Download as PDF, PPTX



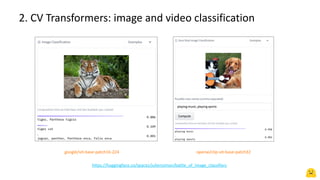

![State-of-the-art prediction with 2 lines of Python
[{'score': 0.9985879063606262, 'label': 'motorcycle',
'box': {'xmin': 240, 'ymin': 185, 'xmax': 890, 'ymax': 593}},
{'score': 0.9886626601219177, 'label': 'backpack',
'box': {'xmin': 453, 'ymin': 87, 'xmax': 570, 'ymax': 220}},
{'score': 0.9997599720954895, 'label': 'person',
'box': {'xmin': 456, 'ymin': 28, 'xmax': 684, 'ymax': 551}}]](https://image.slidesharecdn.com/hfcv-230114064453-fab47cfa/85/An-introduction-to-computer-vision-with-Hugging-Face-11-320.jpg)

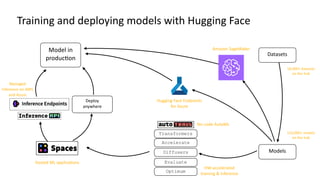


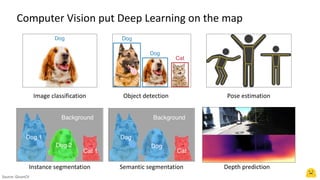
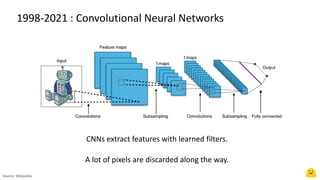
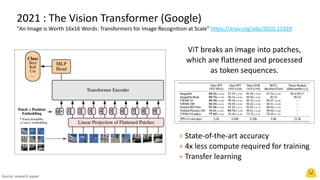
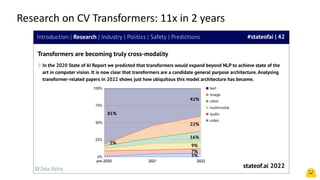
The document provides an introduction to computer vision using Hugging Face, highlighting advancements such as convolutional neural networks and vision transformers that improve accuracy and reduce compute needs. It discusses various models available on the Hugging Face hub for tasks like image classification, detection, and segmentation, as well as generative models for text-to-image applications. Additionally, it mentions the features of deploying models and resources available for getting started with machine learning projects.























































































