNorth: Accuracy
• PNAS paper: “[We] demonstrate that neuromorphic
computing … can implement deep convolution networks
that approach state-of-the-art classification accuracy
across eight standard datasets encompassing vision and
speech, perform inference while preserving the hardware’s
underlying energy-efficiency and high throughput.”
Accuracy of different sized networks running on
one or more TrueNorth chips to perform
inference on eight datasets. For comparison,
accuracy of state-of-the-art unconstrained
approaches are shown as bold horizontal lines
(hardware resources used for these networks are
not indicated).](https://image.slidesharecdn.com/farber-keynote06-14-17-170614161824/85/Understanding-why-Artificial-Intelligence-will-become-the-most-prevalent-server-workload-by-2020-41-320.jpg)













![[DSC 2016] 系列活動:李宏毅 / 一天搞懂深度學習](https://cdn.slidesharecdn.com/ss_thumbnails/1-160521014039-thumbnail.jpg?width=640&height=640&fit=bounds)
![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)















































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)


